 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Named Entity Modeling from Embedding Distribution
Paper and Code
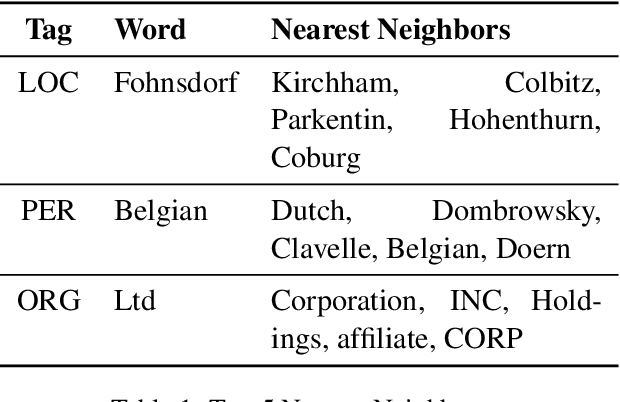
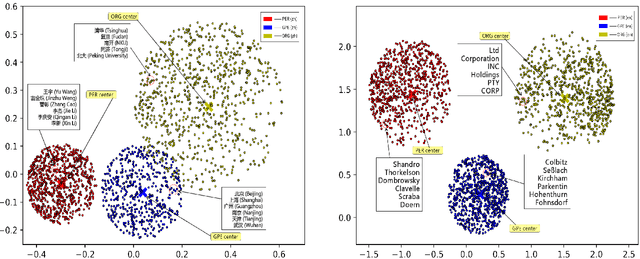
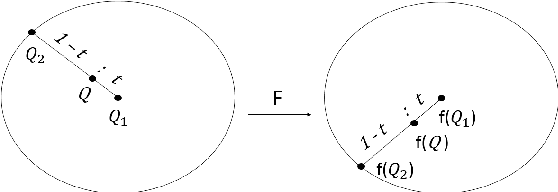

In this paper, we report our discovery on named entity distribution in general word embedding space, which helps an open definition on multilingual named entity definition rather than previous closed and constraint definition on named entities through a named entity dictionary, which is usually derived from huaman labor and replies on schedual update. Our initial visualization of monolingual word embeddings indicates named entities tend to gather together despite of named entity types and language difference, which enable us to model all named entities using a specific geometric structure inside embedding space,namely, the named entity hypersphere. For monolingual case, the proposed named entity model gives an open description on diverse named entity types and different languages. For cross-lingual case, mapping the proposed named entity model provides a novel way to build named entity dataset for resource-poor languages. At last, the proposed named entity model may be shown as a very useful clue to significantly enhance state-of-the-art named entity recognition systems generally.