 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaLA-MiniLM: a Quantized Length Adaptive MiniLM
Oct 31, 2022
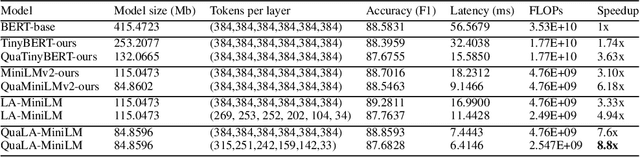

Limited computational budgets often prevent transformers from being used in production and from having their high accuracy utilized. A knowledge distillation approach addresses the computational efficiency by self-distilling BERT into a smaller transformer representation having fewer layers and smaller internal embedding. However, the performance of these models drops as we reduce the number of layers, notably in advanced NLP tasks such as span question answering. In addition, a separate model must be trained for each inference scenario with its distinct computational budget. Dynamic-TinyBERT tackles both limitations by partially implementing the Length Adaptive Transformer (LAT) technique onto TinyBERT, achieving x3 speedup over BERT-base with minimal accuracy loss. In this work, we expand the Dynamic-TinyBERT approach to generate a much more highly efficient model. We use MiniLM distillation jointly with the LAT method, and we further enhance the efficiency by applying low-bit quantization. Our quantized length-adaptive MiniLM model (QuaLA-MiniLM) is trained only once, dynamically fits any inference scenario, and achieves an accuracy-efficiency trade-off superior to any other efficient approaches per any computational budget on the SQuAD1.1 dataset (up to x8.8 speedup with <1% accuracy loss). The code to reproduce this work will be publicly released on Github soon.
Dynamic-TinyBERT: Boost TinyBERT's Inference Efficiency by Dynamic Sequence Length
Nov 18, 2021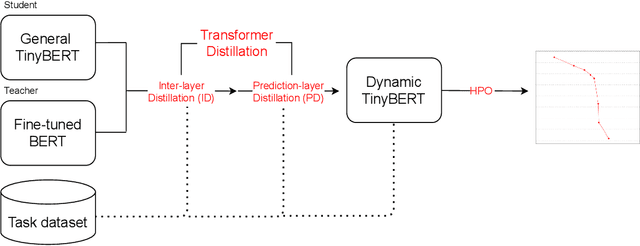
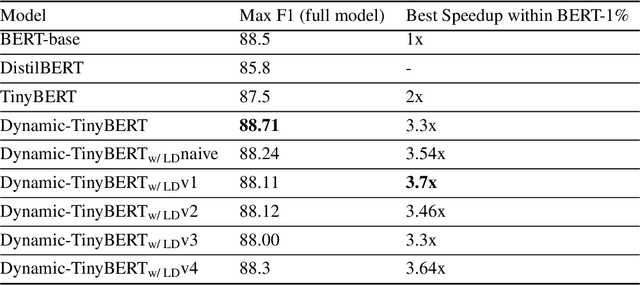
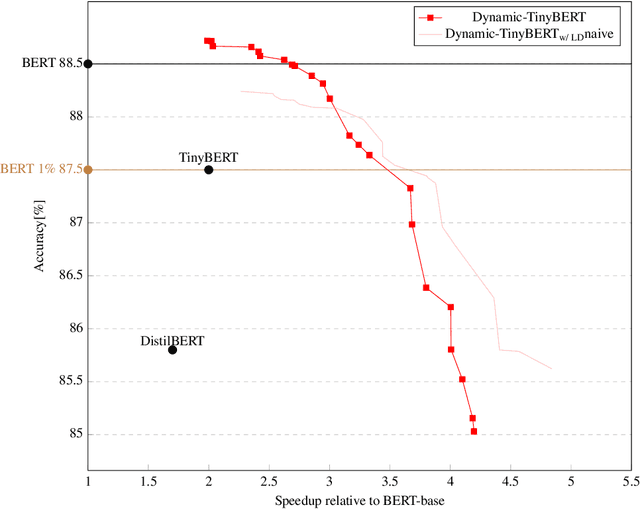
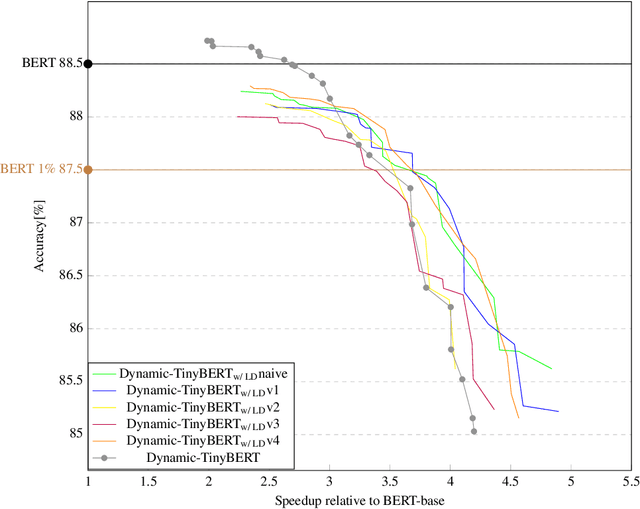
Limited computational budgets often prevent transformers from being used in production and from having their high accuracy utilized. TinyBERT addresses the computational efficiency by self-distilling BERT into a smaller transformer representation having fewer layers and smaller internal embedding. However, TinyBERT's performance drops when we reduce the number of layers by 50%, and drops even more abruptly when we reduce the number of layers by 75% for advanced NLP tasks such as span question answering. Additionally, a separate model must be trained for each inference scenario with its distinct computational budget. In this work we present Dynamic-TinyBERT, a TinyBERT model that utilizes sequence-length reduction and Hyperparameter Optimization for enhanced inference efficiency per any computational budget. Dynamic-TinyBERT is trained only once, performing on-par with BERT and achieving an accuracy-speedup trade-off superior to any other efficient approaches (up to 3.3x with <1% loss-drop). Upon publication, the code to reproduce our work will be open-sourced.
Training Compact Models for Low Resource Entity Tagging using Pre-trained Language Models
Oct 17, 2019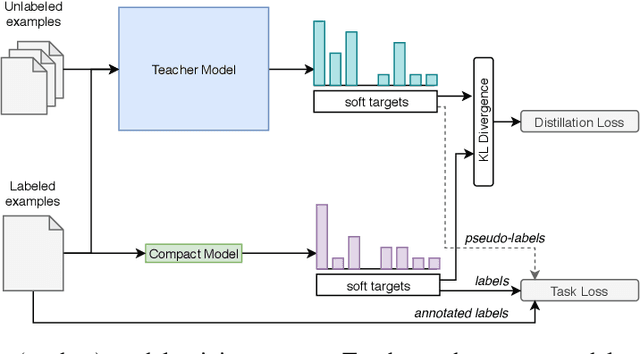
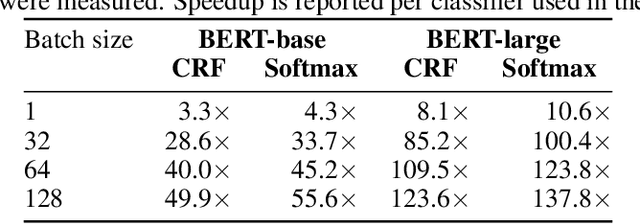
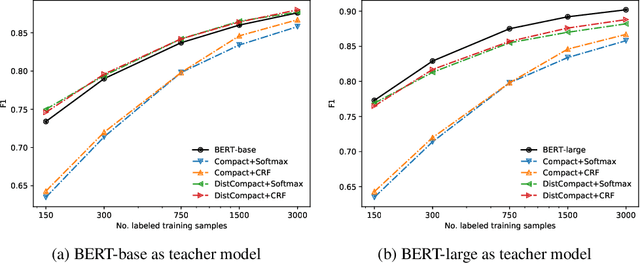
Training models on low-resource named entity recognition tasks has been shown to be a challenge, especially in industrial applications where deploying updated models is a continuous effort and crucial for business operations. In such cases there is often an abundance of unlabeled data, while labeled data is scarce or unavailable. Pre-trained language models trained to extract contextual features from text were shown to improve many natural language processing (NLP) tasks, including scarcely labeled tasks, by leveraging transfer learning. However, such models impose a heavy memory and computational burden, making it a challenge to train and deploy such models for inference use. In this work-in-progress we combined the effectiveness of transfer learning provided by pre-trained masked language models with a semi-supervised approach to train a fast and compact model using labeled and unlabeled examples. Preliminary evaluations show that the compact models can achieve competitive accuracy with 36x compression rate when compared with a state-of-the-art pre-trained language model, and run significantly faster in inference, allowing deployment of such models in production environments or on edge devices.
Term Set Expansion based NLP Architect by Intel AI Lab
Oct 15, 2018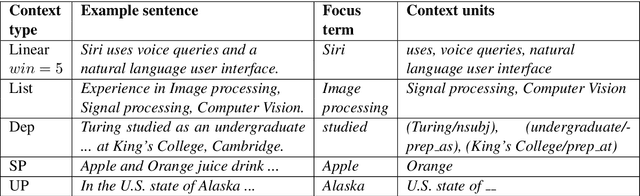

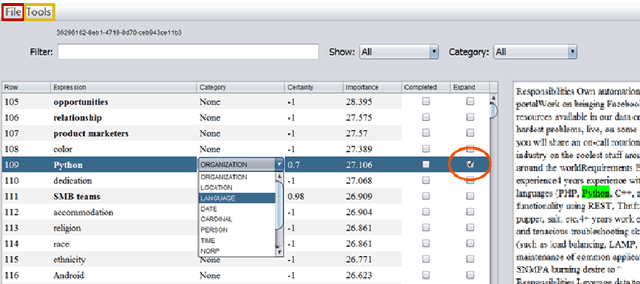
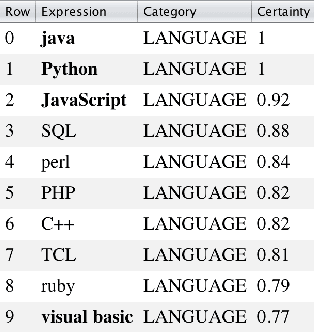
We present SetExpander, a corpus-based system for expanding a seed set of terms into amore complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to-end workflow. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes.SetExpander has been used successfully in real-life use cases including integration into an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons)
Term Set Expansion based on Multi-Context Term Embeddings: an End-to-end Workflow
Jul 26, 2018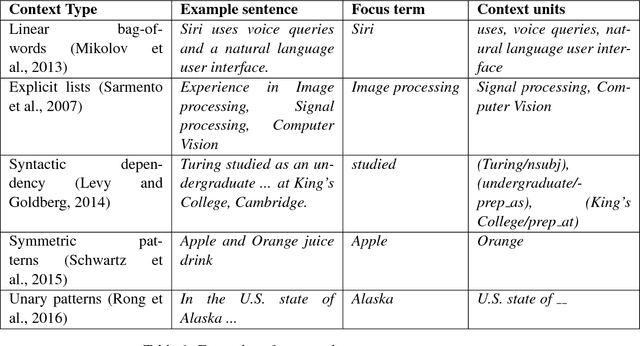

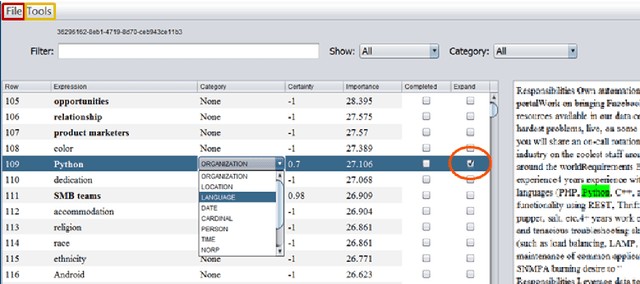
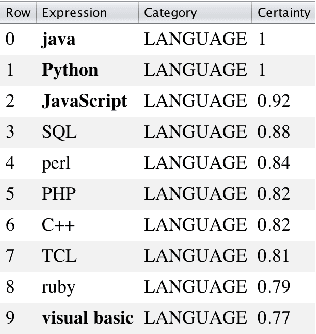
We present SetExpander, a corpus-based system for expanding a seed set of terms into a more complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to end workflow for term set expansion. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes. SetExpander has been used for solving real-life use cases including integration in an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons).