 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollage Diffusion
Mar 01, 2023



Text-conditional diffusion models generate high-quality, diverse images. However, text is often an ambiguous specification for a desired target image, creating the need for additional user-friendly controls for diffusion-based image generation. We focus on having precise control over image output for scenes with several objects. Users control image generation by defining a collage: a text prompt paired with an ordered sequence of layers, where each layer is an RGBA image and a corresponding text prompt. We introduce Collage Diffusion, a collage-conditional diffusion algorithm that allows users to control both the spatial arrangement and visual attributes of objects in the scene, and also enables users to edit individual components of generated images. To ensure that different parts of the input text correspond to the various locations specified in the input collage layers, Collage Diffusion modifies text-image cross-attention with the layers' alpha masks. To maintain characteristics of individual collage layers that are not specified in text, Collage Diffusion learns specialized text representations per layer. Collage input also enables layer-based controls that provide fine-grained control over the final output: users can control image harmonization on a layer-by-layer basis, and they can edit individual objects in generated images while keeping other objects fixed. Collage-conditional image generation requires harmonizing the input collage to make objects fit together--the key challenge involves minimizing changes in the positions and key visual attributes of objects in the input collage while allowing other attributes of the collage to change in the harmonization process. By leveraging the rich information present in layer input, Collage Diffusion generates globally harmonized images that maintain desired object locations and visual characteristics better than prior approaches.
Cross-Domain Aspect Extraction using Transformers Augmented with Knowledge Graphs
Oct 18, 2022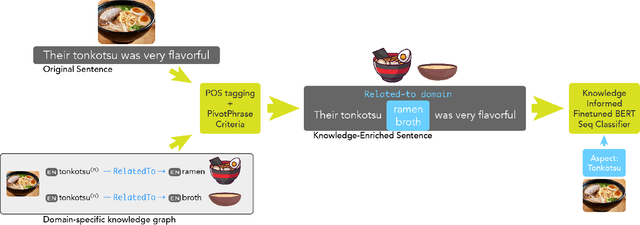
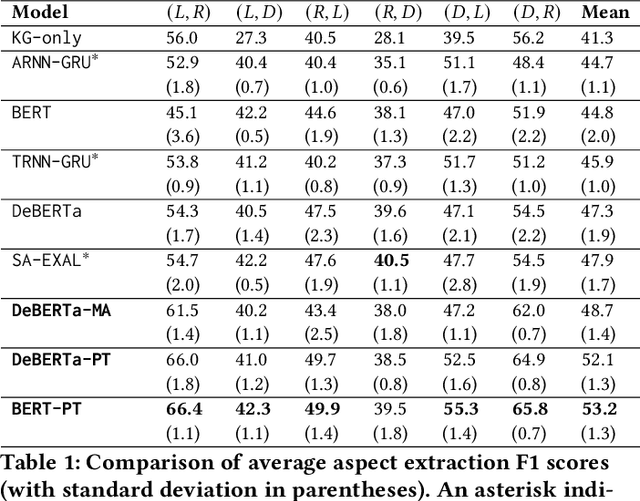
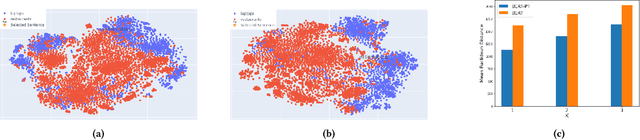
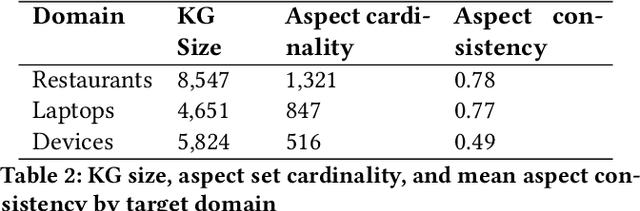
The extraction of aspect terms is a critical step in fine-grained sentiment analysis of text. Existing approaches for this task have yielded impressive results when the training and testing data are from the same domain. However, these methods show a drastic decrease in performance when applied to cross-domain settings where the domain of the testing data differs from that of the training data. To address this lack of extensibility and robustness, we propose a novel approach for automatically constructing domain-specific knowledge graphs that contain information relevant to the identification of aspect terms. We introduce a methodology for injecting information from these knowledge graphs into Transformer models, including two alternative mechanisms for knowledge insertion: via query enrichment and via manipulation of attention patterns. We demonstrate state-of-the-art performance on benchmark datasets for cross-domain aspect term extraction using our approach and investigate how the amount of external knowledge available to the Transformer impacts model performance.