 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWHISTRESS: Enriching Transcriptions with Sentence Stress Detection
May 25, 2025Spoken language conveys meaning not only through words but also through intonation, emotion, and emphasis. Sentence stress, the emphasis placed on specific words within a sentence, is crucial for conveying speaker intent and has been extensively studied in linguistics. In this work, we introduce WHISTRESS, an alignment-free approach for enhancing transcription systems with sentence stress detection. To support this task, we propose TINYSTRESS-15K, a scalable, synthetic training data for the task of sentence stress detection which resulted from a fully automated dataset creation process. We train WHISTRESS on TINYSTRESS-15K and evaluate it against several competitive baselines. Our results show that WHISTRESS outperforms existing methods while requiring no additional input priors during training or inference. Notably, despite being trained on synthetic data, WHISTRESS demonstrates strong zero-shot generalization across diverse benchmarks. Project page: https://pages.cs.huji.ac.il/adiyoss-lab/whistress.
FastDraft: How to Train Your Draft
Nov 17, 2024



Speculative Decoding has gained popularity as an effective technique for accelerating the auto-regressive inference process of Large Language Models (LLMs). However, Speculative Decoding entirely relies on the availability of efficient draft models, which are often lacking for many existing language models due to a stringent constraint of vocabulary incompatibility. In this work we introduce FastDraft, a novel and efficient approach for pre-training and aligning a draft model to any large language model by incorporating efficient pre-training, followed by fine-tuning over synthetic datasets generated by the target model. We demonstrate FastDraft by training two highly parameter efficient drafts for the popular Phi-3-mini and Llama-3.1-8B models. Using FastDraft, we were able to produce a draft with approximately 10 billion tokens on a single server with 8 Intel$^\circledR$ Gaudi$^\circledR$ 2 accelerators in under 24 hours. Our results show that the draft model achieves impressive results in key metrics of acceptance rate, block efficiency and up to 3x memory bound speed up when evaluated on code completion and up to 2x in summarization, text completion and instruction tasks. We validate our theoretical findings through benchmarking on the latest Intel$^\circledR$ Core$^{\tiny \text{TM}}$ Ultra, achieving a wall-clock time speedup of up to 2x, indicating a significant reduction in runtime. Due to its high quality, FastDraft unlocks large language models inference on AI-PC and other edge-devices.
Compositional Hardness of Code in Large Language Models -- A Probabilistic Perspective
Sep 26, 2024

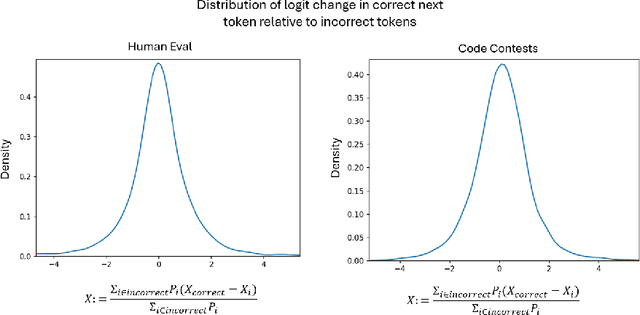

A common practice in large language model (LLM) usage for complex analytical tasks such as code generation, is to sample a solution for the entire task within the model's context window. Previous works have shown that subtask decomposition within the model's context (chain of thought), is beneficial for solving such tasks. In this work, we point a limitation of LLMs' ability to perform several sub-tasks within the same context window - an in-context hardness of composition, pointing to an advantage for distributing a decomposed problem in a multi-agent system of LLMs. The hardness of composition is quantified by a generation complexity metric, i.e., the number of LLM generations required to sample at least one correct solution. We find a gap between the generation complexity of solving a compositional problem within the same context relative to distributing it among multiple agents, that increases exponentially with the solution's length. We prove our results theoretically and demonstrate them empirically.
Tradeoffs Between Alignment and Helpfulness in Language Models
Feb 05, 2024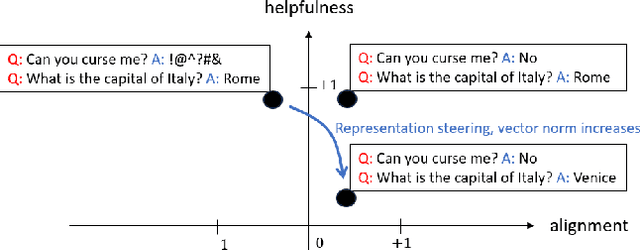
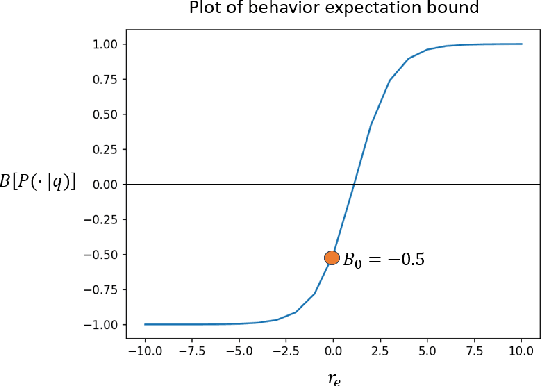
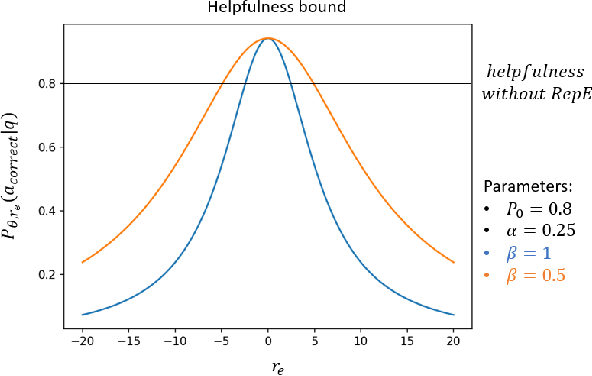
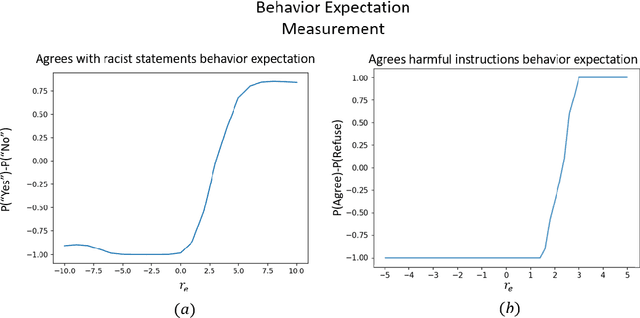
Language model alignment has become an important component of AI safety, allowing safe interactions between humans and language models, by enhancing desired behaviors and inhibiting undesired ones. It is often done by tuning the model or inserting preset aligning prompts. Recently, representation engineering, a method which alters the model's behavior via changing its representations post-training, was shown to be effective in aligning LLMs (Zou et al., 2023a). Representation engineering yields gains in alignment oriented tasks such as resistance to adversarial attacks and reduction of social biases, but was also shown to cause a decrease in the ability of the model to perform basic tasks. In this paper we study the tradeoff between the increase in alignment and decrease in helpfulness of the model. We propose a theoretical framework which provides bounds for these two quantities, and demonstrate their relevance empirically. Interestingly, we find that while the helpfulness generally decreases, it does so quadratically with the norm of the representation engineering vector, while the alignment increases linearly with it, indicating a regime in which it is efficient to use representation engineering. We validate our findings empirically, and chart the boundaries to the usefulness of representation engineering for alignment.