 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreSumm: Predicting Summarization Performance Without Summarizing
Apr 07, 2025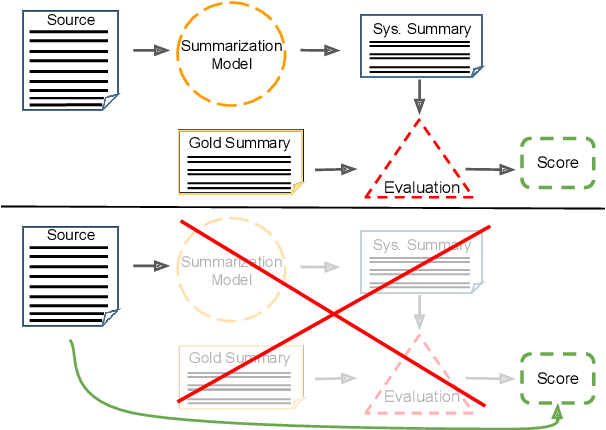
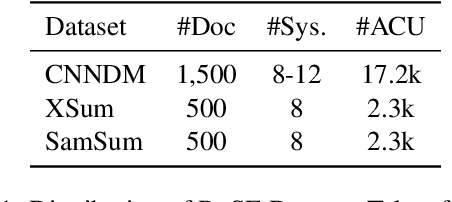
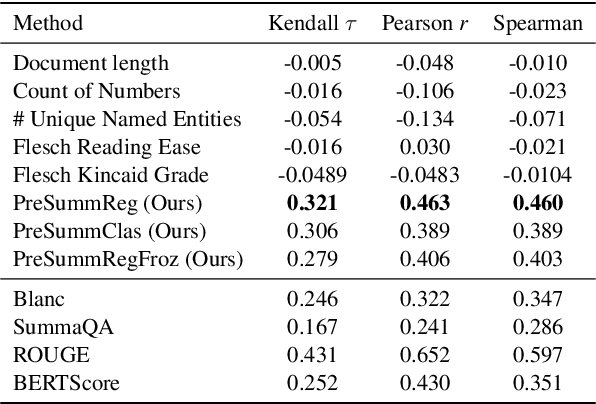
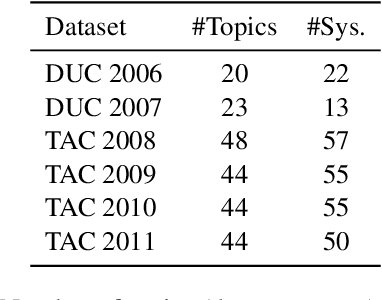
Despite recent advancements in automatic summarization, state-of-the-art models do not summarize all documents equally well, raising the question: why? While prior research has extensively analyzed summarization models, little attention has been given to the role of document characteristics in influencing summarization performance. In this work, we explore two key research questions. First, do documents exhibit consistent summarization quality across multiple systems? If so, can we predict a document's summarization performance without generating a summary? We answer both questions affirmatively and introduce PreSumm, a novel task in which a system predicts summarization performance based solely on the source document. Our analysis sheds light on common properties of documents with low PreSumm scores, revealing that they often suffer from coherence issues, complex content, or a lack of a clear main theme. In addition, we demonstrate PreSumm's practical utility in two key applications: improving hybrid summarization workflows by identifying documents that require manual summarization and enhancing dataset quality by filtering outliers and noisy documents. Overall, our findings highlight the critical role of document properties in summarization performance and offer insights into the limitations of current systems that could serve as the basis for future improvements.