 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Post-training Quantization with FP8 Formats
Sep 26, 2023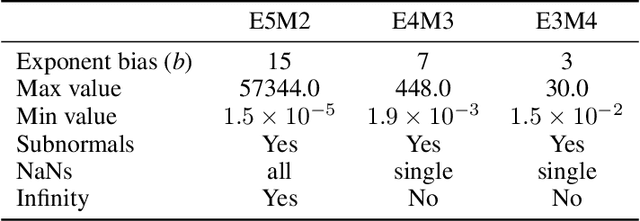

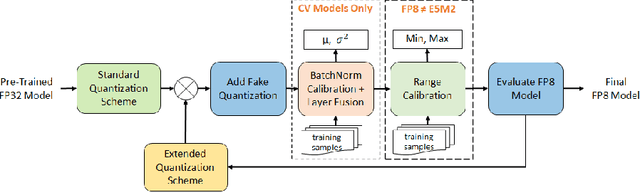
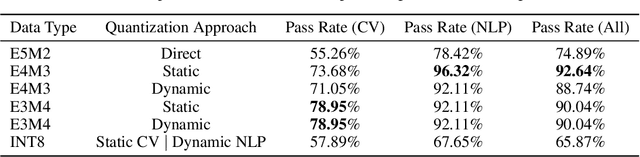
Recent advances in deep learning methods such as LLMs and Diffusion models have created a need for improved quantization methods that can meet the computational demands of these modern architectures while maintaining accuracy. Towards this goal, we study the advantages of FP8 data formats for post-training quantization across 75 unique network architectures covering a wide range of tasks, including machine translation, language modeling, text generation, image classification, generation, and segmentation. We examine three different FP8 representations (E5M2, E4M3, and E3M4) to study the effects of varying degrees of trade-off between dynamic range and precision on model accuracy. Based on our extensive study, we developed a quantization workflow that generalizes across different network architectures. Our empirical results show that FP8 formats outperform INT8 in multiple aspects, including workload coverage (92.64% vs. 65.87%), model accuracy and suitability for a broader range of operations. Furthermore, our findings suggest that E4M3 is better suited for NLP models, whereas E3M4 performs marginally better than E4M3 on computer vision tasks. The code is publicly available on Intel Neural Compressor: https://github.com/intel/neural-compressor.
An Efficient Sparse Inference Software Accelerator for Transformer-based Language Models on CPUs
Jun 28, 2023



In recent years, Transformer-based language models have become the standard approach for natural language processing tasks. However, stringent throughput and latency requirements in industrial applications are limiting their adoption. To mitigate the gap, model compression techniques such as structured pruning are being used to improve inference efficiency. However, most existing neural network inference runtimes lack adequate support for structured sparsity. In this paper, we propose an efficient sparse deep learning inference software stack for Transformer-based language models where the weights are pruned with constant block size. Our sparse software accelerator leverages Intel Deep Learning Boost to maximize the performance of sparse matrix - dense matrix multiplication (commonly abbreviated as SpMM) on CPUs. Our SpMM kernel outperforms the existing sparse libraries (oneMKL, TVM, and LIBXSMM) by an order of magnitude on a wide range of GEMM shapes under 5 representative sparsity ratios (70%, 75%, 80%, 85%, 90%). Moreover, our SpMM kernel shows up to 5x speedup over dense GEMM kernel of oneDNN, a well-optimized dense library widely used in industry. We apply our sparse accelerator on widely-used Transformer-based language models including Bert-Mini, DistilBERT, Bert-Base, and BERT-Large. Our sparse inference software shows up to 1.5x speedup over Neural Magic's Deepsparse under same configurations on Xeon on Amazon Web Services under proxy production latency constraints. We also compare our solution with two framework-based inference solutions, ONNX Runtime and PyTorch, and demonstrate up to 37x speedup over ONNX Runtime and 345x over PyTorch on Xeon under the latency constraints. All the source code is publicly available on Github: https://github.com/intel/intel-extension-for-transformers.