 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventFull: Complete and Consistent Event Relation Annotation
Dec 17, 2024



Event relation detection is a fundamental NLP task, leveraged in many downstream applications, whose modeling requires datasets annotated with event relations of various types. However, systematic and complete annotation of these relations is costly and challenging, due to the quadratic number of event pairs that need to be considered. Consequently, many current event relation datasets lack systematicity and completeness. In response, we introduce \textit{EventFull}, the first tool that supports consistent, complete and efficient annotation of temporal, causal and coreference relations via a unified and synergetic process. A pilot study demonstrates that EventFull accelerates and simplifies the annotation process while yielding high inter-annotator agreement.
Cross-document Event Coreference Search: Task, Dataset and Modeling
Oct 23, 2022The task of Cross-document Coreference Resolution has been traditionally formulated as requiring to identify all coreference links across a given set of documents. We propose an appealing, and often more applicable, complementary set up for the task - Cross-document Coreference Search, focusing in this paper on event coreference. Concretely, given a mention in context of an event of interest, considered as a query, the task is to find all coreferring mentions for the query event in a large document collection. To support research on this task, we create a corresponding dataset, which is derived from Wikipedia while leveraging annotations in the available Wikipedia Event Coreference dataset (WEC-Eng). Observing that the coreference search setup is largely analogous to the setting of Open Domain Question Answering, we adapt the prominent Deep Passage Retrieval (DPR) model to our setting, as an appealing baseline. Finally, we present a novel model that integrates a powerful coreference scoring scheme into the DPR architecture, yielding improved performance.
iFacetSum: Coreference-based Interactive Faceted Summarization for Multi-Document Exploration
Sep 23, 2021

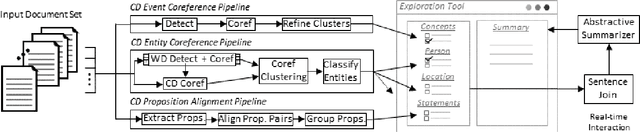
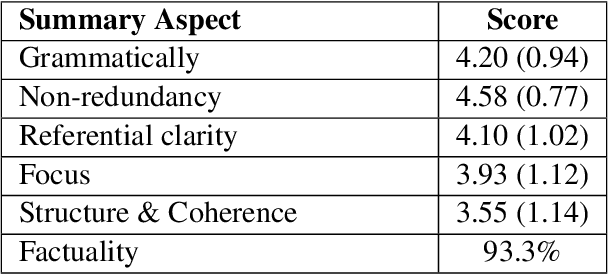
We introduce iFacetSum, a web application for exploring topical document sets. iFacetSum integrates interactive summarization together with faceted search, by providing a novel faceted navigation scheme that yields abstractive summaries for the user's selections. This approach offers both a comprehensive overview as well as concise details regarding subtopics of choice. Fine-grained facets are automatically produced based on cross-document coreference pipelines, rendering generic concepts, entities and statements surfacing in the source texts. We analyze the effectiveness of our application through small-scale user studies, which suggest the usefulness of our approach.
Realistic Evaluation Principles for Cross-document Coreference Resolution
Jun 08, 2021



We point out that common evaluation practices for cross-document coreference resolution have been unrealistically permissive in their assumed settings, yielding inflated results. We propose addressing this issue via two evaluation methodology principles. First, as in other tasks, models should be evaluated on predicted mentions rather than on gold mentions. Doing this raises a subtle issue regarding singleton coreference clusters, which we address by decoupling the evaluation of mention detection from that of coreference linking. Second, we argue that models should not exploit the synthetic topic structure of the standard ECB+ dataset, forcing models to confront the lexical ambiguity challenge, as intended by the dataset creators. We demonstrate empirically the drastic impact of our more realistic evaluation principles on a competitive model, yielding a score which is 33 F1 lower compared to evaluating by prior lenient practices.
Cross-document Coreference Resolution over Predicted Mentions
Jun 02, 2021



Coreference resolution has been mostly investigated within a single document scope, showing impressive progress in recent years based on end-to-end models. However, the more challenging task of cross-document (CD) coreference resolution remained relatively under-explored, with the few recent models applied only to gold mentions. Here, we introduce the first end-to-end model for CD coreference resolution from raw text, which extends the prominent model for within-document coreference to the CD setting. Our model achieves competitive results for event and entity coreference resolution on gold mentions. More importantly, we set first baseline results, on the standard ECB+ dataset, for CD coreference resolution over predicted mentions. Further, our model is simpler and more efficient than recent CD coreference resolution systems, while not using any external resources.
WEC: Deriving a Large-scale Cross-document Event Coreference dataset from Wikipedia
Apr 30, 2021



Cross-document event coreference resolution is a foundational task for NLP applications involving multi-text processing. However, existing corpora for this task are scarce and relatively small, while annotating only modest-size clusters of documents belonging to the same topic. To complement these resources and enhance future research, we present Wikipedia Event Coreference (WEC), an efficient methodology for gathering a large-scale dataset for cross-document event coreference from Wikipedia, where coreference links are not restricted within predefined topics. We apply this methodology to the English Wikipedia and extract our large-scale WEC-Eng dataset. Notably, our dataset creation method is generic and can be applied with relatively little effort to other Wikipedia languages. To set baseline results, we develop an algorithm that adapts components of state-of-the-art models for within-document coreference resolution to the cross-document setting. Our model is suitably efficient and outperforms previously published state-of-the-art results for the task.
Streamlining Cross-Document Coreference Resolution: Evaluation and Modeling
Sep 23, 2020


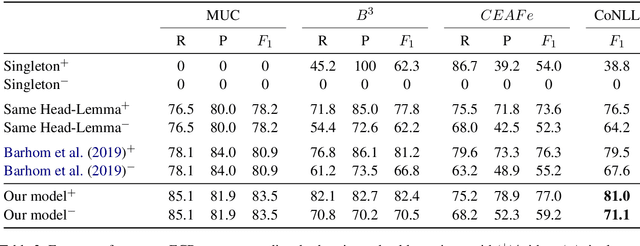
Recent evaluation protocols for Cross-document (CD) coreference resolution have often been inconsistent or lenient, leading to incomparable results across works and overestimation of performance. To facilitate proper future research on this task, our primary contribution is proposing a pragmatic evaluation methodology which assumes access to only raw text -- rather than assuming gold mentions, disregards singleton prediction, and addresses typical targeted settings in CD coreference resolution. Aiming to set baseline results for future research that would follow our evaluation methodology, we build the first end-to-end model for this task. Our model adapts and extends recent neural models for within-document coreference resolution to address the CD coreference setting, which outperforms state-of-the-art results by a significant margin.
Revisiting Joint Modeling of Cross-document Entity and Event Coreference Resolution
Jun 04, 2019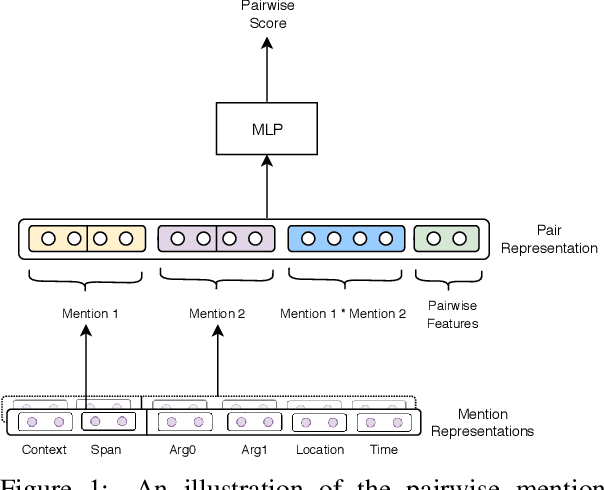
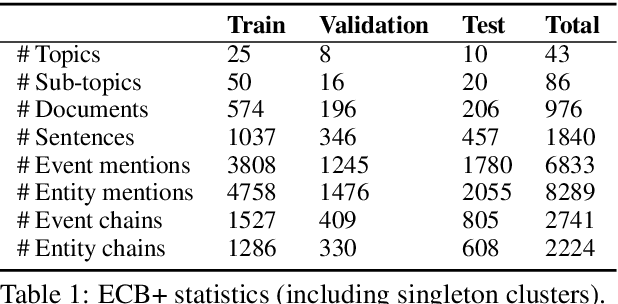


Recognizing coreferring events and entities across multiple texts is crucial for many NLP applications. Despite the task's importance, research focus was given mostly to within-document entity coreference, with rather little attention to the other variants. We propose a neural architecture for cross-document coreference resolution. Inspired by Lee et al (2012), we jointly model entity and event coreference. We represent an event (entity) mention using its lexical span, surrounding context, and relation to entity (event) mentions via predicate-arguments structures. Our model outperforms the previous state-of-the-art event coreference model on ECB+, while providing the first entity coreference results on this corpus. Our analysis confirms that all our representation elements, including the mention span itself, its context, and the relation to other mentions contribute to the model's success.
Term Set Expansion based NLP Architect by Intel AI Lab
Oct 15, 2018

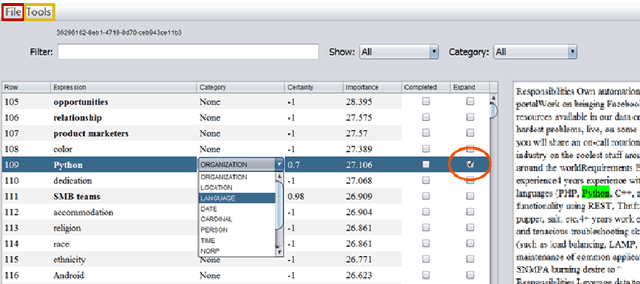
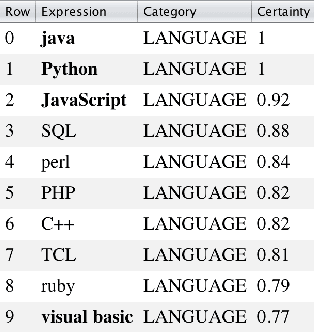
We present SetExpander, a corpus-based system for expanding a seed set of terms into amore complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to-end workflow. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes.SetExpander has been used successfully in real-life use cases including integration into an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons)
Term Set Expansion based on Multi-Context Term Embeddings: an End-to-end Workflow
Jul 26, 2018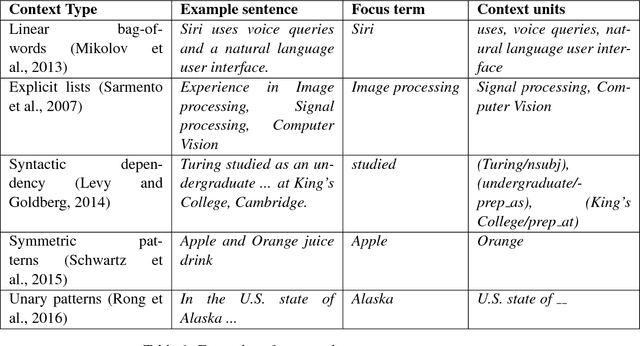

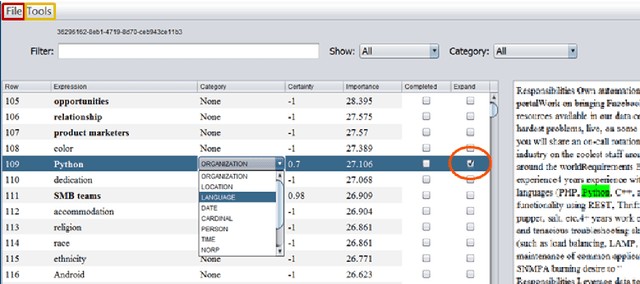
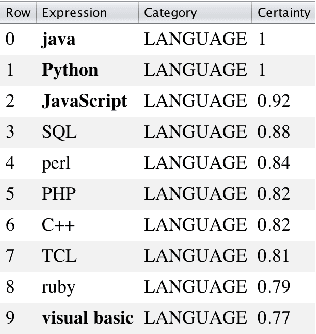
We present SetExpander, a corpus-based system for expanding a seed set of terms into a more complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to end workflow for term set expansion. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes. SetExpander has been used for solving real-life use cases including integration in an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons).