 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Federated Learning with Enhanced Privacy via Lottery Ticket Pruning in Edge Computing
Paper and Code
May 02, 2023
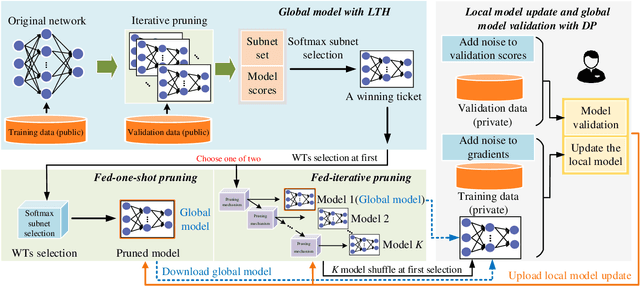
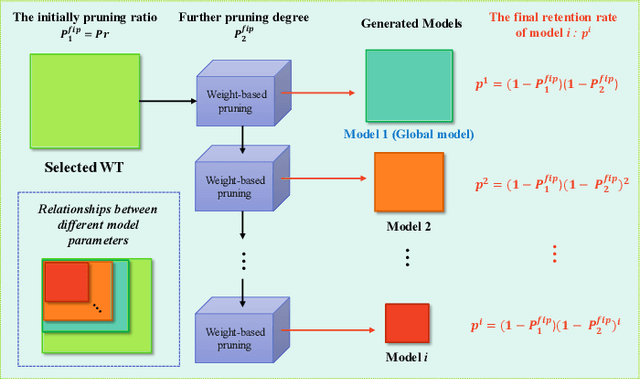

Federated learning (FL) is a collaborative learning paradigm for decentralized private data from mobile terminals (MTs). However, it suffers from issues in terms of communication, resource of MTs, and privacy. Existing privacy-preserving FL methods usually adopt the instance-level differential privacy (DP), which provides a rigorous privacy guarantee but with several bottlenecks: severe performance degradation, transmission overhead, and resource constraints of edge devices such as MTs. To overcome these drawbacks, we propose Fed-LTP, an efficient and privacy-enhanced FL framework with \underline{\textbf{L}}ottery \underline{\textbf{T}}icket \underline{\textbf{H}}ypothesis (LTH) and zero-concentrated D\underline{\textbf{P}} (zCDP). It generates a pruned global model on the server side and conducts sparse-to-sparse training from scratch with zCDP on the client side. On the server side, two pruning schemes are proposed: (i) the weight-based pruning (LTH) determines the pruned global model structure; (ii) the iterative pruning further shrinks the size of the pruned model's parameters. Meanwhile, the performance of Fed-LTP is also boosted via model validation based on the Laplace mechanism. On the client side, we use sparse-to-sparse training to solve the resource-constraints issue and provide tighter privacy analysis to reduce the privacy budget. We evaluate the effectiveness of Fed-LTP on several real-world datasets in both independent and identically distributed (IID) and non-IID settings. The results clearly confirm the superiority of Fed-LTP over state-of-the-art (SOTA) methods in communication, computation, and memory efficiencies while realizing a better utility-privacy trade-off.