 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Contextualized Representation for Named Entity Recognition
Nov 19, 2019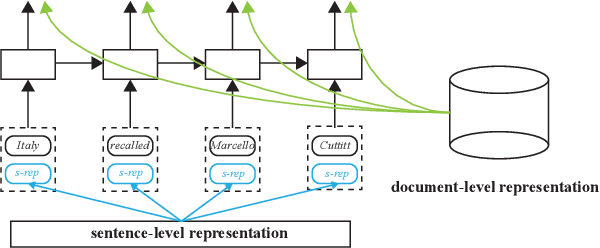

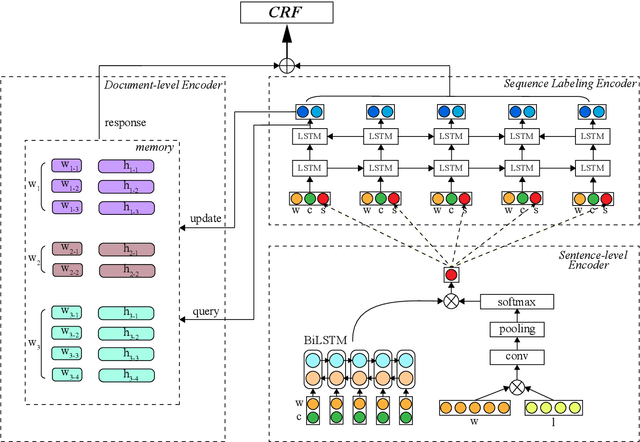
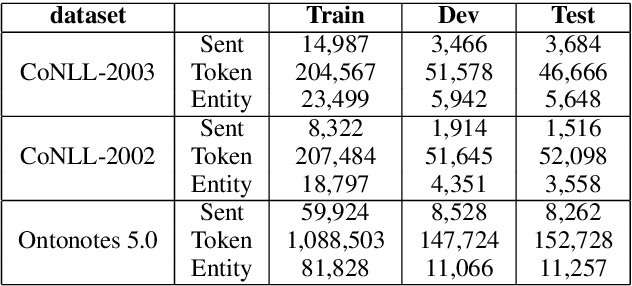
Named entity recognition (NER) models are typically based on the architecture of Bi-directional LSTM (BiLSTM). The constraints of sequential nature and the modeling of single input prevent the full utilization of global information from larger scope, not only in the entire sentence, but also in the entire document (dataset). In this paper, we address these two deficiencies and propose a model augmented with hierarchical contextualized representation: sentence-level representation and document-level representation. In sentence-level, we take different contributions of words in a single sentence into consideration to enhance the sentence representation learned from an independent BiLSTM via label embedding attention mechanism. In document-level, the key-value memory network is adopted to record the document-aware information for each unique word which is sensitive to similarity of context information. Our two-level hierarchical contextualized representations are fused with each input token embedding and corresponding hidden state of BiLSTM, respectively. The experimental results on three benchmark NER datasets (CoNLL-2003 and Ontonotes 5.0 English datasets, CoNLL-2002 Spanish dataset) show that we establish new state-of-the-art results.
Dual Skew Divergence Loss for Neural Machine Translation
Aug 22, 2019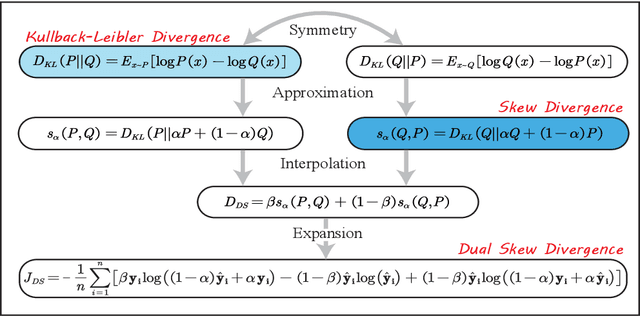
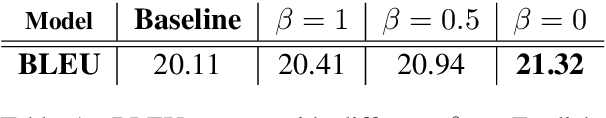
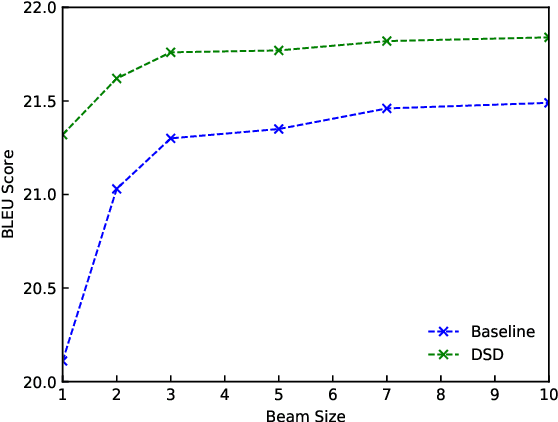
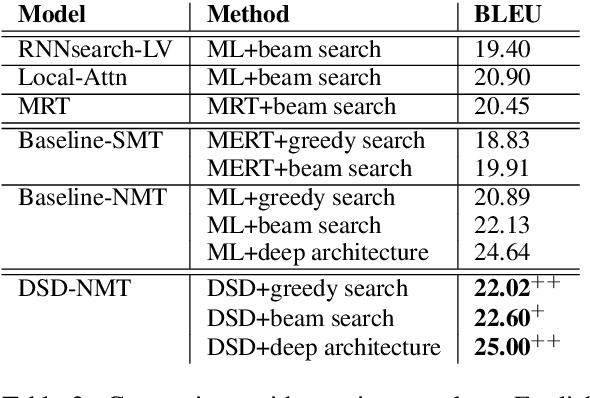
For neural sequence model training, maximum likelihood (ML) has been commonly adopted to optimize model parameters with respect to the corresponding objective. However, in the case of sequence prediction tasks like neural machine translation (NMT), training with the ML-based cross entropy loss would often lead to models that overgeneralize and plunge into local optima. In this paper, we propose an extended loss function called dual skew divergence (DSD), which aims to give a better tradeoff between generalization ability and error avoidance during NMT training. Our empirical study indicates that switching to DSD loss after the convergence of ML training helps the model skip the local optimum and stimulates a stable performance improvement. The evaluations on WMT 2014 English-German and English-French translation tasks demonstrate that the proposed loss indeed helps bring about better translation performance than several baselines.
Lattice-Based Transformer Encoder for Neural Machine Translation
Jun 04, 2019


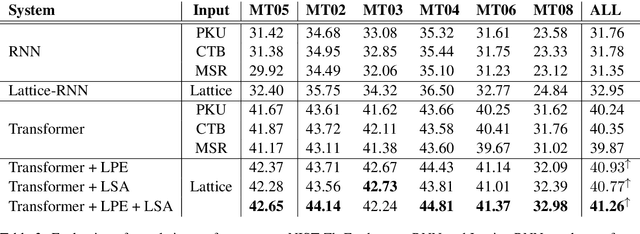
Neural machine translation (NMT) takes deterministic sequences for source representations. However, either word-level or subword-level segmentations have multiple choices to split a source sequence with different word segmentors or different subword vocabulary sizes. We hypothesize that the diversity in segmentations may affect the NMT performance. To integrate different segmentations with the state-of-the-art NMT model, Transformer, we propose lattice-based encoders to explore effective word or subword representation in an automatic way during training. We propose two methods: 1) lattice positional encoding and 2) lattice-aware self-attention. These two methods can be used together and show complementary to each other to further improve translation performance. Experiment results show superiorities of lattice-based encoders in word-level and subword-level representations over conventional Transformer encoder.