 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiFacetSum: Coreference-based Interactive Faceted Summarization for Multi-Document Exploration
Sep 23, 2021

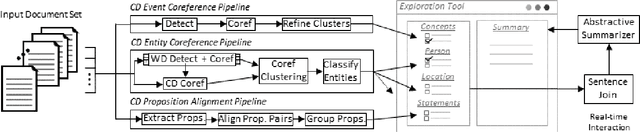
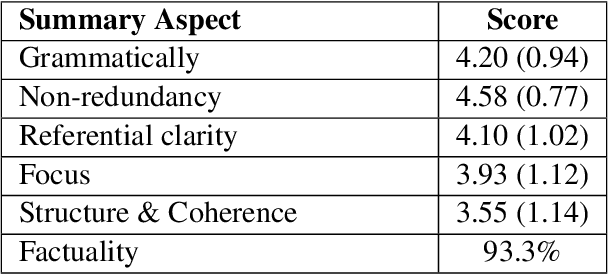
We introduce iFacetSum, a web application for exploring topical document sets. iFacetSum integrates interactive summarization together with faceted search, by providing a novel faceted navigation scheme that yields abstractive summaries for the user's selections. This approach offers both a comprehensive overview as well as concise details regarding subtopics of choice. Fine-grained facets are automatically produced based on cross-document coreference pipelines, rendering generic concepts, entities and statements surfacing in the source texts. We analyze the effectiveness of our application through small-scale user studies, which suggest the usefulness of our approach.
Evaluating Interactive Summarization: an Expansion-Based Framework
Sep 17, 2020


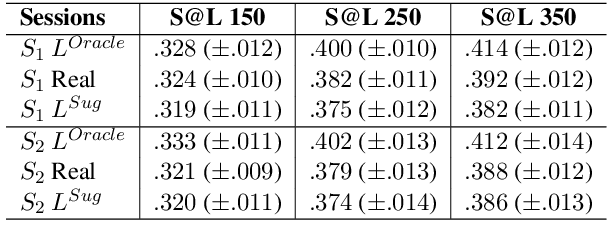
Allowing users to interact with multi-document summarizers is a promising direction towards improving and customizing summary results. Different ideas for interactive summarization have been proposed in previous work but these solutions are highly divergent and incomparable. In this paper, we develop an end-to-end evaluation framework for expansion-based interactive summarization, which considers the accumulating information along an interactive session. Our framework includes a procedure of collecting real user sessions and evaluation measures relying on standards, but adapted to reflect interaction. All of our solutions are intended to be released publicly as a benchmark, allowing comparison of future developments in interactive summarization. We demonstrate the use of our framework by evaluating and comparing baseline implementations that we developed for this purpose, which will serve as part of our benchmark. Our extensive experimentation and analysis of these systems motivate our design choices and support the viability of our framework.
Crowdsourcing Lightweight Pyramids for Manual Summary Evaluation
Apr 11, 2019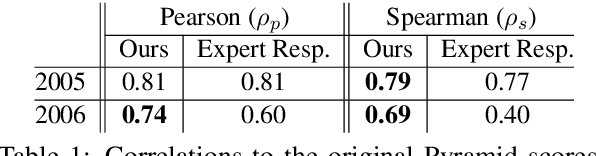
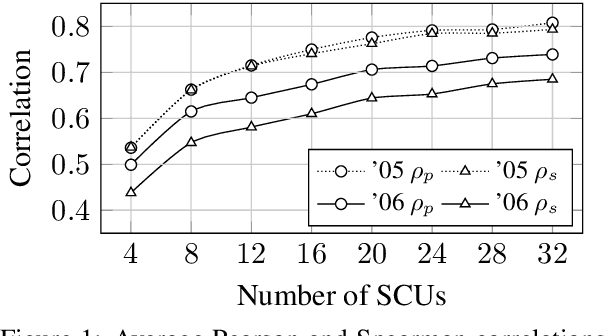
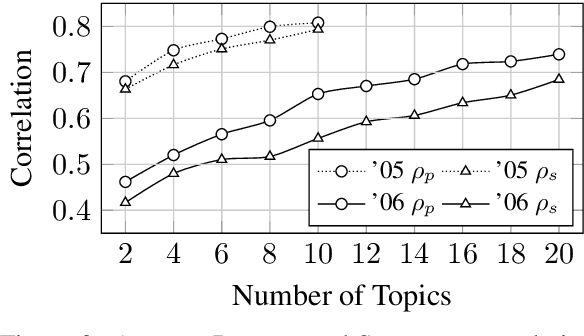
Conducting a manual evaluation is considered an essential part of summary evaluation methodology. Traditionally, the Pyramid protocol, which exhaustively compares system summaries to references, has been perceived as very reliable, providing objective scores. Yet, due to the high cost of the Pyramid method and the required expertise, researchers resorted to cheaper and less thorough manual evaluation methods, such as Responsiveness and pairwise comparison, attainable via crowdsourcing. We revisit the Pyramid approach, proposing a lightweight sampling-based version that is crowdsourcable. We analyze the performance of our method in comparison to original expert-based Pyramid evaluations, showing higher correlation relative to the common Responsiveness method. We release our crowdsourced Summary-Content-Units, along with all crowdsourcing scripts, for future evaluations.