 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData and System Perspectives of Sustainable Artificial Intelligence
Jan 13, 2025Sustainable AI is a subfield of AI for concerning developing and using AI systems in ways of aiming to reduce environmental impact and achieve sustainability. Sustainable AI is increasingly important given that training of and inference with AI models such as large langrage models are consuming a large amount of computing power. In this article, we discuss current issues, opportunities and example solutions for addressing these issues, and future challenges to tackle, from the data and system perspectives, related to data acquisition, data processing, and AI model training and inference.
Distributed Speculative Inference of Large Language Models
May 23, 2024Accelerating the inference of large language models (LLMs) is an important challenge in artificial intelligence. This paper introduces distributed speculative inference (DSI), a novel distributed inference algorithm that is provably faster than speculative inference (SI) [leviathan2023fast, chen2023accelerating, miao2023specinfer] and traditional autoregressive inference (non-SI). Like other SI algorithms, DSI works on frozen LLMs, requiring no training or architectural modifications, and it preserves the target distribution. Prior studies on SI have demonstrated empirical speedups (compared to non-SI) but require a fast and accurate drafter LLM. In practice, off-the-shelf LLMs often do not have matching drafters that are sufficiently fast and accurate. We show a gap: SI gets slower than non-SI when using slower or less accurate drafters. We close this gap by proving that DSI is faster than both SI and non-SI given any drafters. By orchestrating multiple instances of the target and drafters, DSI is not only faster than SI but also supports LLMs that cannot be accelerated with SI. Our simulations show speedups of off-the-shelf LLMs in realistic settings: DSI is 1.29-1.92x faster than SI.
Non-verbal information in spontaneous speech -- towards a new framework of analysis
Mar 13, 2024



Non-verbal signals in speech are encoded by prosody and carry information that ranges from conversation action to attitude and emotion. Despite its importance, the principles that govern prosodic structure are not yet adequately understood. This paper offers an analytical schema and a technological proof-of-concept for the categorization of prosodic signals and their association with meaning. The schema interprets surface-representations of multi-layered prosodic events. As a first step towards implementation, we present a classification process that disentangles prosodic phenomena of three orders. It relies on fine-tuning a pre-trained speech recognition model, enabling the simultaneous multi-class/multi-label detection. It generalizes over a large variety of spontaneous data, performing on a par with, or superior to, human annotation. In addition to a standardized formalization of prosody, disentangling prosodic patterns can direct a theory of communication and speech organization. A welcome by-product is an interpretation of prosody that will enhance speech- and language-related technologies.
Human or Machine: Reflections on Turing-Inspired Testing for the Everyday
May 07, 2023Turing's 1950 paper introduced the famed "imitation game", a test originally proposed to capture the notion of machine intelligence. Over the years, the Turing test spawned a large amount of interest, which resulted in several variants, as well as heated discussions and controversy. Here we sidestep the question of whether a particular machine can be labeled intelligent, or can be said to match human capabilities in a given context. Instead, but inspired by Turing, we draw attention to the seemingly simpler challenge of determining whether one is interacting with a human or with a machine, in the context of everyday life. We are interested in reflecting upon the importance of this Human-or-Machine question and the use one may make of a reliable answer thereto. Whereas Turing's original test is widely considered to be more of a thought experiment, the Human-or-Machine question as discussed here has obvious practical significance. And while the jury is still not in regarding the possibility of machines that can mimic human behavior with high fidelity in everyday contexts, we argue that near-term exploration of the issues raised here can contribute to development methods for computerized systems, and may also improve our understanding of human behavior in general.
Constrained Reinforcement Learning for Robotics via Scenario-Based Programming
Jun 20, 2022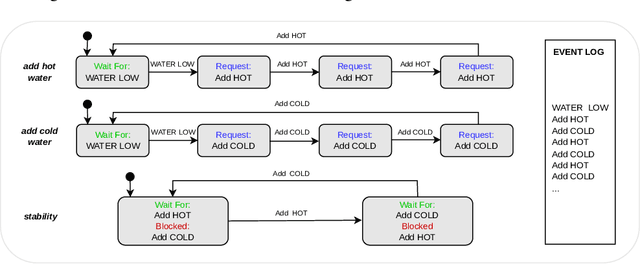



Deep reinforcement learning (DRL) has achieved groundbreaking successes in a wide variety of robotic applications. A natural consequence is the adoption of this paradigm for safety-critical tasks, where human safety and expensive hardware can be involved. In this context, it is crucial to optimize the performance of DRL-based agents while providing guarantees about their behavior. This paper presents a novel technique for incorporating domain-expert knowledge into a constrained DRL training loop. Our technique exploits the scenario-based programming paradigm, which is designed to allow specifying such knowledge in a simple and intuitive way. We validated our method on the popular robotic mapless navigation problem, in simulation, and on the actual platform. Our experiments demonstrate that using our approach to leverage expert knowledge dramatically improves the safety and the performance of the agent.
Verifying Learning-Based Robotic Navigation Systems
May 26, 2022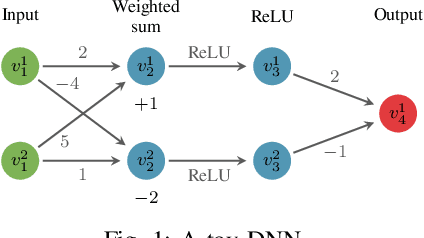


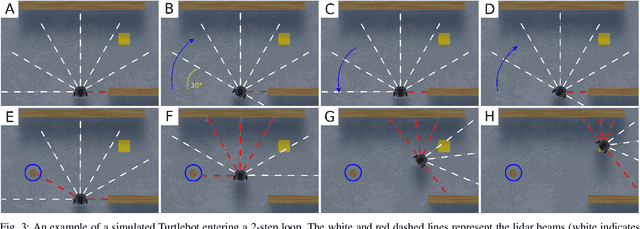
Deep reinforcement learning (DRL) has become a dominant deep-learning paradigm for various tasks in which complex policies are learned within reactive systems. In parallel, there has recently been significant research on verifying deep neural networks. However, to date, there has been little work demonstrating the use of modern verification tools on real, DRL-controlled systems. In this case-study paper, we attempt to begin bridging this gap, and focus on the important task of mapless robotic navigation -- a classic robotics problem, in which a robot, usually controlled by a DRL agent, needs to efficiently and safely navigate through an unknown arena towards a desired target. We demonstrate how modern verification engines can be used for effective model selection, i.e., the process of selecting the best available policy for the robot in question from a pool of candidate policies. Specifically, we use verification to detect and rule out policies that may demonstrate suboptimal behavior, such as collisions and infinite loops. We also apply verification to identify models with overly conservative behavior, thus allowing users to choose superior policies that are better at finding an optimal, shorter path to a target. To validate our work, we conducted extensive experiments on an actual robot, and confirmed that the suboptimal policies detected by our method were indeed flawed. We also compared our verification-driven approach to state-of-the-art gradient attacks, and our results demonstrate that gradient-based methods are inadequate in this setting. Our work is the first to demonstrate the use of DNN verification backends for recognizing suboptimal DRL policies in real-world robots, and for filtering out unwanted policies. We believe that the methods presented in this work can be applied to a large range of application domains that incorporate deep-learning-based agents.
Scenario-Assisted Deep Reinforcement Learning
Feb 09, 2022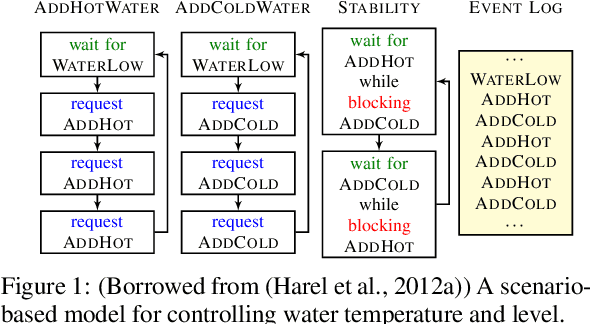
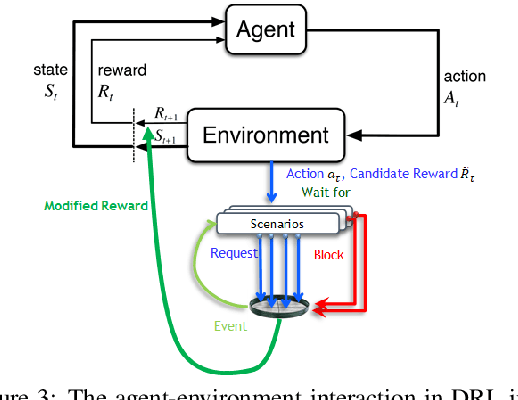

Deep reinforcement learning has proven remarkably useful in training agents from unstructured data. However, the opacity of the produced agents makes it difficult to ensure that they adhere to various requirements posed by human engineers. In this work-in-progress report, we propose a technique for enhancing the reinforcement learning training process (specifically, its reward calculation), in a way that allows human engineers to directly contribute their expert knowledge, making the agent under training more likely to comply with various relevant constraints. Moreover, our proposed approach allows formulating these constraints using advanced model engineering techniques, such as scenario-based modeling. This mix of black-box learning-based tools with classical modeling approaches could produce systems that are effective and efficient, but are also more transparent and maintainable. We evaluated our technique using a case-study from the domain of internet congestion control, obtaining promising results.
Expecting the Unexpected: Developing Autonomous-System Design Principles for Reacting to Unpredicted Events and Conditions
Jan 25, 2020When developing autonomous systems, engineers and other stakeholders make great effort to prepare the system for all foreseeable events and conditions. However, these systems are still bound to encounter events and conditions that were not considered at design time. For reasons like safety, cost, or ethics, it is often highly desired that these new situations be handled correctly upon first encounter. In this paper we first justify our position that there will always exist unpredicted events and conditions, driven among others by: new inventions in the real world; the diversity of world-wide system deployments and uses; and, the non-negligible probability that multiple seemingly unlikely events, which may be neglected at design time, will not only occur, but occur together. We then argue that despite this unpredictability property, handling these events and conditions is indeed possible. Hence, we offer and exemplify design principles that when applied in advance, can enable systems to deal, in the future, with unpredicted circumstances. We conclude with a discussion of how this work and a broader theoretical study of the unexpected can contribute toward a foundation of engineering principles for developing trustworthy next-generation autonomous systems.