 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study and Theoretical Explanation on Task-Level Model-Merging Collapse
Mar 10, 2026Model merging unifies independently fine-tuned LLMs from the same base, enabling reuse and integration of parallel development efforts without retraining. However, in practice we observe that merging does not always succeed: certain combinations of task-specialist models suffer from catastrophic performance degradation after merging. We refer to this failure mode as merging collapse. Intuitively, collapse arises when the learned representations or parameter adjustments for different tasks are fundamentally incompatible, so that merging forces destructive interference rather than synergy. In this paper, we identify and characterize the phenomenon of task-level merging collapse, where certain task combinations consistently trigger huge performance degradation across all merging methods. Through extensive experiments and statistical analysis, we demonstrate that representational incompatibility between tasks is strongly correlated with merging collapse, while parameter-space conflict metrics show minimal correlation, challenging conventional wisdom in model merging literature. We provide a theoretical explanation on this phenomenon through rate-distortion theory with a dimension-dependent bound, establishing fundamental limits on task mergeability regardless of methodology.
GUI-GENESIS: Automated Synthesis of Efficient Environments with Verifiable Rewards for GUI Agent Post-Training
Feb 15, 2026Post-training GUI agents in interactive environments is critical for developing generalization and long-horizon planning capabilities. However, training on real-world applications is hindered by high latency, poor reproducibility, and unverifiable rewards relying on noisy visual proxies. To address the limitations, we present GUI-GENESIS, the first framework to automatically synthesize efficient GUI training environments with verifiable rewards. GUI-GENESIS reconstructs real-world applications into lightweight web environments using multimodal code models and equips them with code-native rewards, executable assertions that provide deterministic reward signals and eliminate visual estimation noise. Extensive experiments show that GUI-GENESIS reduces environment latency by 10 times and costs by over $28,000 per epoch compared to training on real applications. Notably, agents trained with GUI-GENESIS outperform the base model by 14.54% and even real-world RL baselines by 3.27% on held-out real-world tasks. Finally, we observe that models can synthesize environments they cannot yet solve, highlighting a pathway for self-improving agents.
From User Interface to Agent Interface: Efficiency Optimization of UI Representations for LLM Agents
Dec 15, 2025
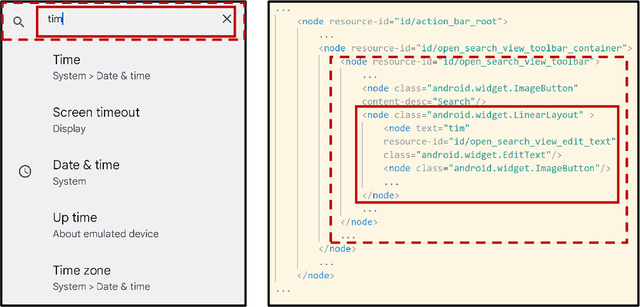
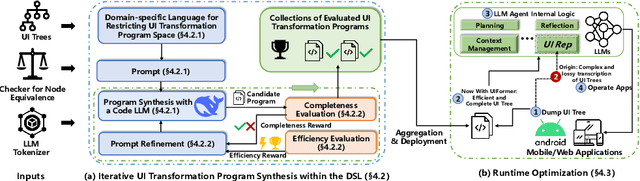
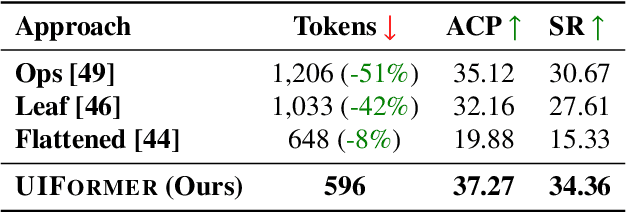
While Large Language Model (LLM) agents show great potential for automated UI navigation such as automated UI testing and AI assistants, their efficiency has been largely overlooked. Our motivating study reveals that inefficient UI representation creates a critical performance bottleneck. However, UI representation optimization, formulated as the task of automatically generating programs that transform UI representations, faces two unique challenges. First, the lack of Boolean oracles, which traditional program synthesis uses to decisively validate semantic correctness, poses a fundamental challenge to co-optimization of token efficiency and completeness. Second, the need to process large, complex UI trees as input while generating long, compositional transformation programs, making the search space vast and error-prone. Toward addressing the preceding limitations, we present UIFormer, the first automated optimization framework that synthesizes UI transformation programs by conducting constraint-based optimization with structured decomposition of the complex synthesis task. First, UIFormer restricts the program space using a domain-specific language (DSL) that captures UI-specific operations. Second, UIFormer conducts LLM-based iterative refinement with correctness and efficiency rewards, providing guidance for achieving the efficiency-completeness co-optimization. UIFormer operates as a lightweight plugin that applies transformation programs for seamless integration with existing LLM agents, requiring minimal modifications to their core logic. Evaluations across three UI navigation benchmarks spanning Android and Web platforms with five LLMs demonstrate that UIFormer achieves 48.7% to 55.8% token reduction with minimal runtime overhead while maintaining or improving agent performance. Real-world industry deployment at WeChat further validates the practical impact of UIFormer.
AppForge: From Assistant to Independent Developer - Are GPTs Ready for Software Development?
Oct 09, 2025



Large language models (LLMs) have demonstrated remarkable capability in function-level code generation tasks. Unlike isolated functions, real-world applications demand reasoning over the entire software system: developers must orchestrate how different components interact, maintain consistency across states over time, and ensure the application behaves correctly within the lifecycle and framework constraints. Yet, no existing benchmark adequately evaluates whether LLMs can bridge this gap and construct entire software systems from scratch. To address this gap, we propose APPFORGE, a benchmark consisting of 101 software development problems drawn from real-world Android apps. Given a natural language specification detailing the app functionality, a language model is tasked with implementing the functionality into an Android app from scratch. Developing an Android app from scratch requires understanding and coordinating app states, lifecycle management, and asynchronous operations, calling for LLMs to generate context-aware, robust, and maintainable code. To construct APPFORGE, we design a multi-agent system to automatically summarize the main functionalities from app documents and navigate the app to synthesize test cases validating the functional correctness of app implementation. Following rigorous manual verification by Android development experts, APPFORGE incorporates the test cases within an automated evaluation framework that enables reproducible assessment without human intervention, making it easily adoptable for future research. Our evaluation on 12 flagship LLMs show that all evaluated models achieve low effectiveness, with the best-performing model (GPT-5) developing only 18.8% functionally correct applications, highlighting fundamental limitations in current models' ability to handle complex, multi-component software engineering challenges.
Recent Advances in Large Langauge Model Benchmarks against Data Contamination: From Static to Dynamic Evaluation
Feb 23, 2025Data contamination has received increasing attention in the era of large language models (LLMs) due to their reliance on vast Internet-derived training corpora. To mitigate the risk of potential data contamination, LLM benchmarking has undergone a transformation from static to dynamic benchmarking. In this work, we conduct an in-depth analysis of existing static to dynamic benchmarking methods aimed at reducing data contamination risks. We first examine methods that enhance static benchmarks and identify their inherent limitations. We then highlight a critical gap-the lack of standardized criteria for evaluating dynamic benchmarks. Based on this observation, we propose a series of optimal design principles for dynamic benchmarking and analyze the limitations of existing dynamic benchmarks. This survey provides a concise yet comprehensive overview of recent advancements in data contamination research, offering valuable insights and a clear guide for future research efforts. We maintain a GitHub repository to continuously collect both static and dynamic benchmarking methods for LLMs. The repository can be found at this link.
Data and System Perspectives of Sustainable Artificial Intelligence
Jan 13, 2025Sustainable AI is a subfield of AI for concerning developing and using AI systems in ways of aiming to reduce environmental impact and achieve sustainability. Sustainable AI is increasingly important given that training of and inference with AI models such as large langrage models are consuming a large amount of computing power. In this article, we discuss current issues, opportunities and example solutions for addressing these issues, and future challenges to tackle, from the data and system perspectives, related to data acquisition, data processing, and AI model training and inference.
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
Foundation Model Engineering: Engineering Foundation Models Just as Engineering Software
Jul 11, 2024


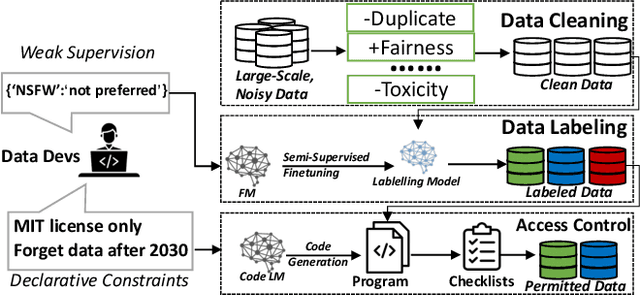
By treating data and models as the source code, Foundation Models (FMs) become a new type of software. Mirroring the concept of software crisis, the increasing complexity of FMs making FM crisis a tangible concern in the coming decade, appealing for new theories and methodologies from the field of software engineering. In this paper, we outline our vision of introducing Foundation Model (FM) engineering, a strategic response to the anticipated FM crisis with principled engineering methodologies. FM engineering aims to mitigate potential issues in FM development and application through the introduction of declarative, automated, and unified programming interfaces for both data and model management, reducing the complexities involved in working with FMs by providing a more structured and intuitive process for developers. Through the establishment of FM engineering, we aim to provide a robust, automated, and extensible framework that addresses the imminent challenges, and discovering new research opportunities for the software engineering field.