 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Efficient 8-bit Low Precision Inference of Convolutional Neural Networks with IntelCaffe
May 04, 2018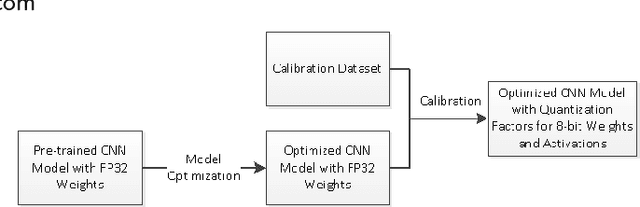
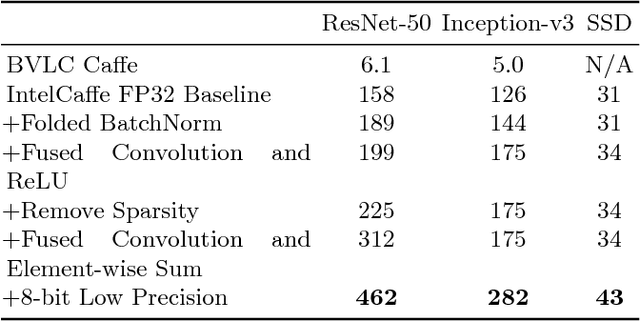

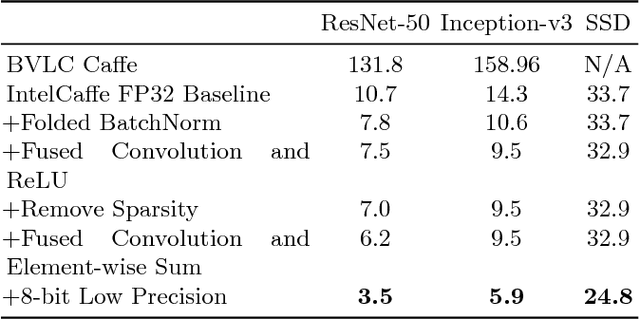
High throughput and low latency inference of deep neural networks are critical for the deployment of deep learning applications. This paper presents the efficient inference techniques of IntelCaffe, the first Intel optimized deep learning framework that supports efficient 8-bit low precision inference and model optimization techniques of convolutional neural networks on Intel Xeon Scalable Processors. The 8-bit optimized model is automatically generated with a calibration process from FP32 model without the need of fine-tuning or retraining. We show that the inference throughput and latency with ResNet-50, Inception-v3 and SSD are improved by 1.38X-2.9X and 1.35X-3X respectively with neglectable accuracy loss from IntelCaffe FP32 baseline and by 56X-75X and 26X-37X from BVLC Caffe. All these techniques have been open-sourced on IntelCaffe GitHub1, and the artifact is provided to reproduce the result on Amazon AWS Cloud.
Mixed Precision Training of Convolutional Neural Networks using Integer Operations
Feb 23, 2018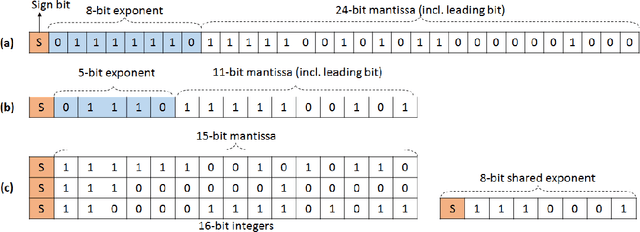
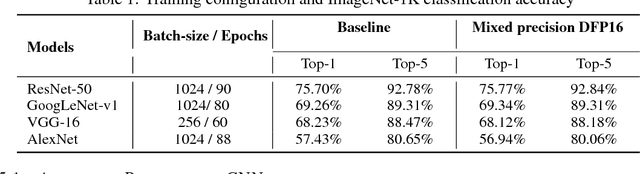


The state-of-the-art (SOTA) for mixed precision training is dominated by variants of low precision floating point operations, and in particular, FP16 accumulating into FP32 Micikevicius et al. (2017). On the other hand, while a lot of research has also happened in the domain of low and mixed-precision Integer training, these works either present results for non-SOTA networks (for instance only AlexNet for ImageNet-1K), or relatively small datasets (like CIFAR-10). In this work, we train state-of-the-art visual understanding neural networks on the ImageNet-1K dataset, with Integer operations on General Purpose (GP) hardware. In particular, we focus on Integer Fused-Multiply-and-Accumulate (FMA) operations which take two pairs of INT16 operands and accumulate results into an INT32 output.We propose a shared exponent representation of tensors and develop a Dynamic Fixed Point (DFP) scheme suitable for common neural network operations. The nuances of developing an efficient integer convolution kernel is examined, including methods to handle overflow of the INT32 accumulator. We implement CNN training for ResNet-50, GoogLeNet-v1, VGG-16 and AlexNet; and these networks achieve or exceed SOTA accuracy within the same number of iterations as their FP32 counterparts without any change in hyper-parameters and with a 1.8X improvement in end-to-end training throughput. To the best of our knowledge these results represent the first INT16 training results on GP hardware for ImageNet-1K dataset using SOTA CNNs and achieve highest reported accuracy using half-precision