 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreSumm: Predicting Summarization Performance Without Summarizing
Apr 07, 2025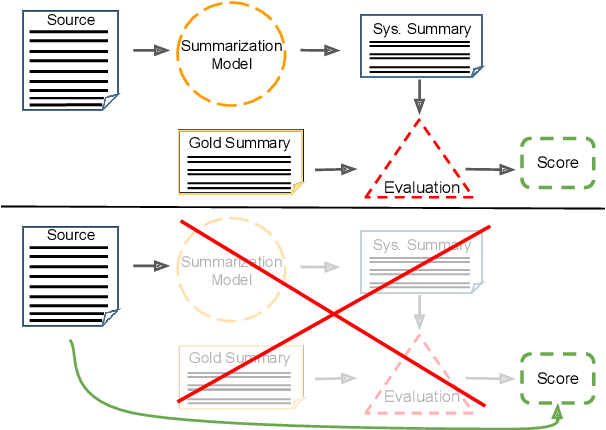
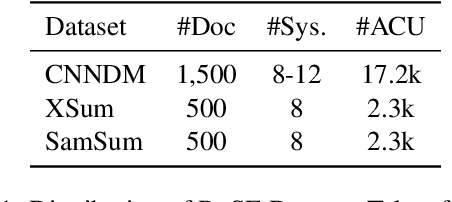
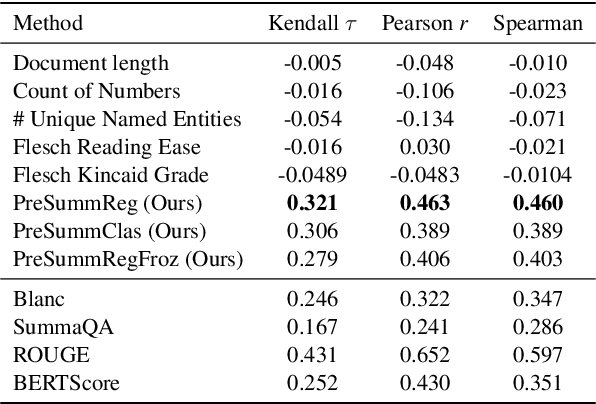
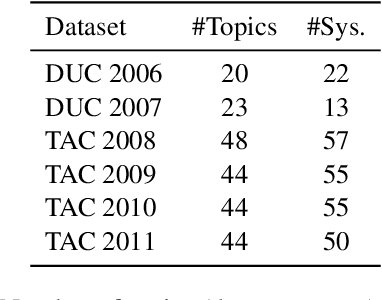
Despite recent advancements in automatic summarization, state-of-the-art models do not summarize all documents equally well, raising the question: why? While prior research has extensively analyzed summarization models, little attention has been given to the role of document characteristics in influencing summarization performance. In this work, we explore two key research questions. First, do documents exhibit consistent summarization quality across multiple systems? If so, can we predict a document's summarization performance without generating a summary? We answer both questions affirmatively and introduce PreSumm, a novel task in which a system predicts summarization performance based solely on the source document. Our analysis sheds light on common properties of documents with low PreSumm scores, revealing that they often suffer from coherence issues, complex content, or a lack of a clear main theme. In addition, we demonstrate PreSumm's practical utility in two key applications: improving hybrid summarization workflows by identifying documents that require manual summarization and enhancing dataset quality by filtering outliers and noisy documents. Overall, our findings highlight the critical role of document properties in summarization performance and offer insights into the limitations of current systems that could serve as the basis for future improvements.
The Power of Summary-Source Alignments
Jun 02, 2024Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by text generation. In this context, alignment of corresponding sentences between a reference summary and its source documents has been leveraged to generate training data for some of the component tasks. Yet, this enabling alignment step has usually been applied heuristically on the sentence level on a limited number of subtasks. In this paper, we propose extending the summary-source alignment framework by (1) applying it at the more fine-grained proposition span level, (2) annotating alignment manually in a multi-document setup, and (3) revealing the great potential of summary-source alignments to yield several datasets for at least six different tasks. Specifically, for each of the tasks, we release a manually annotated test set that was derived automatically from the alignment annotation. We also release development and train sets in the same way, but from automatically derived alignments. Using the datasets, each task is demonstrated with baseline models and corresponding evaluation metrics to spur future research on this broad challenge.
OpenAsp: A Benchmark for Multi-document Open Aspect-based Summarization
Dec 07, 2023
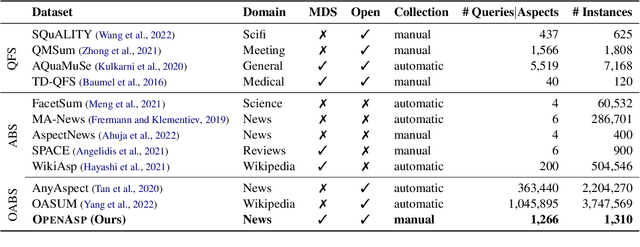
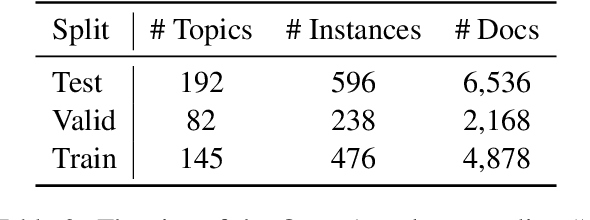
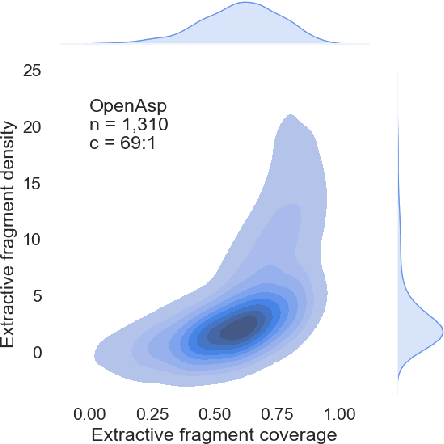
The performance of automatic summarization models has improved dramatically in recent years. Yet, there is still a gap in meeting specific information needs of users in real-world scenarios, particularly when a targeted summary is sought, such as in the useful aspect-based summarization setting targeted in this paper. Previous datasets and studies for this setting have predominantly concentrated on a limited set of pre-defined aspects, focused solely on single document inputs, or relied on synthetic data. To advance research on more realistic scenarios, we introduce OpenAsp, a benchmark for multi-document \textit{open} aspect-based summarization. This benchmark is created using a novel and cost-effective annotation protocol, by which an open aspect dataset is derived from existing generic multi-document summarization datasets. We analyze the properties of OpenAsp showcasing its high-quality content. Further, we show that the realistic open-aspect setting realized in OpenAsp poses a challenge for current state-of-the-art summarization models, as well as for large language models.
Controlled Text Reduction
Oct 24, 2022Producing a reduced version of a source text, as in generic or focused summarization, inherently involves two distinct subtasks: deciding on targeted content and generating a coherent text conveying it. While some popular approaches address summarization as a single end-to-end task, prominent works support decomposed modeling for individual subtasks. Further, semi-automated text reduction is also very appealing, where users may identify targeted content while models would generate a corresponding coherent summary. In this paper, we focus on the second subtask, of generating coherent text given pre-selected content. Concretely, we formalize \textit{Controlled Text Reduction} as a standalone task, whose input is a source text with marked spans of targeted content ("highlighting"). A model then needs to generate a coherent text that includes all and only the target information. We advocate the potential of such models, both for modular fully-automatic summarization, as well as for semi-automated human-in-the-loop use cases. Facilitating proper research, we crowdsource high-quality dev and test datasets for the task. Further, we automatically generate a larger "silver" training dataset from available summarization benchmarks, leveraging a pretrained summary-source alignment model. Finally, employing these datasets, we present a supervised baseline model, showing promising results and insightful analyses.
How "Multi" is Multi-Document Summarization?
Oct 23, 2022



The task of multi-document summarization (MDS) aims at models that, given multiple documents as input, are able to generate a summary that combines disperse information, originally spread across these documents. Accordingly, it is expected that both reference summaries in MDS datasets, as well as system summaries, would indeed be based on such dispersed information. In this paper, we argue for quantifying and assessing this expectation. To that end, we propose an automated measure for evaluating the degree to which a summary is ``disperse'', in the sense of the number of source documents needed to cover its content. We apply our measure to empirically analyze several popular MDS datasets, with respect to their reference summaries, as well as the output of state-of-the-art systems. Our results show that certain MDS datasets barely require combining information from multiple documents, where a single document often covers the full summary content. Overall, we advocate using our metric for assessing and improving the degree to which summarization datasets require combining multi-document information, and similarly how summarization models actually meet this challenge. Our code is available in https://github.com/ariecattan/multi_mds.
A Proposition-Level Clustering Approach for Multi-Document Summarization
Dec 16, 2021
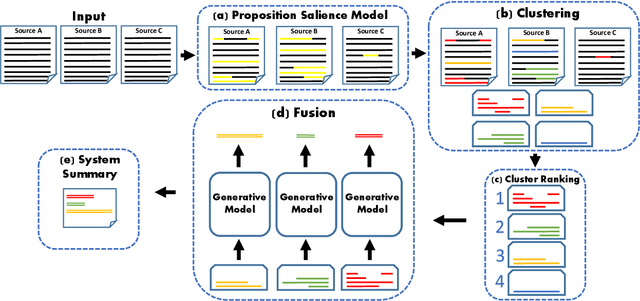

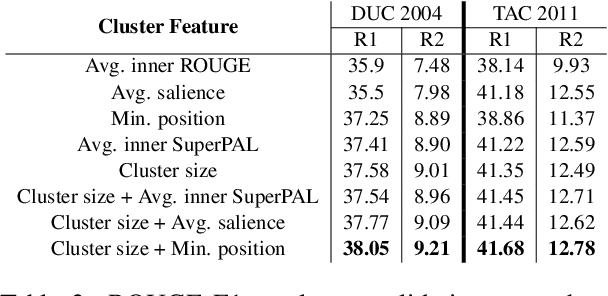
Text clustering methods were traditionally incorporated into multi-document summarization (MDS) as a means for coping with considerable information repetition. Clusters were leveraged to indicate information saliency and to avoid redundancy. These methods focused on clustering sentences, even though closely related sentences also usually contain non-aligning information. In this work, we revisit the clustering approach, grouping together propositions for more precise information alignment. Specifically, our method detects salient propositions, clusters them into paraphrastic clusters, and generates a representative sentence for each cluster by fusing its propositions. Our summarization method improves over the previous state-of-the-art MDS method in the DUC 2004 and TAC 2011 datasets, both in automatic ROUGE scores and human preference.
Extending Multi-Text Sentence Fusion Resources via Pyramid Annotations
Oct 09, 2021
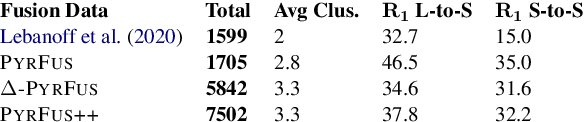


NLP models that compare or consolidate information across multiple documents often struggle when challenged with recognizing substantial information redundancies across the texts. For example, in multi-document summarization it is crucial to identify salient information across texts and then generate a non-redundant summary, while facing repeated and usually differently-phrased salient content. To facilitate researching such challenges, the sentence-level task of \textit{sentence fusion} was proposed, yet previous datasets for this task were very limited in their size and scope. In this paper, we revisit and substantially extend previous dataset creation efforts. With careful modifications, relabeling and employing complementing data sources, we were able to triple the size of a notable earlier dataset. Moreover, we show that our extended version uses more representative texts for multi-document tasks and provides a larger and more diverse training set, which substantially improves model training.
QA-Align: Representing Cross-Text Content Overlap by Aligning Question-Answer Propositions
Sep 26, 2021
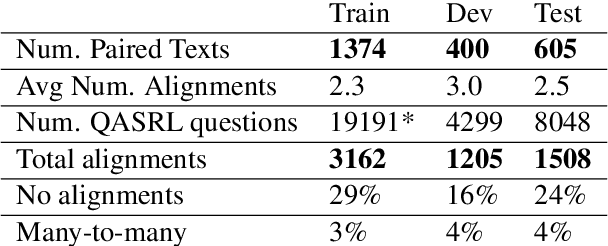
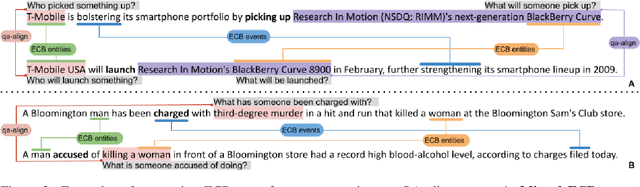
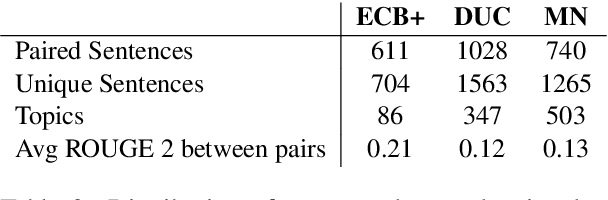
Multi-text applications, such as multi-document summarization, are typically required to model redundancies across related texts. Current methods confronting consolidation struggle to fuse overlapping information. In order to explicitly represent content overlap, we propose to align predicate-argument relations across texts, providing a potential scaffold for information consolidation. We go beyond clustering coreferring mentions, and instead model overlap with respect to redundancy at a propositional level, rather than merely detecting shared referents. Our setting exploits QA-SRL, utilizing question-answer pairs to capture predicate-argument relations, facilitating laymen annotation of cross-text alignments. We employ crowd-workers for constructing a dataset of QA-based alignments, and present a baseline QA alignment model trained over our dataset. Analyses show that our new task is semantically challenging, capturing content overlap beyond lexical similarity and complements cross-document coreference with proposition-level links, offering potential use for downstream tasks.
iFacetSum: Coreference-based Interactive Faceted Summarization for Multi-Document Exploration
Sep 23, 2021

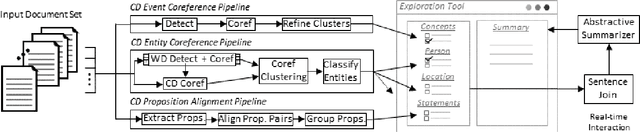
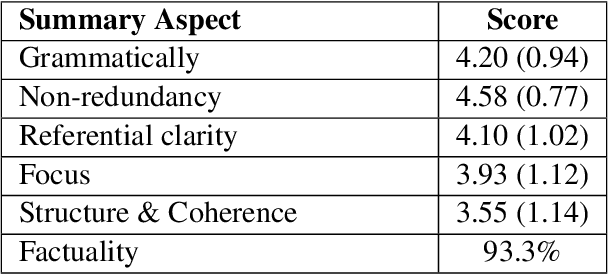
We introduce iFacetSum, a web application for exploring topical document sets. iFacetSum integrates interactive summarization together with faceted search, by providing a novel faceted navigation scheme that yields abstractive summaries for the user's selections. This approach offers both a comprehensive overview as well as concise details regarding subtopics of choice. Fine-grained facets are automatically produced based on cross-document coreference pipelines, rendering generic concepts, entities and statements surfacing in the source texts. We analyze the effectiveness of our application through small-scale user studies, which suggest the usefulness of our approach.
SuperPAL: Supervised Proposition ALignment for Multi-Document Summarization and Derivative Sub-Tasks
Sep 01, 2020



Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by generation. While alignment of spans between reference summaries and source documents has been leveraged for training component tasks, the underlying alignment step was never independently addressed or evaluated. We advocate developing high quality source-reference alignment algorithms, that can be applied to recent large-scale datasets to obtain useful "silver", i.e. approximate, training data. As a first step, we present an annotation methodology by which we create gold standard development and test sets for summary-source alignment, and suggest its utility for tuning and evaluating effective alignment algorithms, as well as for properly evaluating MDS subtasks. Second, we introduce a new large-scale alignment dataset for training, with which an automatic alignment model was trained. This aligner achieves higher coherency with the reference summary than previous aligners used for summarization, and gets significantly higher ROUGE results when replacing a simpler aligner in a competitive summarization model. Finally, we release three additional datasets (for salience, clustering and generation), naturally derived from our alignment datasets. Furthermore, these datasets can be derived from any summarization dataset automatically after extracting alignments with our trained aligner. Hence, they can be utilized for training summarization sub-tasks.