 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastDraft: How to Train Your Draft
Nov 17, 2024



Speculative Decoding has gained popularity as an effective technique for accelerating the auto-regressive inference process of Large Language Models (LLMs). However, Speculative Decoding entirely relies on the availability of efficient draft models, which are often lacking for many existing language models due to a stringent constraint of vocabulary incompatibility. In this work we introduce FastDraft, a novel and efficient approach for pre-training and aligning a draft model to any large language model by incorporating efficient pre-training, followed by fine-tuning over synthetic datasets generated by the target model. We demonstrate FastDraft by training two highly parameter efficient drafts for the popular Phi-3-mini and Llama-3.1-8B models. Using FastDraft, we were able to produce a draft with approximately 10 billion tokens on a single server with 8 Intel$^\circledR$ Gaudi$^\circledR$ 2 accelerators in under 24 hours. Our results show that the draft model achieves impressive results in key metrics of acceptance rate, block efficiency and up to 3x memory bound speed up when evaluated on code completion and up to 2x in summarization, text completion and instruction tasks. We validate our theoretical findings through benchmarking on the latest Intel$^\circledR$ Core$^{\tiny \text{TM}}$ Ultra, achieving a wall-clock time speedup of up to 2x, indicating a significant reduction in runtime. Due to its high quality, FastDraft unlocks large language models inference on AI-PC and other edge-devices.
An Efficient Sparse Inference Software Accelerator for Transformer-based Language Models on CPUs
Jun 28, 2023



In recent years, Transformer-based language models have become the standard approach for natural language processing tasks. However, stringent throughput and latency requirements in industrial applications are limiting their adoption. To mitigate the gap, model compression techniques such as structured pruning are being used to improve inference efficiency. However, most existing neural network inference runtimes lack adequate support for structured sparsity. In this paper, we propose an efficient sparse deep learning inference software stack for Transformer-based language models where the weights are pruned with constant block size. Our sparse software accelerator leverages Intel Deep Learning Boost to maximize the performance of sparse matrix - dense matrix multiplication (commonly abbreviated as SpMM) on CPUs. Our SpMM kernel outperforms the existing sparse libraries (oneMKL, TVM, and LIBXSMM) by an order of magnitude on a wide range of GEMM shapes under 5 representative sparsity ratios (70%, 75%, 80%, 85%, 90%). Moreover, our SpMM kernel shows up to 5x speedup over dense GEMM kernel of oneDNN, a well-optimized dense library widely used in industry. We apply our sparse accelerator on widely-used Transformer-based language models including Bert-Mini, DistilBERT, Bert-Base, and BERT-Large. Our sparse inference software shows up to 1.5x speedup over Neural Magic's Deepsparse under same configurations on Xeon on Amazon Web Services under proxy production latency constraints. We also compare our solution with two framework-based inference solutions, ONNX Runtime and PyTorch, and demonstrate up to 37x speedup over ONNX Runtime and 345x over PyTorch on Xeon under the latency constraints. All the source code is publicly available on Github: https://github.com/intel/intel-extension-for-transformers.
Fast DistilBERT on CPUs
Oct 27, 2022Transformer-based language models have become the standard approach to solving natural language processing tasks. However, industry adoption usually requires the maximum throughput to comply with certain latency constraints that prevents Transformer models from being used in production. To address this gap, model compression techniques such as quantization and pruning may be used to improve inference efficiency. However, these compression techniques require specialized software to apply and deploy at scale. In this work, we propose a new pipeline for creating and running Fast Transformer models on CPUs, utilizing hardware-aware pruning, knowledge distillation, quantization, and our own Transformer inference runtime engine with optimized kernels for sparse and quantized operators. We demonstrate the efficiency of our pipeline by creating a Fast DistilBERT model showing minimal accuracy loss on the question-answering SQuADv1.1 benchmark, and throughput results under typical production constraints and environments. Our results outperform existing state-of-the-art Neural Magic's DeepSparse runtime performance by up to 50% and up to 4.1x performance speedup over ONNX Runtime.
Prune Once for All: Sparse Pre-Trained Language Models
Nov 10, 2021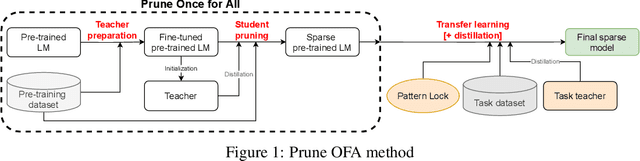
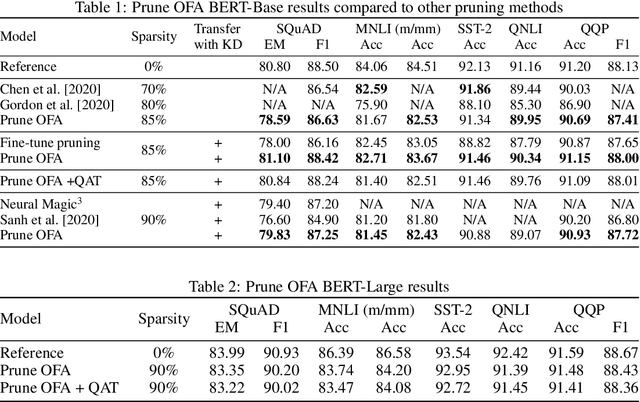
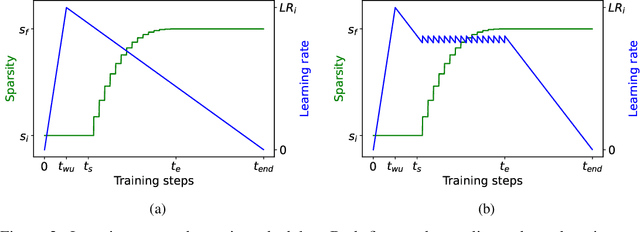
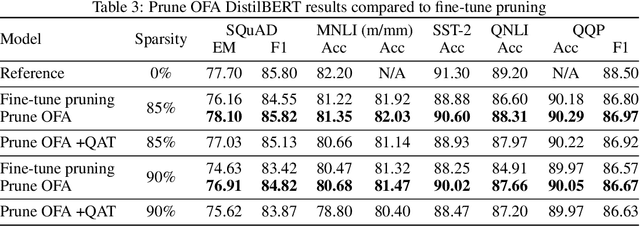
Transformer-based language models are applied to a wide range of applications in natural language processing. However, they are inefficient and difficult to deploy. In recent years, many compression algorithms have been proposed to increase the implementation efficiency of large Transformer-based models on target hardware. In this work we present a new method for training sparse pre-trained Transformer language models by integrating weight pruning and model distillation. These sparse pre-trained models can be used to transfer learning for a wide range of tasks while maintaining their sparsity pattern. We demonstrate our method with three known architectures to create sparse pre-trained BERT-Base, BERT-Large and DistilBERT. We show how the compressed sparse pre-trained models we trained transfer their knowledge to five different downstream natural language tasks with minimal accuracy loss. Moreover, we show how to further compress the sparse models' weights to 8bit precision using quantization-aware training. For example, with our sparse pre-trained BERT-Large fine-tuned on SQuADv1.1 and quantized to 8bit we achieve a compression ratio of $40$X for the encoder with less than $1\%$ accuracy loss. To the best of our knowledge, our results show the best compression-to-accuracy ratio for BERT-Base, BERT-Large, and DistilBERT.
Q8BERT: Quantized 8Bit BERT
Oct 17, 2019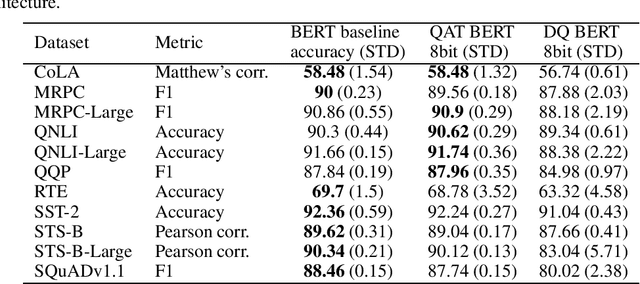

Recently, pre-trained Transformer based language models such as BERT and GPT, have shown great improvement in many Natural Language Processing (NLP) tasks. However, these models contain a large amount of parameters. The emergence of even larger and more accurate models such as GPT2 and Megatron, suggest a trend of large pre-trained Transformer models. However, using these large models in production environments is a complex task requiring a large amount of compute, memory and power resources. In this work we show how to perform quantization-aware training during the fine-tuning phase of BERT in order to compress BERT by $4\times$ with minimal accuracy loss. Furthermore, the produced quantized model can accelerate inference speed if it is optimized for 8bit Integer supporting hardware.