 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Summary-Source Alignments
Jun 02, 2024Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by text generation. In this context, alignment of corresponding sentences between a reference summary and its source documents has been leveraged to generate training data for some of the component tasks. Yet, this enabling alignment step has usually been applied heuristically on the sentence level on a limited number of subtasks. In this paper, we propose extending the summary-source alignment framework by (1) applying it at the more fine-grained proposition span level, (2) annotating alignment manually in a multi-document setup, and (3) revealing the great potential of summary-source alignments to yield several datasets for at least six different tasks. Specifically, for each of the tasks, we release a manually annotated test set that was derived automatically from the alignment annotation. We also release development and train sets in the same way, but from automatically derived alignments. Using the datasets, each task is demonstrated with baseline models and corresponding evaluation metrics to spur future research on this broad challenge.
Multi-Review Fusion-in-Context
Mar 31, 2024


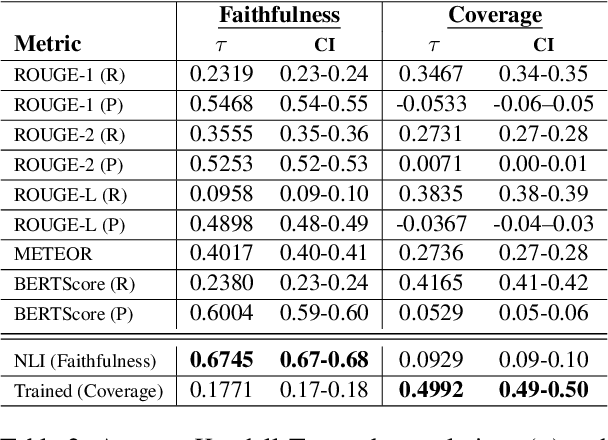
Grounded text generation, encompassing tasks such as long-form question-answering and summarization, necessitates both content selection and content consolidation. Current end-to-end methods are difficult to control and interpret due to their opaqueness. Accordingly, recent works have proposed a modular approach, with separate components for each step. Specifically, we focus on the second subtask, of generating coherent text given pre-selected content in a multi-document setting. Concretely, we formalize Fusion-in-Context (FiC) as a standalone task, whose input consists of source texts with highlighted spans of targeted content. A model then needs to generate a coherent passage that includes all and only the target information. Our work includes the development of a curated dataset of 1000 instances in the reviews domain, alongside a novel evaluation framework for assessing the faithfulness and coverage of highlights, which strongly correlate to human judgment. Several baseline models exhibit promising outcomes and provide insightful analyses. This study lays the groundwork for further exploration of modular text generation in the multi-document setting, offering potential improvements in the quality and reliability of generated content. Our benchmark, FuseReviews, including the dataset, evaluation framework, and designated leaderboard, can be found at https://fusereviews.github.io/.
Identifying Helpful Sentences in Product Reviews
May 05, 2021



In recent years online shopping has gained momentum and became an important venue for customers wishing to save time and simplify their shopping process. A key advantage of shopping online is the ability to read what other customers are saying about products of interest. In this work, we aim to maintain this advantage in situations where extreme brevity is needed, for example, when shopping by voice. We suggest a novel task of extracting a single representative helpful sentence from a set of reviews for a given product. The selected sentence should meet two conditions: first, it should be helpful for a purchase decision and second, the opinion it expresses should be supported by multiple reviewers. This task is closely related to the task of Multi Document Summarization in the product reviews domain but differs in its objective and its level of conciseness. We collect a dataset in English of sentence helpfulness scores via crowd-sourcing and demonstrate its reliability despite the inherent subjectivity involved. Next, we describe a complete model that extracts representative helpful sentences with positive and negative sentiment towards the product and demonstrate that it outperforms several baselines.
Massive Multi-Document Summarization of Product Reviews with Weak Supervision
Jul 22, 2020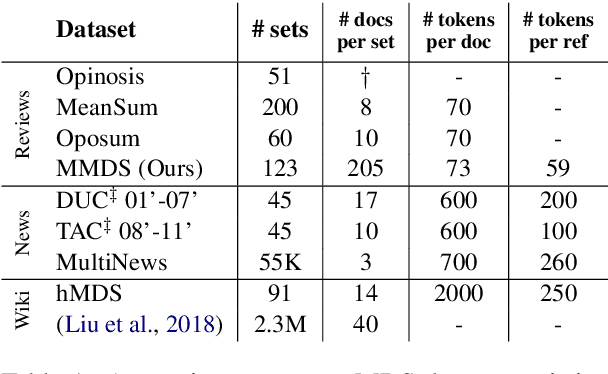
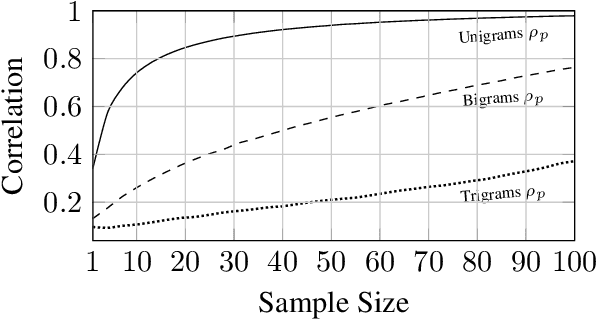
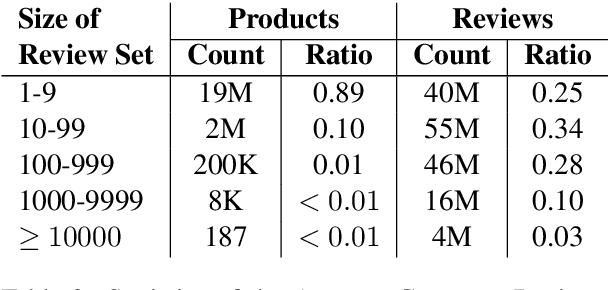

Product reviews summarization is a type of Multi-Document Summarization (MDS) task in which the summarized document sets are often far larger than in traditional MDS (up to tens of thousands of reviews). We highlight this difference and coin the term "Massive Multi-Document Summarization" (MMDS) to denote an MDS task that involves hundreds of documents or more. Prior work on product reviews summarization considered small samples of the reviews, mainly due to the difficulty of handling massive document sets. We show that summarizing small samples can result in loss of important information and provide misleading evaluation results. We propose a schema for summarizing a massive set of reviews on top of a standard summarization algorithm. Since writing large volumes of reference summaries needed for advanced neural network models is impractical, our solution relies on weak supervision. Finally, we propose an evaluation scheme that is based on multiple crowdsourced reference summaries and aims to capture the massive review collection. We show that an initial implementation of our schema significantly improves over several baselines in ROUGE scores, and exhibits strong coherence in a manual linguistic quality assessment.