 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus or Conflict? Fine-Grained Evaluation of Conflicting Answers in Question-Answering
Aug 17, 2025Large Language Models (LLMs) have demonstrated strong performance in question answering (QA) tasks. However, Multi-Answer Question Answering (MAQA), where a question may have several valid answers, remains challenging. Traditional QA settings often assume consistency across evidences, but MAQA can involve conflicting answers. Constructing datasets that reflect such conflicts is costly and labor-intensive, while existing benchmarks often rely on synthetic data, restrict the task to yes/no questions, or apply unverified automated annotation. To advance research in this area, we extend the conflict-aware MAQA setting to require models not only to identify all valid answers, but also to detect specific conflicting answer pairs, if any. To support this task, we introduce a novel cost-effective methodology for leveraging fact-checking datasets to construct NATCONFQA, a new benchmark for realistic, conflict-aware MAQA, enriched with detailed conflict labels, for all answer pairs. We evaluate eight high-end LLMs on NATCONFQA, revealing their fragility in handling various types of conflicts and the flawed strategies they employ to resolve them.
A Unifying Scheme for Extractive Content Selection Tasks
Jul 22, 2025A broad range of NLP tasks involve selecting relevant text spans from given source texts. Despite this shared objective, such \textit{content selection} tasks have traditionally been studied in isolation, each with its own modeling approaches, datasets, and evaluation metrics. In this work, we propose \textit{instruction-guided content selection (IGCS)} as a beneficial unified framework for such settings, where the task definition and any instance-specific request are encapsulated as instructions to a language model. To promote this framework, we introduce \igcsbench{}, the first unified benchmark covering diverse content selection tasks. Further, we create a large generic synthetic dataset that can be leveraged for diverse content selection tasks, and show that transfer learning with these datasets often boosts performance, whether dedicated training for the targeted task is available or not. Finally, we address generic inference time issues that arise in LLM-based modeling of content selection, assess a generic evaluation metric, and overall propose the utility of our resources and methods for future content selection models. Models and datasets available at https://github.com/shmuelamar/igcs.
OpenAsp: A Benchmark for Multi-document Open Aspect-based Summarization
Dec 07, 2023
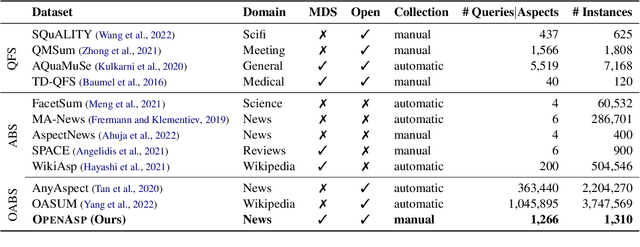
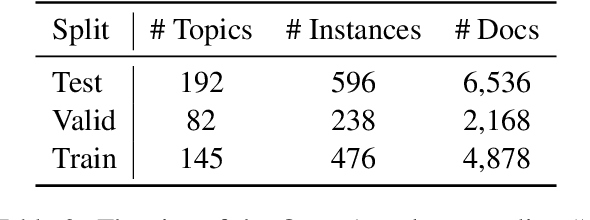
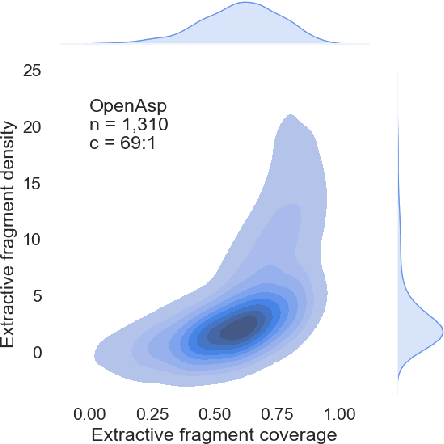
The performance of automatic summarization models has improved dramatically in recent years. Yet, there is still a gap in meeting specific information needs of users in real-world scenarios, particularly when a targeted summary is sought, such as in the useful aspect-based summarization setting targeted in this paper. Previous datasets and studies for this setting have predominantly concentrated on a limited set of pre-defined aspects, focused solely on single document inputs, or relied on synthetic data. To advance research on more realistic scenarios, we introduce OpenAsp, a benchmark for multi-document \textit{open} aspect-based summarization. This benchmark is created using a novel and cost-effective annotation protocol, by which an open aspect dataset is derived from existing generic multi-document summarization datasets. We analyze the properties of OpenAsp showcasing its high-quality content. Further, we show that the realistic open-aspect setting realized in OpenAsp poses a challenge for current state-of-the-art summarization models, as well as for large language models.
SummHelper: Collaborative Human-Computer Summarization
Aug 16, 2023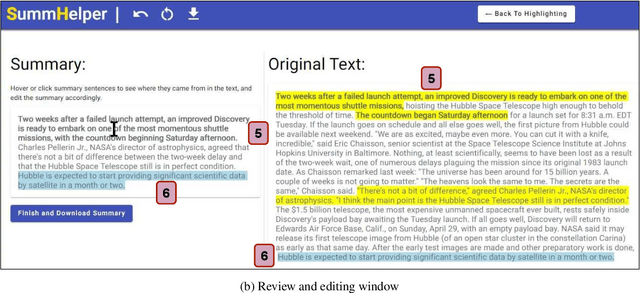
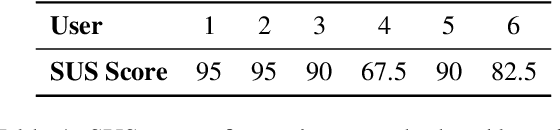
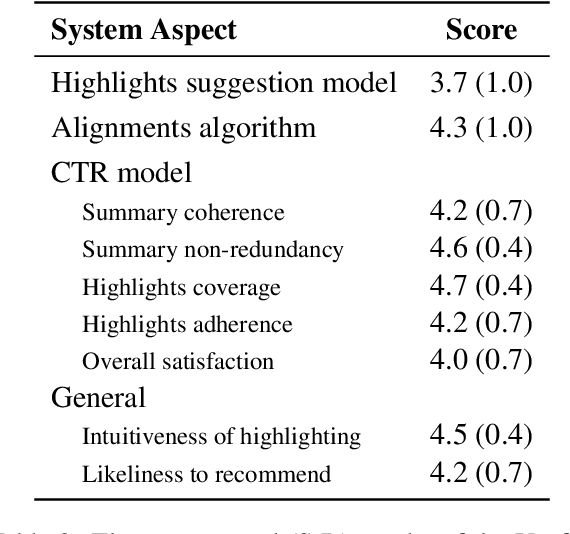

Current approaches for text summarization are predominantly automatic, with rather limited space for human intervention and control over the process. In this paper, we introduce SummHelper, a 2-phase summarization assistant designed to foster human-machine collaboration. The initial phase involves content selection, where the system recommends potential content, allowing users to accept, modify, or introduce additional selections. The subsequent phase, content consolidation, involves SummHelper generating a coherent summary from these selections, which users can then refine using visual mappings between the summary and the source text. Small-scale user studies reveal the effectiveness of our application, with participants being especially appreciative of the balance between automated guidance and opportunities for personal input.