 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEQ: Trainable Equivalent Transformation for Quantization of LLMs
Paper and Code

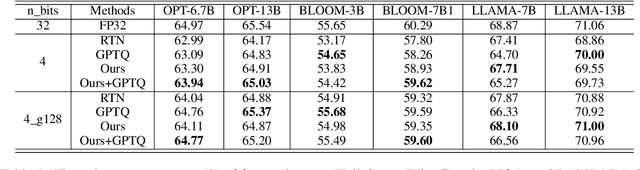
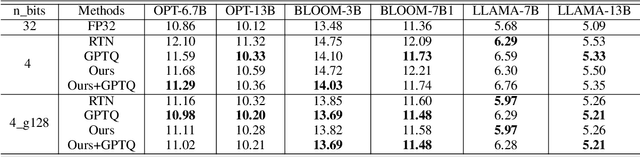

As large language models (LLMs) become more prevalent, there is a growing need for new and improved quantization methods that can meet the computationalast layer demands of these modern architectures while maintaining the accuracy. In this paper, we present TEQ, a trainable equivalent transformation that preserves the FP32 precision of the model output while taking advantage of low-precision quantization, especially 3 and 4 bits weight-only quantization. The training process is lightweight, requiring only 1K steps and fewer than 0.1 percent of the original model's trainable parameters. Furthermore, the transformation does not add any computational overhead during inference. Our results are on-par with the state-of-the-art (SOTA) methods on typical LLMs. Our approach can be combined with other methods to achieve even better performance. The code is available at https://github.com/intel/neural-compressor.