 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRROR: A Multi-Agent Framework with Iterative Adaptive Revision and Hierarchical Retrieval for Optimization Modeling in Operations Research
Feb 03, 2026Operations Research (OR) relies on expert-driven modeling-a slow and fragile process ill-suited to novel scenarios. While large language models (LLMs) can automatically translate natural language into optimization models, existing approaches either rely on costly post-training or employ multi-agent frameworks, yet most still lack reliable collaborative error correction and task-specific retrieval, often leading to incorrect outputs. We propose MIRROR, a fine-tuning-free, end-to-end multi-agent framework that directly translates natural language optimization problems into mathematical models and solver code. MIRROR integrates two core mechanisms: (1) execution-driven iterative adaptive revision for automatic error correction, and (2) hierarchical retrieval to fetch relevant modeling and coding exemplars from a carefully curated exemplar library. Experiments show that MIRROR outperforms existing methods on standard OR benchmarks, with notable results on complex industrial datasets such as IndustryOR and Mamo-ComplexLP. By combining precise external knowledge infusion with systematic error correction, MIRROR provides non-expert users with an efficient and reliable OR modeling solution, overcoming the fundamental limitations of general-purpose LLMs in expert optimization tasks.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
Decentralized Directed Collaboration for Personalized Federated Learning
May 28, 2024Personalized Federated Learning (PFL) is proposed to find the greatest personalized models for each client. To avoid the central failure and communication bottleneck in the server-based FL, we concentrate on the Decentralized Personalized Federated Learning (DPFL) that performs distributed model training in a Peer-to-Peer (P2P) manner. Most personalized works in DPFL are based on undirected and symmetric topologies, however, the data, computation and communication resources heterogeneity result in large variances in the personalized models, which lead the undirected aggregation to suboptimal personalized performance and unguaranteed convergence. To address these issues, we propose a directed collaboration DPFL framework by incorporating stochastic gradient push and partial model personalized, called \textbf{D}ecentralized \textbf{Fed}erated \textbf{P}artial \textbf{G}radient \textbf{P}ush (\textbf{DFedPGP}). It personalizes the linear classifier in the modern deep model to customize the local solution and learns a consensus representation in a fully decentralized manner. Clients only share gradients with a subset of neighbors based on the directed and asymmetric topologies, which guarantees flexible choices for resource efficiency and better convergence. Theoretically, we show that the proposed DFedPGP achieves a superior convergence rate of $\mathcal{O}(\frac{1}{\sqrt{T}})$ in the general non-convex setting, and prove the tighter connectivity among clients will speed up the convergence. The proposed method achieves state-of-the-art (SOTA) accuracy in both data and computation heterogeneity scenarios, demonstrating the efficiency of the directed collaboration and partial gradient push.
A General and Efficient Federated Split Learning with Pre-trained Image Transformers for Heterogeneous Data
Mar 24, 2024Federated Split Learning (FSL) is a promising distributed learning paradigm in practice, which gathers the strengths of both Federated Learning (FL) and Split Learning (SL) paradigms, to ensure model privacy while diminishing the resource overhead of each client, especially on large transformer models in a resource-constrained environment, e.g., Internet of Things (IoT). However, almost all works merely investigate the performance with simple neural network models in FSL. Despite the minor efforts focusing on incorporating Vision Transformers (ViT) as model architectures, they train ViT from scratch, thereby leading to enormous training overhead in each device with limited resources. Therefore, in this paper, we harness Pre-trained Image Transformers (PITs) as the initial model, coined FES-PIT, to accelerate the training process and improve model robustness. Furthermore, we propose FES-PTZO to hinder the gradient inversion attack, especially having the capability compatible with black-box scenarios, where the gradient information is unavailable. Concretely, FES-PTZO approximates the server gradient by utilizing a zeroth-order (ZO) optimization, which replaces the backward propagation with just one forward process. Empirically, we are the first to provide a systematic evaluation of FSL methods with PITs in real-world datasets, different partial device participations, and heterogeneous data splits. Our experiments verify the effectiveness of our algorithms.
Efficient Federated Prompt Tuning for Black-box Large Pre-trained Models
Oct 04, 2023



With the blowout development of pre-trained models (PTMs), the efficient tuning of these models for diverse downstream applications has emerged as a pivotal research concern. Although recent investigations into prompt tuning have provided promising avenues, three salient challenges persist: (1) memory constraint: the continuous growth in the size of open-source PTMs renders fine-tuning, even a fraction of their parameters, challenging for many practitioners. (2) model privacy: existing PTMs often function as public API services, with their parameters inaccessible for effective or tailored fine-tuning. (3) data privacy: the fine-tuning of PTMs necessitates high-quality datasets, which are typically localized and not shared to public. To optimally harness each local dataset while navigating memory constraints and preserving privacy, we propose Federated Black-Box Prompt Tuning (Fed-BBPT). This innovative approach eschews reliance on parameter architectures and private dataset access, instead capitalizing on a central server that aids local users in collaboratively training a prompt generator through regular aggregation. Local users leverage API-driven learning via a zero-order optimizer, obviating the need for PTM deployment. Relative to extensive fine-tuning, Fed-BBPT proficiently sidesteps memory challenges tied to PTM storage and fine-tuning on local machines, tapping into comprehensive, high-quality, yet private training datasets. A thorough evaluation across 40 datasets spanning CV and NLP tasks underscores the robustness of our proposed model.
Towards More Suitable Personalization in Federated Learning via Decentralized Partial Model Training
May 24, 2023
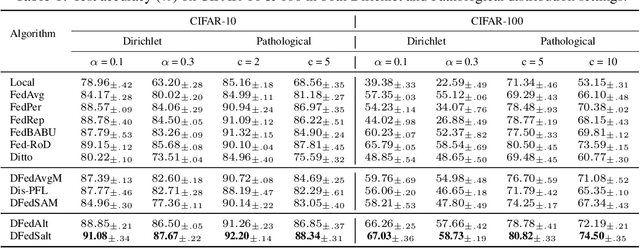

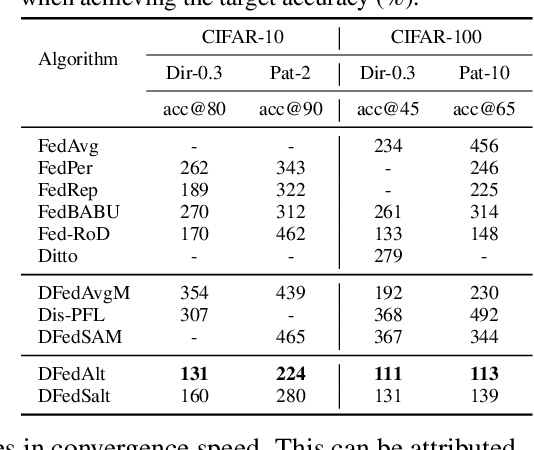
Personalized federated learning (PFL) aims to produce the greatest personalized model for each client to face an insurmountable problem--data heterogeneity in real FL systems. However, almost all existing works have to face large communication burdens and the risk of disruption if the central server fails. Only limited efforts have been used in a decentralized way but still suffers from inferior representation ability due to sharing the full model with its neighbors. Therefore, in this paper, we propose a personalized FL framework with a decentralized partial model training called DFedAlt. It personalizes the "right" components in the modern deep models by alternately updating the shared and personal parameters to train partially personalized models in a peer-to-peer manner. To further promote the shared parameters aggregation process, we propose DFedSalt integrating the local Sharpness Aware Minimization (SAM) optimizer to update the shared parameters. It adds proper perturbation in the direction of the gradient to overcome the shared model inconsistency across clients. Theoretically, we provide convergence analysis of both algorithms in the general non-convex setting for decentralized partial model training in PFL. Our experiments on several real-world data with various data partition settings demonstrate that (i) decentralized training is more suitable for partial personalization, which results in state-of-the-art (SOTA) accuracy compared with the SOTA PFL baselines; (ii) the shared parameters with proper perturbation make partial personalized FL more suitable for decentralized training, where DFedSalt achieves most competitive performance.
Towards the Flatter Landscape and Better Generalization in Federated Learning under Client-level Differential Privacy
May 02, 2023

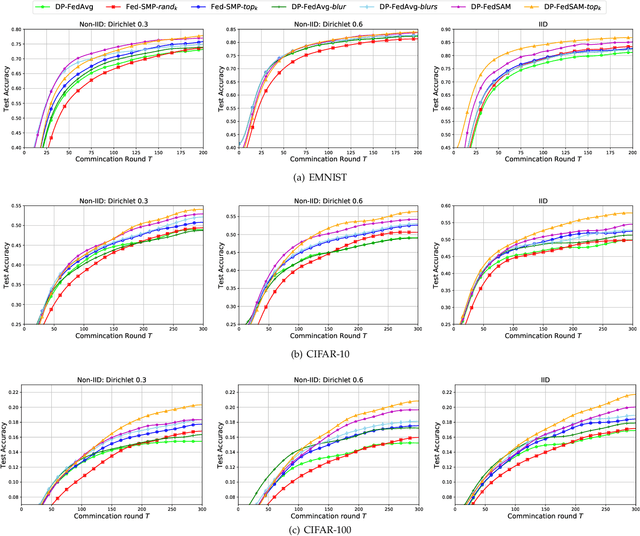

To defend the inference attacks and mitigate the sensitive information leakages in Federated Learning (FL), client-level Differentially Private FL (DPFL) is the de-facto standard for privacy protection by clipping local updates and adding random noise. However, existing DPFL methods tend to make a sharp loss landscape and have poor weight perturbation robustness, resulting in severe performance degradation. To alleviate these issues, we propose a novel DPFL algorithm named DP-FedSAM, which leverages gradient perturbation to mitigate the negative impact of DP. Specifically, DP-FedSAM integrates Sharpness Aware Minimization (SAM) optimizer to generate local flatness models with improved stability and weight perturbation robustness, which results in the small norm of local updates and robustness to DP noise, thereby improving the performance. To further reduce the magnitude of random noise while achieving better performance, we propose DP-FedSAM-$top_k$ by adopting the local update sparsification technique. From the theoretical perspective, we present the convergence analysis to investigate how our algorithms mitigate the performance degradation induced by DP. Meanwhile, we give rigorous privacy guarantees with R\'enyi DP, the sensitivity analysis of local updates, and generalization analysis. At last, we empirically confirm that our algorithms achieve state-of-the-art (SOTA) performance compared with existing SOTA baselines in DPFL.
Efficient Federated Learning with Enhanced Privacy via Lottery Ticket Pruning in Edge Computing
May 02, 2023
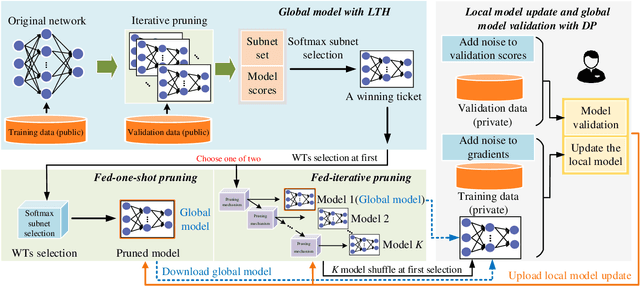
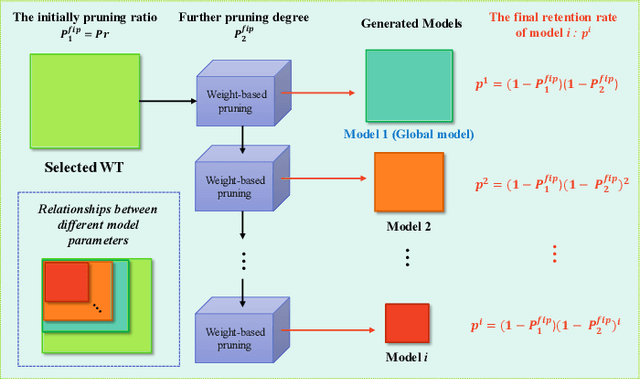

Federated learning (FL) is a collaborative learning paradigm for decentralized private data from mobile terminals (MTs). However, it suffers from issues in terms of communication, resource of MTs, and privacy. Existing privacy-preserving FL methods usually adopt the instance-level differential privacy (DP), which provides a rigorous privacy guarantee but with several bottlenecks: severe performance degradation, transmission overhead, and resource constraints of edge devices such as MTs. To overcome these drawbacks, we propose Fed-LTP, an efficient and privacy-enhanced FL framework with \underline{\textbf{L}}ottery \underline{\textbf{T}}icket \underline{\textbf{H}}ypothesis (LTH) and zero-concentrated D\underline{\textbf{P}} (zCDP). It generates a pruned global model on the server side and conducts sparse-to-sparse training from scratch with zCDP on the client side. On the server side, two pruning schemes are proposed: (i) the weight-based pruning (LTH) determines the pruned global model structure; (ii) the iterative pruning further shrinks the size of the pruned model's parameters. Meanwhile, the performance of Fed-LTP is also boosted via model validation based on the Laplace mechanism. On the client side, we use sparse-to-sparse training to solve the resource-constraints issue and provide tighter privacy analysis to reduce the privacy budget. We evaluate the effectiveness of Fed-LTP on several real-world datasets in both independent and identically distributed (IID) and non-IID settings. The results clearly confirm the superiority of Fed-LTP over state-of-the-art (SOTA) methods in communication, computation, and memory efficiencies while realizing a better utility-privacy trade-off.
Make Landscape Flatter in Differentially Private Federated Learning
Mar 20, 2023



To defend the inference attacks and mitigate the sensitive information leakages in Federated Learning (FL), client-level Differentially Private FL (DPFL) is the de-facto standard for privacy protection by clipping local updates and adding random noise. However, existing DPFL methods tend to make a sharper loss landscape and have poorer weight perturbation robustness, resulting in severe performance degradation. To alleviate these issues, we propose a novel DPFL algorithm named DP-FedSAM, which leverages gradient perturbation to mitigate the negative impact of DP. Specifically, DP-FedSAM integrates Sharpness Aware Minimization (SAM) optimizer to generate local flatness models with better stability and weight perturbation robustness, which results in the small norm of local updates and robustness to DP noise, thereby improving the performance. From the theoretical perspective, we analyze in detail how DP-FedSAM mitigates the performance degradation induced by DP. Meanwhile, we give rigorous privacy guarantees with R\'enyi DP and present the sensitivity analysis of local updates. At last, we empirically confirm that our algorithm achieves state-of-the-art (SOTA) performance compared with existing SOTA baselines in DPFL.