Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Speculative Decoding using Dynamic Speculation Length
Paper and Code
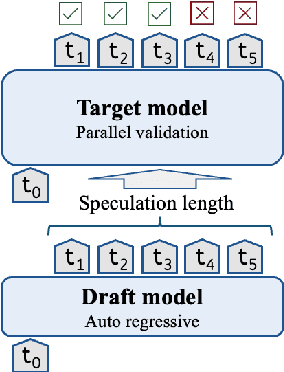


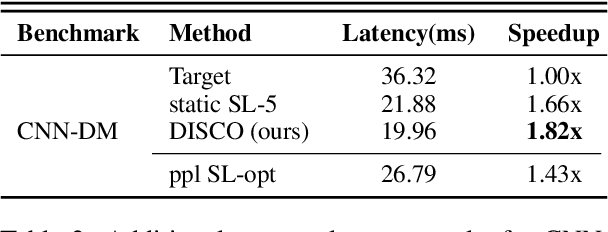
Speculative decoding is a promising method for reducing the inference latency of large language models. The effectiveness of the method depends on the speculation length (SL) - the number of tokens generated by the draft model at each iteration. The vast majority of speculative decoding approaches use the same SL for all iterations. In this work, we show that this practice is suboptimal. We introduce DISCO, a DynamIc SpeCulation length Optimization method that uses a classifier to dynamically adjust the SL at each iteration, while provably preserving the decoding quality. Experiments with four benchmarks demonstrate average speedup gains of 10.3% relative to our best baselines.
View paper on