 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient LLM Inference on CPUs
Nov 01, 2023



Large language models (LLMs) have demonstrated remarkable performance and tremendous potential across a wide range of tasks. However, deploying these models has been challenging due to the astronomical amount of model parameters, which requires a demand for large memory capacity and high memory bandwidth. In this paper, we propose an effective approach that can make the deployment of LLMs more efficiently. We support an automatic INT4 weight-only quantization flow and design a special LLM runtime with highly-optimized kernels to accelerate the LLM inference on CPUs. We demonstrate the general applicability of our approach on popular LLMs including Llama2, Llama, GPT-NeoX, and showcase the extreme inference efficiency on CPUs. The code is publicly available at: https://github.com/intel/intel-extension-for-transformers.
TEQ: Trainable Equivalent Transformation for Quantization of LLMs
Oct 17, 2023
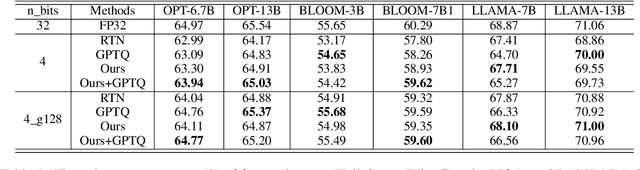
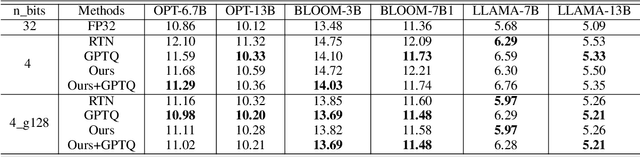

As large language models (LLMs) become more prevalent, there is a growing need for new and improved quantization methods that can meet the computationalast layer demands of these modern architectures while maintaining the accuracy. In this paper, we present TEQ, a trainable equivalent transformation that preserves the FP32 precision of the model output while taking advantage of low-precision quantization, especially 3 and 4 bits weight-only quantization. The training process is lightweight, requiring only 1K steps and fewer than 0.1 percent of the original model's trainable parameters. Furthermore, the transformation does not add any computational overhead during inference. Our results are on-par with the state-of-the-art (SOTA) methods on typical LLMs. Our approach can be combined with other methods to achieve even better performance. The code is available at https://github.com/intel/neural-compressor.
Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs
Sep 28, 2023



Large Language Models (LLMs) have proven their exceptional capabilities in performing language-related tasks. However, their deployment poses significant challenges due to their considerable memory and storage requirements. In response to this issue, weight-only quantization, particularly 3 and 4-bit weight-only quantization, has emerged as one of the most viable solutions. As the number of bits decreases, the quantization grid broadens, thus emphasizing the importance of up and down rounding. While previous studies have demonstrated that fine-tuning up and down rounding with the addition of perturbations can enhance accuracy in some scenarios, our study is driven by the precise and limited boundary of these perturbations, where only the threshold for altering the rounding value is of significance. Consequently, we propose a concise and highly effective approach for optimizing the weight rounding task. Our method, named SignRound, involves lightweight block-wise tuning using signed gradient descent, enabling us to achieve outstanding results within 400 steps. SignRound competes impressively against recent methods without introducing additional inference overhead. The source code will be publicly available at \url{https://github.com/intel/neural-compressor} soon.
Efficient Post-training Quantization with FP8 Formats
Sep 26, 2023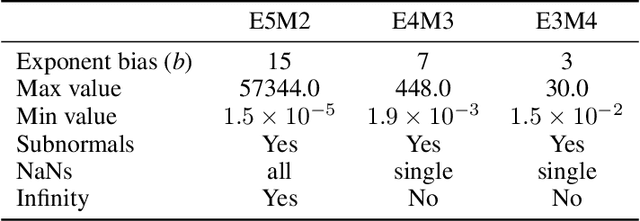

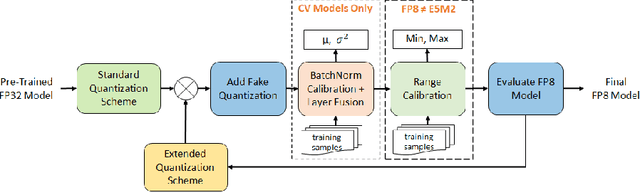
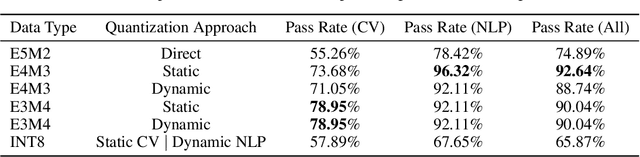
Recent advances in deep learning methods such as LLMs and Diffusion models have created a need for improved quantization methods that can meet the computational demands of these modern architectures while maintaining accuracy. Towards this goal, we study the advantages of FP8 data formats for post-training quantization across 75 unique network architectures covering a wide range of tasks, including machine translation, language modeling, text generation, image classification, generation, and segmentation. We examine three different FP8 representations (E5M2, E4M3, and E3M4) to study the effects of varying degrees of trade-off between dynamic range and precision on model accuracy. Based on our extensive study, we developed a quantization workflow that generalizes across different network architectures. Our empirical results show that FP8 formats outperform INT8 in multiple aspects, including workload coverage (92.64% vs. 65.87%), model accuracy and suitability for a broader range of operations. Furthermore, our findings suggest that E4M3 is better suited for NLP models, whereas E3M4 performs marginally better than E4M3 on computer vision tasks. The code is publicly available on Intel Neural Compressor: https://github.com/intel/neural-compressor.
An Efficient Sparse Inference Software Accelerator for Transformer-based Language Models on CPUs
Jun 28, 2023



In recent years, Transformer-based language models have become the standard approach for natural language processing tasks. However, stringent throughput and latency requirements in industrial applications are limiting their adoption. To mitigate the gap, model compression techniques such as structured pruning are being used to improve inference efficiency. However, most existing neural network inference runtimes lack adequate support for structured sparsity. In this paper, we propose an efficient sparse deep learning inference software stack for Transformer-based language models where the weights are pruned with constant block size. Our sparse software accelerator leverages Intel Deep Learning Boost to maximize the performance of sparse matrix - dense matrix multiplication (commonly abbreviated as SpMM) on CPUs. Our SpMM kernel outperforms the existing sparse libraries (oneMKL, TVM, and LIBXSMM) by an order of magnitude on a wide range of GEMM shapes under 5 representative sparsity ratios (70%, 75%, 80%, 85%, 90%). Moreover, our SpMM kernel shows up to 5x speedup over dense GEMM kernel of oneDNN, a well-optimized dense library widely used in industry. We apply our sparse accelerator on widely-used Transformer-based language models including Bert-Mini, DistilBERT, Bert-Base, and BERT-Large. Our sparse inference software shows up to 1.5x speedup over Neural Magic's Deepsparse under same configurations on Xeon on Amazon Web Services under proxy production latency constraints. We also compare our solution with two framework-based inference solutions, ONNX Runtime and PyTorch, and demonstrate up to 37x speedup over ONNX Runtime and 345x over PyTorch on Xeon under the latency constraints. All the source code is publicly available on Github: https://github.com/intel/intel-extension-for-transformers.
QuaLA-MiniLM: a Quantized Length Adaptive MiniLM
Oct 31, 2022
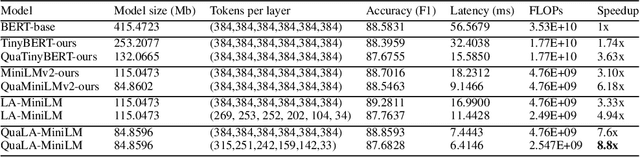

Limited computational budgets often prevent transformers from being used in production and from having their high accuracy utilized. A knowledge distillation approach addresses the computational efficiency by self-distilling BERT into a smaller transformer representation having fewer layers and smaller internal embedding. However, the performance of these models drops as we reduce the number of layers, notably in advanced NLP tasks such as span question answering. In addition, a separate model must be trained for each inference scenario with its distinct computational budget. Dynamic-TinyBERT tackles both limitations by partially implementing the Length Adaptive Transformer (LAT) technique onto TinyBERT, achieving x3 speedup over BERT-base with minimal accuracy loss. In this work, we expand the Dynamic-TinyBERT approach to generate a much more highly efficient model. We use MiniLM distillation jointly with the LAT method, and we further enhance the efficiency by applying low-bit quantization. Our quantized length-adaptive MiniLM model (QuaLA-MiniLM) is trained only once, dynamically fits any inference scenario, and achieves an accuracy-efficiency trade-off superior to any other efficient approaches per any computational budget on the SQuAD1.1 dataset (up to x8.8 speedup with <1% accuracy loss). The code to reproduce this work will be publicly released on Github soon.
Fast DistilBERT on CPUs
Oct 27, 2022Transformer-based language models have become the standard approach to solving natural language processing tasks. However, industry adoption usually requires the maximum throughput to comply with certain latency constraints that prevents Transformer models from being used in production. To address this gap, model compression techniques such as quantization and pruning may be used to improve inference efficiency. However, these compression techniques require specialized software to apply and deploy at scale. In this work, we propose a new pipeline for creating and running Fast Transformer models on CPUs, utilizing hardware-aware pruning, knowledge distillation, quantization, and our own Transformer inference runtime engine with optimized kernels for sparse and quantized operators. We demonstrate the efficiency of our pipeline by creating a Fast DistilBERT model showing minimal accuracy loss on the question-answering SQuADv1.1 benchmark, and throughput results under typical production constraints and environments. Our results outperform existing state-of-the-art Neural Magic's DeepSparse runtime performance by up to 50% and up to 4.1x performance speedup over ONNX Runtime.
Prune Once for All: Sparse Pre-Trained Language Models
Nov 10, 2021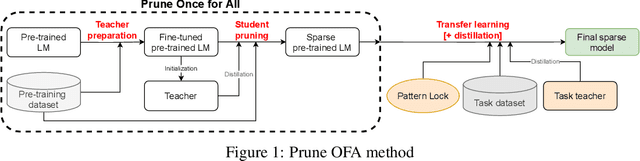
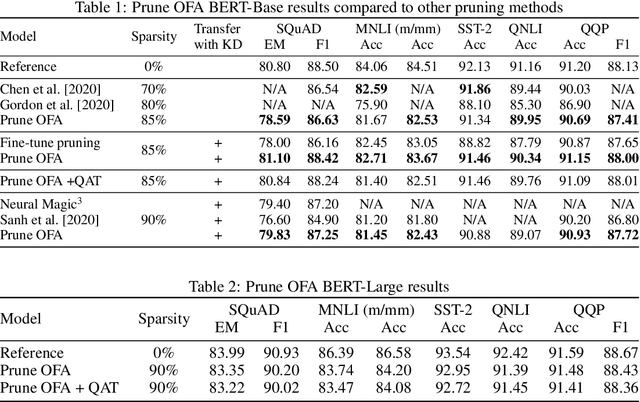
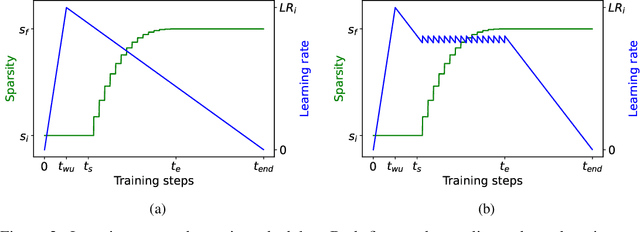
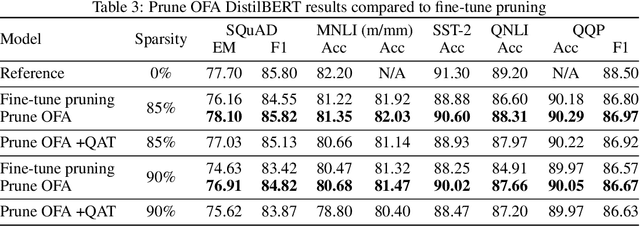
Transformer-based language models are applied to a wide range of applications in natural language processing. However, they are inefficient and difficult to deploy. In recent years, many compression algorithms have been proposed to increase the implementation efficiency of large Transformer-based models on target hardware. In this work we present a new method for training sparse pre-trained Transformer language models by integrating weight pruning and model distillation. These sparse pre-trained models can be used to transfer learning for a wide range of tasks while maintaining their sparsity pattern. We demonstrate our method with three known architectures to create sparse pre-trained BERT-Base, BERT-Large and DistilBERT. We show how the compressed sparse pre-trained models we trained transfer their knowledge to five different downstream natural language tasks with minimal accuracy loss. Moreover, we show how to further compress the sparse models' weights to 8bit precision using quantization-aware training. For example, with our sparse pre-trained BERT-Large fine-tuned on SQuADv1.1 and quantized to 8bit we achieve a compression ratio of $40$X for the encoder with less than $1\%$ accuracy loss. To the best of our knowledge, our results show the best compression-to-accuracy ratio for BERT-Base, BERT-Large, and DistilBERT.
Highly Efficient 8-bit Low Precision Inference of Convolutional Neural Networks with IntelCaffe
May 04, 2018
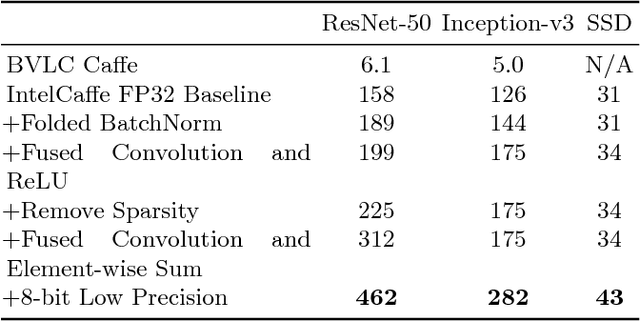

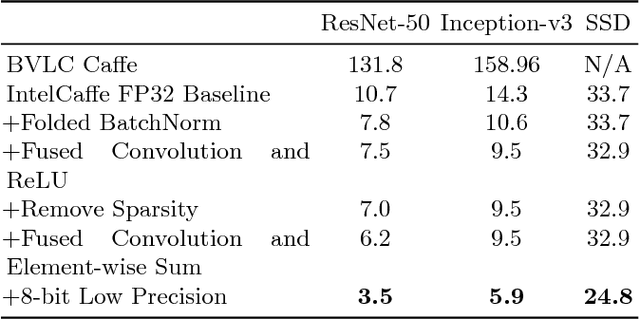
High throughput and low latency inference of deep neural networks are critical for the deployment of deep learning applications. This paper presents the efficient inference techniques of IntelCaffe, the first Intel optimized deep learning framework that supports efficient 8-bit low precision inference and model optimization techniques of convolutional neural networks on Intel Xeon Scalable Processors. The 8-bit optimized model is automatically generated with a calibration process from FP32 model without the need of fine-tuning or retraining. We show that the inference throughput and latency with ResNet-50, Inception-v3 and SSD are improved by 1.38X-2.9X and 1.35X-3X respectively with neglectable accuracy loss from IntelCaffe FP32 baseline and by 56X-75X and 26X-37X from BVLC Caffe. All these techniques have been open-sourced on IntelCaffe GitHub1, and the artifact is provided to reproduce the result on Amazon AWS Cloud.