 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoisson-Gamma Dynamical Systems with Non-Stationary Transition Dynamics
Feb 26, 2024



Bayesian methodologies for handling count-valued time series have gained prominence due to their ability to infer interpretable latent structures and to estimate uncertainties, and thus are especially suitable for dealing with noisy and incomplete count data. Among these Bayesian models, Poisson-Gamma Dynamical Systems (PGDSs) are proven to be effective in capturing the evolving dynamics underlying observed count sequences. However, the state-of-the-art PGDS still falls short in capturing the time-varying transition dynamics that are commonly observed in real-world count time series. To mitigate this limitation, a non-stationary PGDS is proposed to allow the underlying transition matrices to evolve over time, and the evolving transition matrices are modeled by sophisticatedly-designed Dirichlet Markov chains. Leveraging Dirichlet-Multinomial-Beta data augmentation techniques, a fully-conjugate and efficient Gibbs sampler is developed to perform posterior simulation. Experiments show that, in comparison with related models, the proposed non-stationary PGDS achieves improved predictive performance due to its capacity to learn non-stationary dependency structure captured by the time-evolving transition matrices.
AccEar: Accelerometer Acoustic Eavesdropping with Unconstrained Vocabulary
Dec 02, 2022



With the increasing popularity of voice-based applications, acoustic eavesdropping has become a serious threat to users' privacy. While on smartphones the access to microphones needs an explicit user permission, acoustic eavesdropping attacks can rely on motion sensors (such as accelerometer and gyroscope), which access is unrestricted. However, previous instances of such attacks can only recognize a limited set of pre-trained words or phrases. In this paper, we present AccEar, an accelerometerbased acoustic eavesdropping attack that can reconstruct any audio played on the smartphone's loudspeaker with unconstrained vocabulary. We show that an attacker can employ a conditional Generative Adversarial Network (cGAN) to reconstruct highfidelity audio from low-frequency accelerometer signals. The presented cGAN model learns to recreate high-frequency components of the user's voice from low-frequency accelerometer signals through spectrogram enhancement. We assess the feasibility and effectiveness of AccEar attack in a thorough set of experiments using audio from 16 public personalities. As shown by the results in both objective and subjective evaluations, AccEar successfully reconstructs user speeches from accelerometer signals in different scenarios including varying sampling rate, audio volume, device model, etc.
* 2022 IEEE Symposium on Security and Privacy (SP)
Highly Efficient 8-bit Low Precision Inference of Convolutional Neural Networks with IntelCaffe
May 04, 2018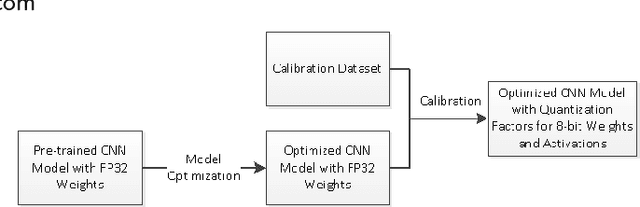
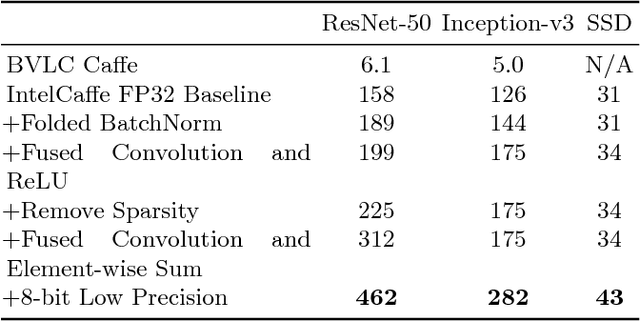

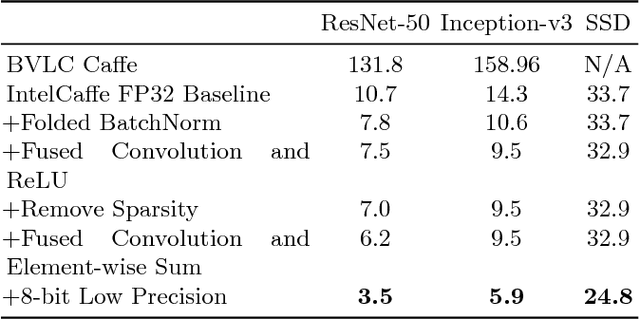
High throughput and low latency inference of deep neural networks are critical for the deployment of deep learning applications. This paper presents the efficient inference techniques of IntelCaffe, the first Intel optimized deep learning framework that supports efficient 8-bit low precision inference and model optimization techniques of convolutional neural networks on Intel Xeon Scalable Processors. The 8-bit optimized model is automatically generated with a calibration process from FP32 model without the need of fine-tuning or retraining. We show that the inference throughput and latency with ResNet-50, Inception-v3 and SSD are improved by 1.38X-2.9X and 1.35X-3X respectively with neglectable accuracy loss from IntelCaffe FP32 baseline and by 56X-75X and 26X-37X from BVLC Caffe. All these techniques have been open-sourced on IntelCaffe GitHub1, and the artifact is provided to reproduce the result on Amazon AWS Cloud.