 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Multi-Text Sentence Fusion Resources via Pyramid Annotations
Oct 09, 2021
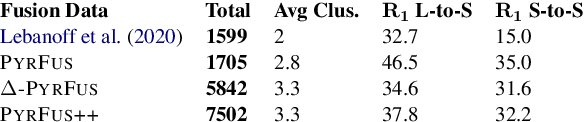


NLP models that compare or consolidate information across multiple documents often struggle when challenged with recognizing substantial information redundancies across the texts. For example, in multi-document summarization it is crucial to identify salient information across texts and then generate a non-redundant summary, while facing repeated and usually differently-phrased salient content. To facilitate researching such challenges, the sentence-level task of \textit{sentence fusion} was proposed, yet previous datasets for this task were very limited in their size and scope. In this paper, we revisit and substantially extend previous dataset creation efforts. With careful modifications, relabeling and employing complementing data sources, we were able to triple the size of a notable earlier dataset. Moreover, we show that our extended version uses more representative texts for multi-document tasks and provides a larger and more diverse training set, which substantially improves model training.
QA-Align: Representing Cross-Text Content Overlap by Aligning Question-Answer Propositions
Sep 26, 2021
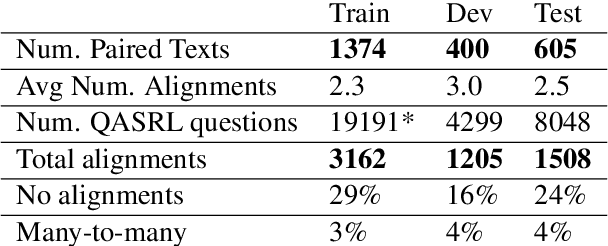
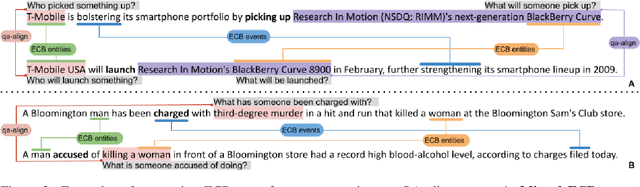
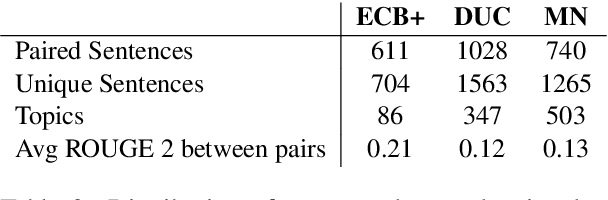
Multi-text applications, such as multi-document summarization, are typically required to model redundancies across related texts. Current methods confronting consolidation struggle to fuse overlapping information. In order to explicitly represent content overlap, we propose to align predicate-argument relations across texts, providing a potential scaffold for information consolidation. We go beyond clustering coreferring mentions, and instead model overlap with respect to redundancy at a propositional level, rather than merely detecting shared referents. Our setting exploits QA-SRL, utilizing question-answer pairs to capture predicate-argument relations, facilitating laymen annotation of cross-text alignments. We employ crowd-workers for constructing a dataset of QA-based alignments, and present a baseline QA alignment model trained over our dataset. Analyses show that our new task is semantically challenging, capturing content overlap beyond lexical similarity and complements cross-document coreference with proposition-level links, offering potential use for downstream tasks.