 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroComparatives: Neuro-Symbolic Distillation of Comparative Knowledge
May 08, 2023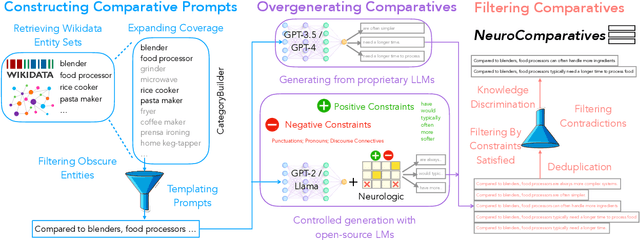

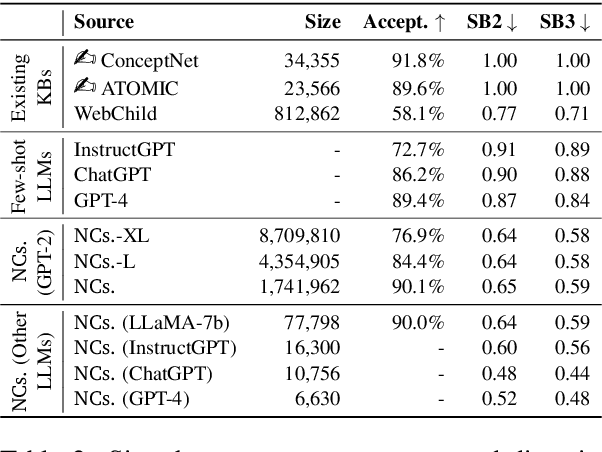
Comparative knowledge (e.g., steel is stronger and heavier than styrofoam) is an essential component of our world knowledge, yet understudied in prior literature. In this paper, we study the task of comparative knowledge acquisition, motivated by the dramatic improvements in the capabilities of extreme-scale language models like GPT-3, which have fueled efforts towards harvesting their knowledge into knowledge bases. However, access to inference API for such models is limited, thereby restricting the scope and the diversity of the knowledge acquisition. We thus ask a seemingly implausible question: whether more accessible, yet considerably smaller and weaker models such as GPT-2, can be utilized to acquire comparative knowledge, such that the resulting quality is on par with their large-scale counterparts? We introduce NeuroComparatives, a novel framework for comparative knowledge distillation using lexically-constrained decoding, followed by stringent filtering of generated knowledge. Our framework acquires comparative knowledge between everyday objects and results in a corpus of 8.7M comparisons over 1.74M entity pairs - 10X larger and 30% more diverse than existing resources. Moreover, human evaluations show that NeuroComparatives outperform existing resources (up to 32% absolute improvement), even including GPT-3, despite using a 100X smaller model. Our results motivate neuro-symbolic manipulation of smaller models as a cost-effective alternative to the currently dominant practice of relying on extreme-scale language models with limited inference access.
Cross-Domain Aspect Extraction using Transformers Augmented with Knowledge Graphs
Oct 18, 2022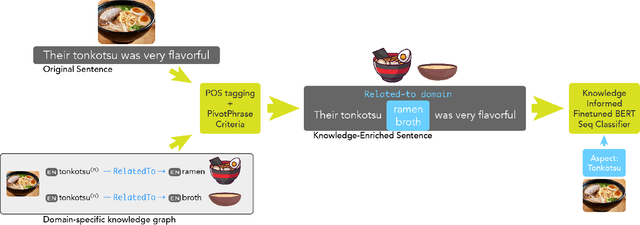
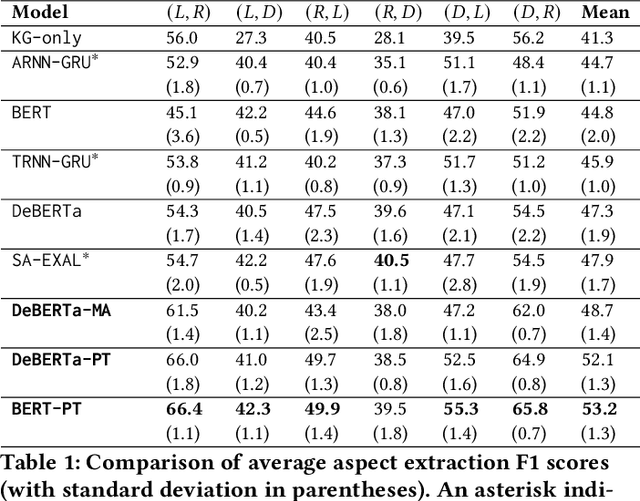
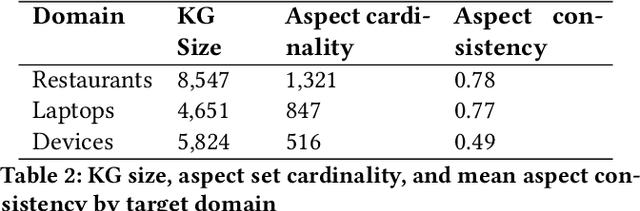
The extraction of aspect terms is a critical step in fine-grained sentiment analysis of text. Existing approaches for this task have yielded impressive results when the training and testing data are from the same domain. However, these methods show a drastic decrease in performance when applied to cross-domain settings where the domain of the testing data differs from that of the training data. To address this lack of extensibility and robustness, we propose a novel approach for automatically constructing domain-specific knowledge graphs that contain information relevant to the identification of aspect terms. We introduce a methodology for injecting information from these knowledge graphs into Transformer models, including two alternative mechanisms for knowledge insertion: via query enrichment and via manipulation of attention patterns. We demonstrate state-of-the-art performance on benchmark datasets for cross-domain aspect term extraction using our approach and investigate how the amount of external knowledge available to the Transformer impacts model performance.