 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Contextualized Representation for Named Entity Recognition
Paper and Code
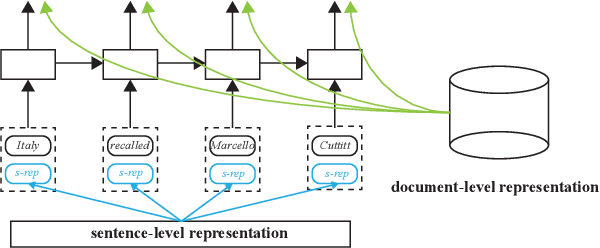

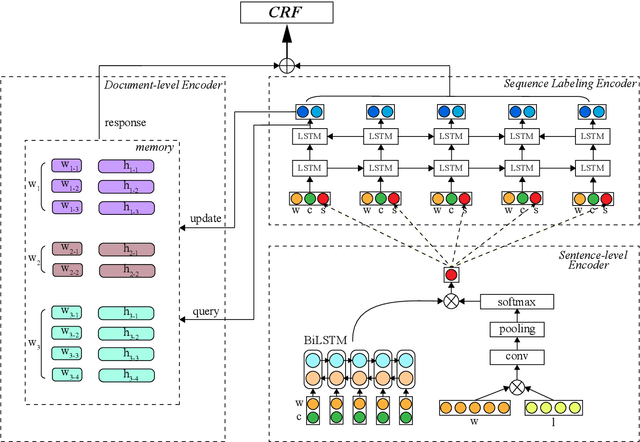
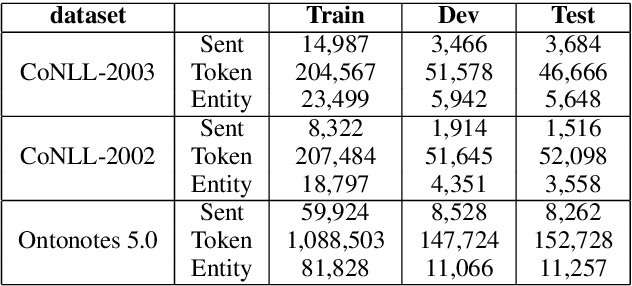
Named entity recognition (NER) models are typically based on the architecture of Bi-directional LSTM (BiLSTM). The constraints of sequential nature and the modeling of single input prevent the full utilization of global information from larger scope, not only in the entire sentence, but also in the entire document (dataset). In this paper, we address these two deficiencies and propose a model augmented with hierarchical contextualized representation: sentence-level representation and document-level representation. In sentence-level, we take different contributions of words in a single sentence into consideration to enhance the sentence representation learned from an independent BiLSTM via label embedding attention mechanism. In document-level, the key-value memory network is adopted to record the document-aware information for each unique word which is sensitive to similarity of context information. Our two-level hierarchical contextualized representations are fused with each input token embedding and corresponding hidden state of BiLSTM, respectively. The experimental results on three benchmark NER datasets (CoNLL-2003 and Ontonotes 5.0 English datasets, CoNLL-2002 Spanish dataset) show that we establish new state-of-the-art results.