 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs Overkill for Databases?: A Study on the Finiteness of SQL
Mar 26, 2026Translating natural language to SQL for data retrieval has become more accessible thanks to code generation LLMs. But how hard is it to generate SQL code? While databases can become unbounded in complexity, the complexity of queries is bounded by real life utility and human needs. With a sample of 376 databases, we show that SQL queries, as translations of natural language questions are finite in practical complexity. There is no clear monotonic relationship between increases in database table count and increases in complexity of SQL queries. In their template forms, SQL queries follow a Power Law-like distribution of frequency where 70% of our tested queries can be covered with just 13% of all template types, indicating that the high majority of SQL queries are predictable. This suggests that while LLMs for code generation can be useful, in the domain of database access, they may be operating in a narrow, highly formulaic space where templates could be safer, cheaper, and auditable.
Agent Bain vs. Agent McKinsey: A New Text-to-SQL Benchmark for the Business Domain
Oct 08, 2025In the business domain, where data-driven decision making is crucial, text-to-SQL is fundamental for easy natural language access to structured data. While recent LLMs have achieved strong performance in code generation, existing text-to-SQL benchmarks remain focused on factual retrieval of past records. We introduce CORGI, a new benchmark specifically designed for real-world business contexts. CORGI is composed of synthetic databases inspired by enterprises such as Doordash, Airbnb, and Lululemon. It provides questions across four increasingly complex categories of business queries: descriptive, explanatory, predictive, and recommendational. This challenge calls for causal reasoning, temporal forecasting, and strategic recommendation, reflecting multi-level and multi-step agentic intelligence. We find that LLM performance drops on high-level questions, struggling to make accurate predictions and offer actionable plans. Based on execution success rate, the CORGI benchmark is about 21\% more difficult than the BIRD benchmark. This highlights the gap between popular LLMs and the need for real-world business intelligence. We release a public dataset and evaluation framework, and a website for public submissions.
Cheaper, Better, Faster, Stronger: Robust Text-to-SQL without Chain-of-Thought or Fine-Tuning
May 20, 2025LLMs are effective at code generation tasks like text-to-SQL, but is it worth the cost? Many state-of-the-art approaches use non-task-specific LLM techniques including Chain-of-Thought (CoT), self-consistency, and fine-tuning. These methods can be costly at inference time, sometimes requiring over a hundred LLM calls with reasoning, incurring average costs of up to \$0.46 per query, while fine-tuning models can cost thousands of dollars. We introduce "N-rep" consistency, a more cost-efficient text-to-SQL approach that achieves similar BIRD benchmark scores as other more expensive methods, at only \$0.039 per query. N-rep leverages multiple representations of the same schema input to mitigate weaknesses in any single representation, making the solution more robust and allowing the use of smaller and cheaper models without any reasoning or fine-tuning. To our knowledge, N-rep is the best-performing text-to-SQL approach in its cost range.
Do Chinese models speak Chinese languages?
Mar 31, 2025
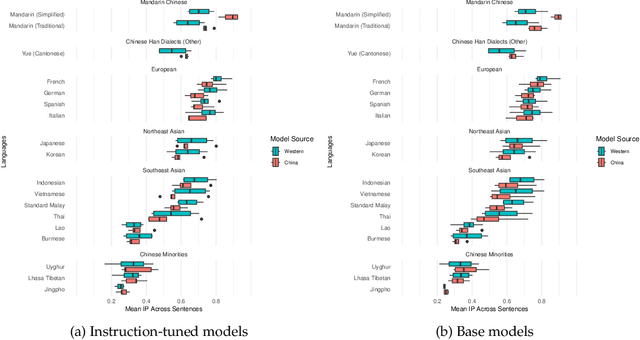


The release of top-performing open-weight LLMs has cemented China's role as a leading force in AI development. Do these models support languages spoken in China? Or do they speak the same languages as Western models? Comparing multilingual capabilities is important for two reasons. First, language ability provides insights into pre-training data curation, and thus into resource allocation and development priorities. Second, China has a long history of explicit language policy, varying between inclusivity of minority languages and a Mandarin-first policy. To test whether Chinese LLMs today reflect an agenda about China's languages, we test performance of Chinese and Western open-source LLMs on Asian regional and Chinese minority languages. Our experiments on Information Parity and reading comprehension show Chinese models' performance across these languages correlates strongly (r=0.93) with Western models', with the sole exception being better Mandarin. Sometimes, Chinese models cannot identify languages spoken by Chinese minorities such as Kazakh and Uyghur, even though they are good at French and German. These results provide a window into current development priorities, suggest options for future development, and indicate guidance for end users.
How Chinese are Chinese Language Models? The Puzzling Lack of Language Policy in China's LLMs
Jul 12, 2024Contemporary language models are increasingly multilingual, but Chinese LLM developers must navigate complex political and business considerations of language diversity. Language policy in China aims at influencing the public discourse and governing a multi-ethnic society, and has gradually transitioned from a pluralist to a more assimilationist approach since 1949. We explore the impact of these influences on current language technology. We evaluate six open-source multilingual LLMs pre-trained by Chinese companies on 18 languages, spanning a wide range of Chinese, Asian, and Anglo-European languages. Our experiments show Chinese LLMs performance on diverse languages is indistinguishable from international LLMs. Similarly, the models' technical reports also show lack of consideration for pretraining data language coverage except for English and Mandarin Chinese. Examining Chinese AI policy, model experiments, and technical reports, we find no sign of any consistent policy, either for or against, language diversity in China's LLM development. This leaves a puzzling fact that while China regulates both the languages people use daily as well as language model development, they do not seem to have any policy on the languages in language models.
Efficient Few-Shot Learning Without Prompts
Sep 22, 2022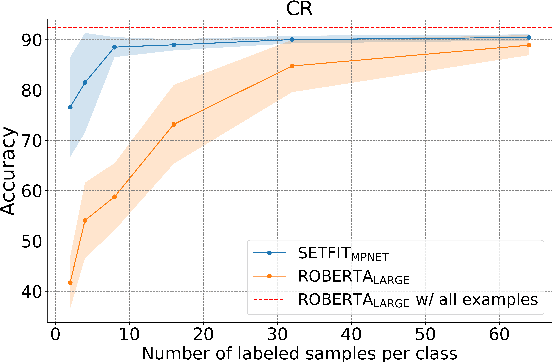

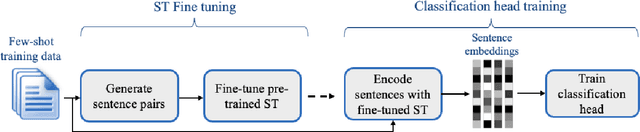
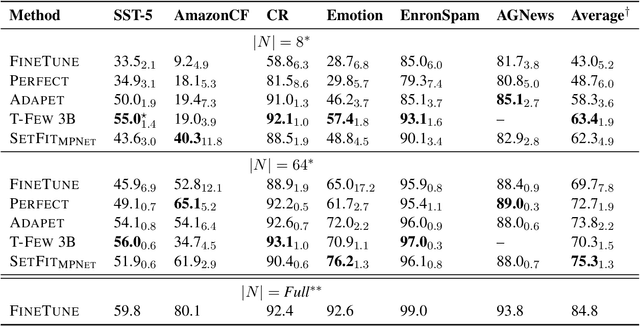
Recent few-shot methods, such as parameter-efficient fine-tuning (PEFT) and pattern exploiting training (PET), have achieved impressive results in label-scarce settings. However, they are difficult to employ since they are subject to high variability from manually crafted prompts, and typically require billion-parameter language models to achieve high accuracy. To address these shortcomings, we propose SetFit (Sentence Transformer Fine-tuning), an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers (ST). SetFit works by first fine-tuning a pretrained ST on a small number of text pairs, in a contrastive Siamese manner. The resulting model is then used to generate rich text embeddings, which are used to train a classification head. This simple framework requires no prompts or verbalizers, and achieves high accuracy with orders of magnitude less parameters than existing techniques. Our experiments show that SetFit obtains comparable results with PEFT and PET techniques, while being an order of magnitude faster to train. We also show that SetFit can be applied in multilingual settings by simply switching the ST body. Our code is available at https://github.com/huggingface/setfit and our datasets at https://huggingface.co/setfit .