 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Speculative Inference of Large Language Models
May 23, 2024Accelerating the inference of large language models (LLMs) is an important challenge in artificial intelligence. This paper introduces distributed speculative inference (DSI), a novel distributed inference algorithm that is provably faster than speculative inference (SI) [leviathan2023fast, chen2023accelerating, miao2023specinfer] and traditional autoregressive inference (non-SI). Like other SI algorithms, DSI works on frozen LLMs, requiring no training or architectural modifications, and it preserves the target distribution. Prior studies on SI have demonstrated empirical speedups (compared to non-SI) but require a fast and accurate drafter LLM. In practice, off-the-shelf LLMs often do not have matching drafters that are sufficiently fast and accurate. We show a gap: SI gets slower than non-SI when using slower or less accurate drafters. We close this gap by proving that DSI is faster than both SI and non-SI given any drafters. By orchestrating multiple instances of the target and drafters, DSI is not only faster than SI but also supports LLMs that cannot be accelerated with SI. Our simulations show speedups of off-the-shelf LLMs in realistic settings: DSI is 1.29-1.92x faster than SI.
Accelerating Speculative Decoding using Dynamic Speculation Length
May 07, 2024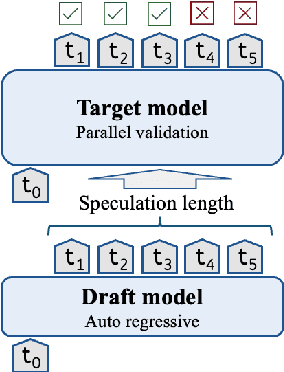


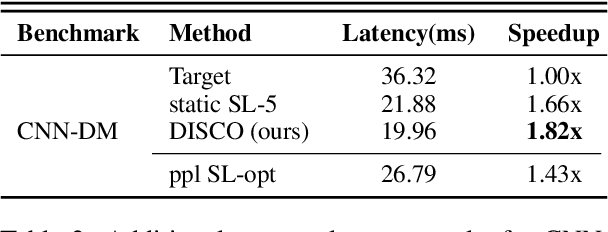
Speculative decoding is a promising method for reducing the inference latency of large language models. The effectiveness of the method depends on the speculation length (SL) - the number of tokens generated by the draft model at each iteration. The vast majority of speculative decoding approaches use the same SL for all iterations. In this work, we show that this practice is suboptimal. We introduce DISCO, a DynamIc SpeCulation length Optimization method that uses a classifier to dynamically adjust the SL at each iteration, while provably preserving the decoding quality. Experiments with four benchmarks demonstrate average speedup gains of 10.3% relative to our best baselines.
Cross-Domain Aspect Extraction using Transformers Augmented with Knowledge Graphs
Oct 18, 2022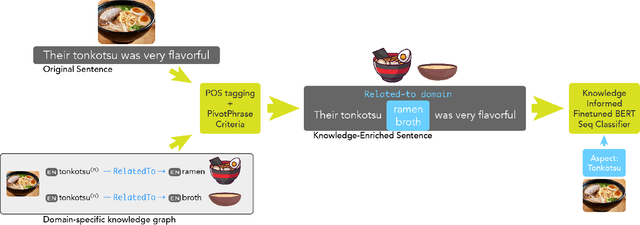
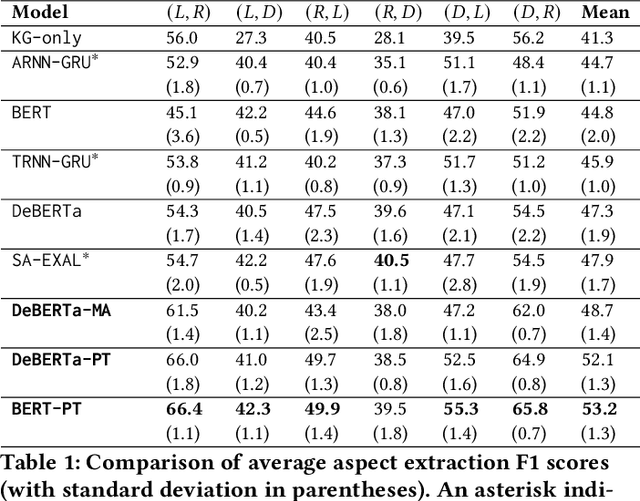
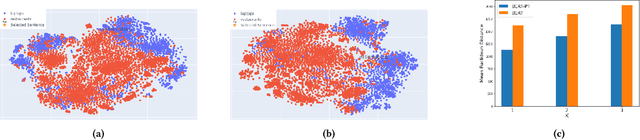
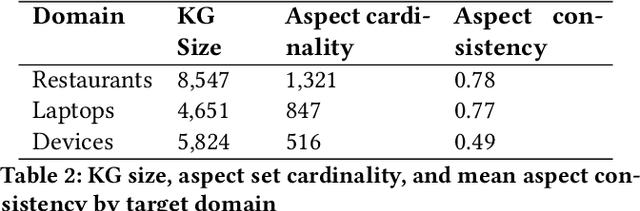
The extraction of aspect terms is a critical step in fine-grained sentiment analysis of text. Existing approaches for this task have yielded impressive results when the training and testing data are from the same domain. However, these methods show a drastic decrease in performance when applied to cross-domain settings where the domain of the testing data differs from that of the training data. To address this lack of extensibility and robustness, we propose a novel approach for automatically constructing domain-specific knowledge graphs that contain information relevant to the identification of aspect terms. We introduce a methodology for injecting information from these knowledge graphs into Transformer models, including two alternative mechanisms for knowledge insertion: via query enrichment and via manipulation of attention patterns. We demonstrate state-of-the-art performance on benchmark datasets for cross-domain aspect term extraction using our approach and investigate how the amount of external knowledge available to the Transformer impacts model performance.
Efficient Few-Shot Learning Without Prompts
Sep 22, 2022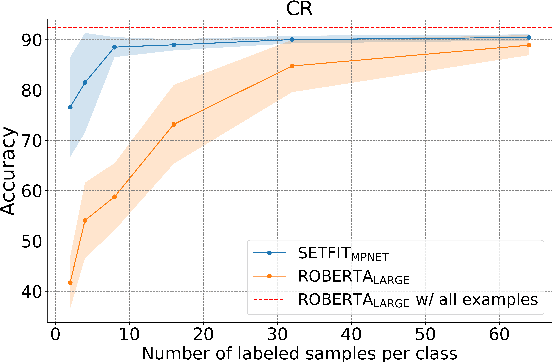

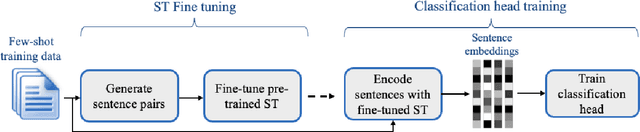
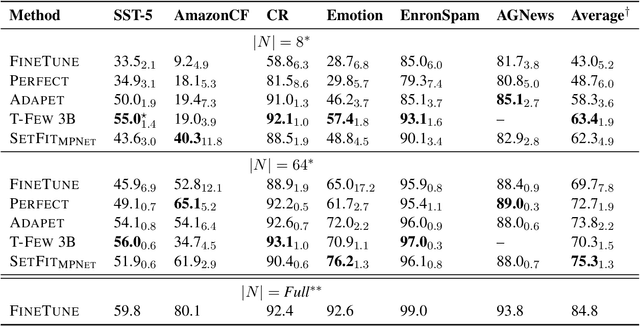
Recent few-shot methods, such as parameter-efficient fine-tuning (PEFT) and pattern exploiting training (PET), have achieved impressive results in label-scarce settings. However, they are difficult to employ since they are subject to high variability from manually crafted prompts, and typically require billion-parameter language models to achieve high accuracy. To address these shortcomings, we propose SetFit (Sentence Transformer Fine-tuning), an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers (ST). SetFit works by first fine-tuning a pretrained ST on a small number of text pairs, in a contrastive Siamese manner. The resulting model is then used to generate rich text embeddings, which are used to train a classification head. This simple framework requires no prompts or verbalizers, and achieves high accuracy with orders of magnitude less parameters than existing techniques. Our experiments show that SetFit obtains comparable results with PEFT and PET techniques, while being an order of magnitude faster to train. We also show that SetFit can be applied in multilingual settings by simply switching the ST body. Our code is available at https://github.com/huggingface/setfit and our datasets at https://huggingface.co/setfit .
TangoBERT: Reducing Inference Cost by using Cascaded Architecture
Apr 13, 2022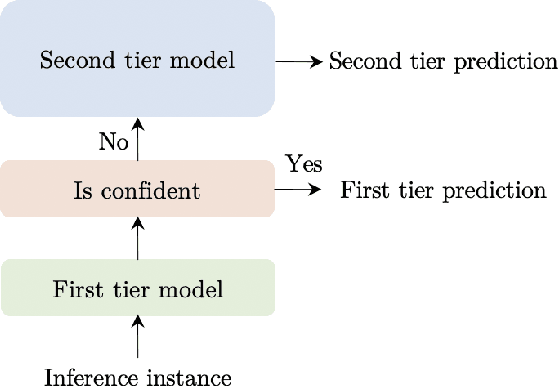

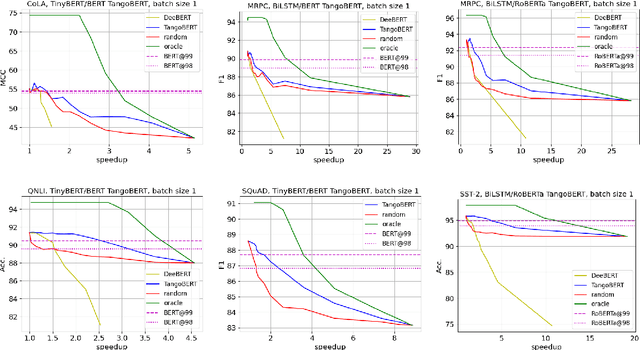
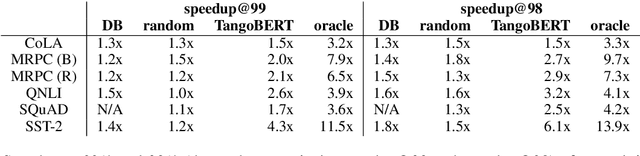
The remarkable success of large transformer-based models such as BERT, RoBERTa and XLNet in many NLP tasks comes with a large increase in monetary and environmental cost due to their high computational load and energy consumption. In order to reduce this computational load in inference time, we present TangoBERT, a cascaded model architecture in which instances are first processed by an efficient but less accurate first tier model, and only part of those instances are additionally processed by a less efficient but more accurate second tier model. The decision of whether to apply the second tier model is based on a confidence score produced by the first tier model. Our simple method has several appealing practical advantages compared to standard cascading approaches based on multi-layered transformer models. First, it enables higher speedup gains (average lower latency). Second, it takes advantage of batch size optimization for cascading, which increases the relative inference cost reductions. We report TangoBERT inference CPU speedup on four text classification GLUE tasks and on one reading comprehension task. Experimental results show that TangoBERT outperforms efficient early exit baseline models; on the the SST-2 task, it achieves an accuracy of 93.9% with a CPU speedup of 8.2x.
ABSApp: A Portable Weakly-Supervised Aspect-Based Sentiment Extraction System
Sep 12, 2019


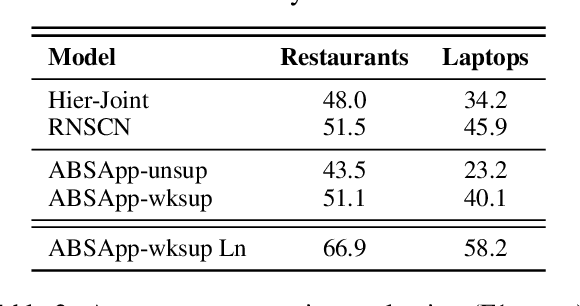
We present ABSApp, a portable system for weakly-supervised aspect-based sentiment extraction. The system is interpretable and user friendly and does not require labeled training data, hence can be rapidly and cost-effectively used across different domains in applied setups. The system flow includes three stages: First, it generates domain-specific aspect and opinion lexicons based on an unlabeled dataset; second, it enables the user to view and edit those lexicons (weak supervision); and finally, it enables the user to select an unlabeled target dataset from the same domain, classify it, and generate an aspect-based sentiment report. ABSApp has been successfully used in a number of real-life use cases, among them movie review analysis and convention impact analysis.
Multi-Context Term Embeddings: the Use Case of Corpus-based Term Set Expansion
Apr 10, 2019

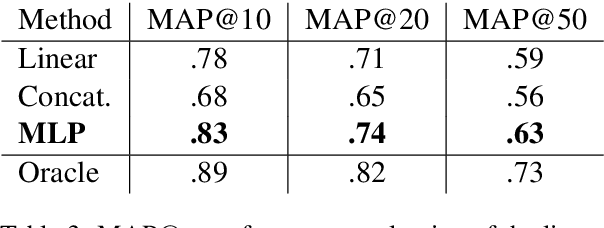
In this paper, we present a novel algorithm that combines multi-context term embeddings using a neural classifier and we test this approach on the use case of corpus-based term set expansion. In addition, we present a novel and unique dataset for intrinsic evaluation of corpus-based term set expansion algorithms. We show that, over this dataset, our algorithm provides up to 5 mean average precision points over the best baseline.
Term Set Expansion based NLP Architect by Intel AI Lab
Oct 15, 2018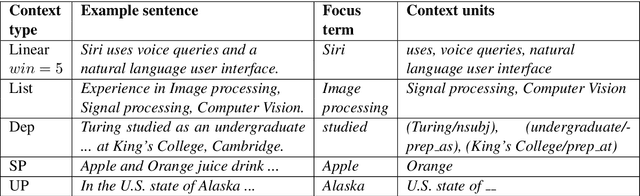

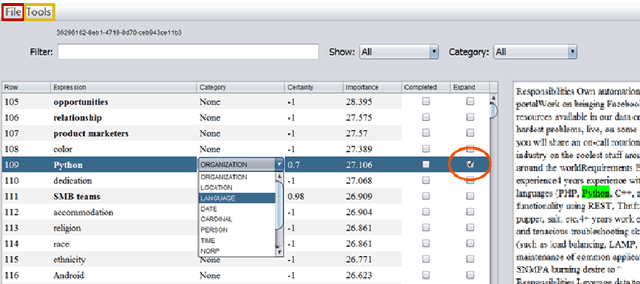
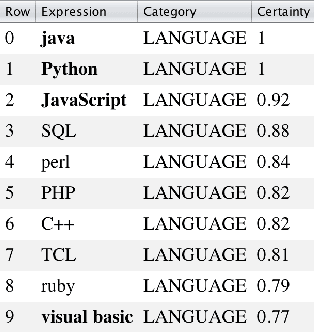
We present SetExpander, a corpus-based system for expanding a seed set of terms into amore complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to-end workflow. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes.SetExpander has been used successfully in real-life use cases including integration into an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons)
Term Set Expansion based on Multi-Context Term Embeddings: an End-to-end Workflow
Jul 26, 2018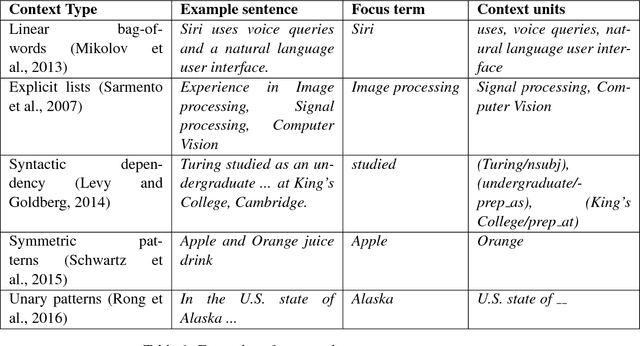

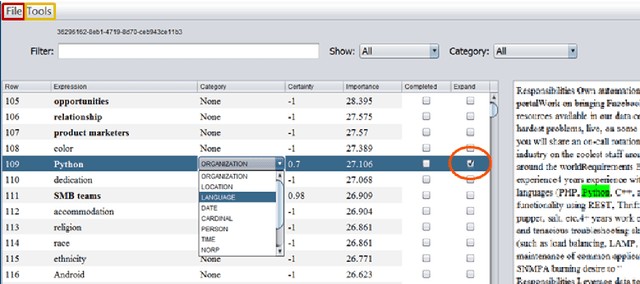
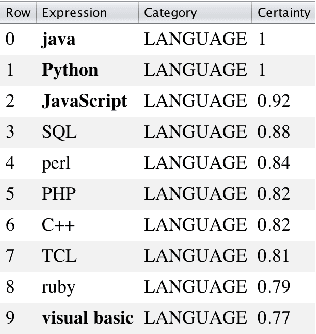
We present SetExpander, a corpus-based system for expanding a seed set of terms into a more complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to end workflow for term set expansion. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes. SetExpander has been used for solving real-life use cases including integration in an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons).