 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Behind the Mask: Estimating Uncertainty in Image-to-Image Problems
Nov 28, 2022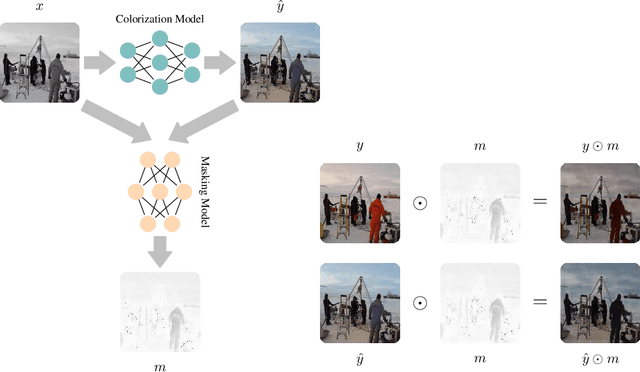
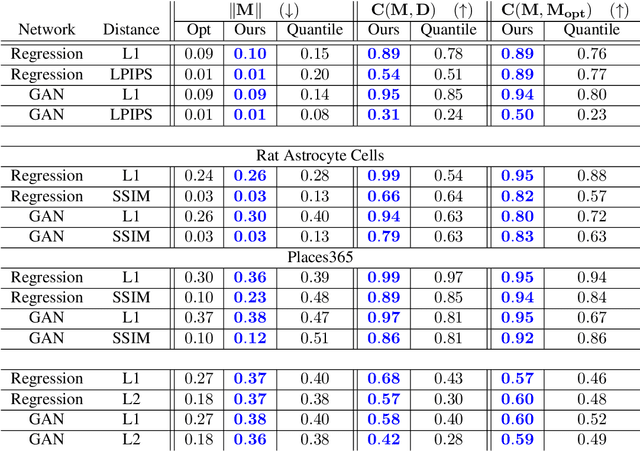

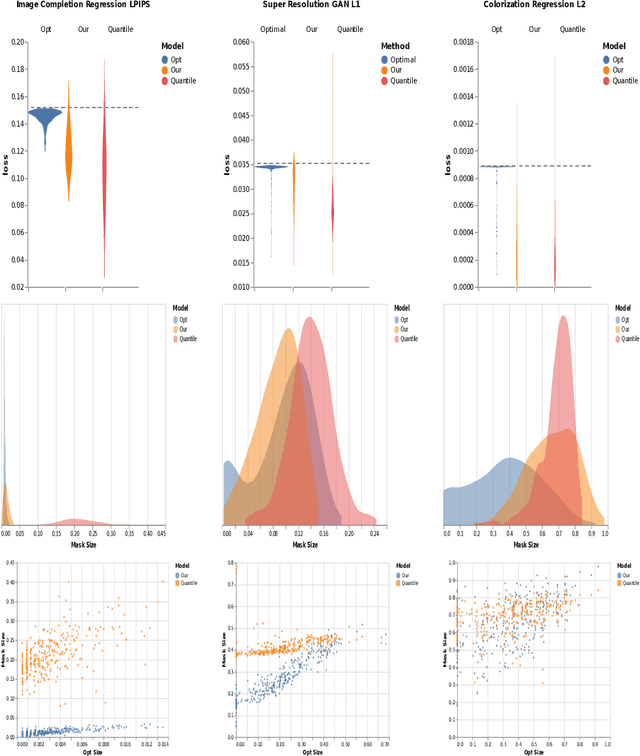
Estimating uncertainty in image-to-image networks is an important task, particularly as such networks are being increasingly deployed in the biological and medical imaging realms. In this paper, we introduce a new approach to this problem based on masking. Given an existing image-to-image network, our approach computes a mask such that the distance between the masked reconstructed image and the masked true image is guaranteed to be less than a specified threshold, with high probability. The mask thus identifies the more certain regions of the reconstructed image. Our approach is agnostic to the underlying image-to-image network, and only requires triples of the input (degraded), reconstructed and true images for training. Furthermore, our method is agnostic to the distance metric used. As a result, one can use $L_p$-style distances or perceptual distances like LPIPS, which contrasts with interval-based approaches to uncertainty. Our theoretical guarantees derive from a conformal calibration procedure. We evaluate our mask-based approach to uncertainty on image colorization, image completion, and super-resolution tasks, demonstrating high quality performance on each.
Identifying Helpful Sentences in Product Reviews
May 05, 2021



In recent years online shopping has gained momentum and became an important venue for customers wishing to save time and simplify their shopping process. A key advantage of shopping online is the ability to read what other customers are saying about products of interest. In this work, we aim to maintain this advantage in situations where extreme brevity is needed, for example, when shopping by voice. We suggest a novel task of extracting a single representative helpful sentence from a set of reviews for a given product. The selected sentence should meet two conditions: first, it should be helpful for a purchase decision and second, the opinion it expresses should be supported by multiple reviewers. This task is closely related to the task of Multi Document Summarization in the product reviews domain but differs in its objective and its level of conciseness. We collect a dataset in English of sentence helpfulness scores via crowd-sourcing and demonstrate its reliability despite the inherent subjectivity involved. Next, we describe a complete model that extracts representative helpful sentences with positive and negative sentiment towards the product and demonstrate that it outperforms several baselines.