 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Coarse to Fine: Managing Temporal Granularity in Spatio-Temporal Data for Fine-Grained Traffic Prediction
Jun 08, 2026Efficient acquisition, storage, and utilization of traffic data are critical challenges in spatio-temporal data management. Most traffic data systems collect and store observations at fixed, coarse-grained temporal intervals to reduce storage and computation costs. However, such coarse-grained data severely limits downstream applications that require predictions at a finer temporal granularity. Collecting and maintaining fine-grained traffic data across all locations and time periods would impose a substantial burden on database storage and preprocessing pipelines. To address this temporal granularity mismatch, we formulate a novel problem: predicting fine-grained future traffic using coarse-grained sampled data. We propose the Spatial-Temporal Refinement Predictor (STRP), a granularity-aware framework for spatio-temporal data systems. STRP integrates two components: Tree Convolution for efficient and interpretable spatial dependency modeling, and Inverse Dilated Convolution for progressive temporal extrapolation. STRP supports two practical prediction settings: window-based and duration-based, to handle different forms of granularity mismatch. Experiments on six benchmark datasets show that STRP significantly outperforms state-of-the-art baselines in both accuracy and efficiency. Our work offers a practical and interpretable approach to managing granularity mismatches in spatio-temporal traffic data systems.
On-Policy Supervised Fine-Tuning for Efficient Reasoning
Feb 13, 2026Large reasoning models (LRMs) are commonly trained with reinforcement learning (RL) to explore long chain-of-thought reasoning, achieving strong performance at high computational cost. Recent methods add multi-reward objectives to jointly optimize correctness and brevity, but these complex extensions often destabilize training and yield suboptimal trade-offs. We revisit this objective and challenge the necessity of such complexity. Through principled analysis, we identify fundamental misalignments in this paradigm: KL regularization loses its intended role when correctness and length are directly verifiable, and group-wise normalization becomes ambiguous under multiple reward signals. By removing these two items and simplifying the reward to a truncation-based length penalty, we show that the optimization problem reduces to supervised fine-tuning on self-generated data filtered for both correctness and conciseness. We term this simplified training strategy on-policy SFT. Despite its simplicity, on-policy SFT consistently defines the accuracy-efficiency Pareto frontier. It reduces CoT length by up to 80 while maintaining original accuracy, surpassing more complex RL-based methods across five benchmarks. Furthermore, it significantly enhances training efficiency, reducing GPU memory usage by 50% and accelerating convergence by 70%. Our code is available at https://github.com/EIT-NLP/On-Policy-SFT.
Beyond Quality: Unlocking Diversity in Ad Headline Generation with Large Language Models
Aug 26, 2025
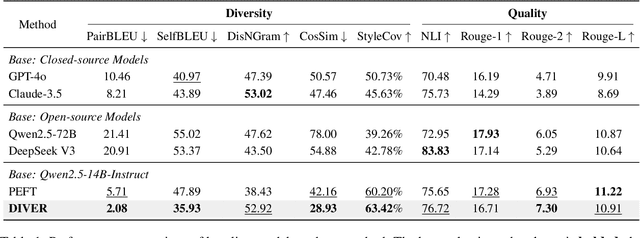
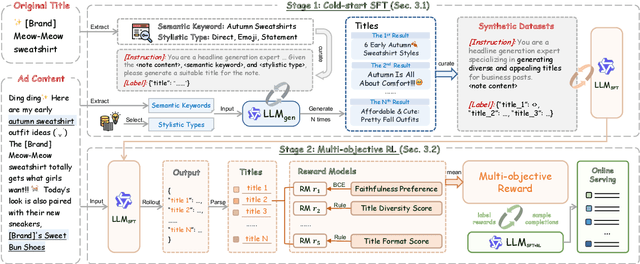
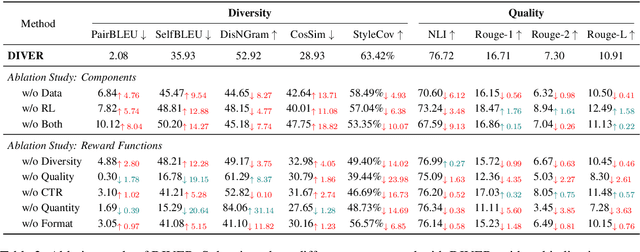
The generation of ad headlines plays a vital role in modern advertising, where both quality and diversity are essential to engage a broad range of audience segments. Current approaches primarily optimize language models for headline quality or click-through rates (CTR), often overlooking the need for diversity and resulting in homogeneous outputs. To address this limitation, we propose DIVER, a novel framework based on large language models (LLMs) that are jointly optimized for both diversity and quality. We first design a semantic- and stylistic-aware data generation pipeline that automatically produces high-quality training pairs with ad content and multiple diverse headlines. To achieve the goal of generating high-quality and diversified ad headlines within a single forward pass, we propose a multi-stage multi-objective optimization framework with supervised fine-tuning (SFT) and reinforcement learning (RL). Experiments on real-world industrial datasets demonstrate that DIVER effectively balances quality and diversity. Deployed on a large-scale content-sharing platform serving hundreds of millions of users, our framework improves advertiser value (ADVV) and CTR by 4.0% and 1.4%.
ACORN: Adaptive Contrastive Optimization for Safe and Robust Fine-Grained Robotic Manipulation
May 10, 2025Embodied AI research has traditionally emphasized performance metrics such as success rate and cumulative reward, overlooking critical robustness and safety considerations that emerge during real-world deployment. In actual environments, agents continuously encounter unpredicted situations and distribution shifts, causing seemingly reliable policies to experience catastrophic failures, particularly in manipulation tasks. To address this gap, we introduce four novel safety-centric metrics that quantify an agent's resilience to environmental perturbations. Building on these metrics, we present Adaptive Contrastive Optimization for Robust Manipulation (ACORN), a plug-and-play algorithm that enhances policy robustness without sacrificing performance. ACORN leverages contrastive learning to simultaneously align trajectories with expert demonstrations while diverging from potentially unsafe behaviors. Our approach efficiently generates informative negative samples through structured Gaussian noise injection, employing a double perturbation technique that maintains sample diversity while minimizing computational overhead. Comprehensive experiments across diverse manipulation environments validate ACORN's effectiveness, yielding improvements of up to 23% in safety metrics under disturbance compared to baseline methods. These findings underscore ACORN's significant potential for enabling reliable deployment of embodied agents in safety-critical real-world applications.
MGSR: 2D/3D Mutual-boosted Gaussian Splatting for High-fidelity Surface Reconstruction under Various Light Conditions
Mar 07, 2025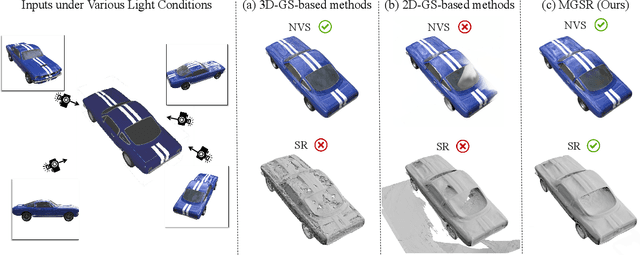
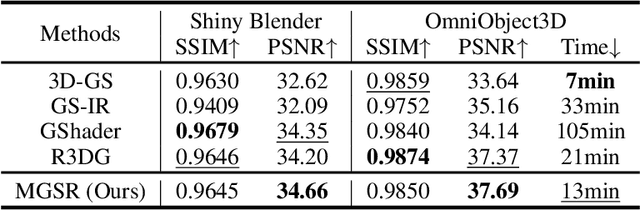
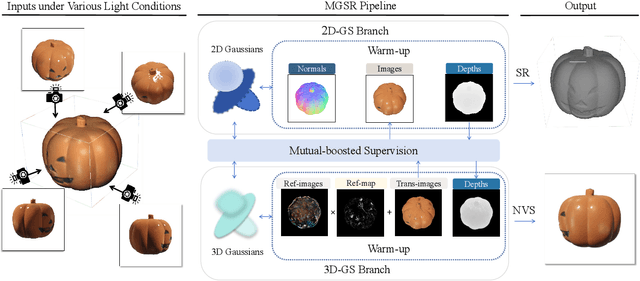

Novel view synthesis (NVS) and surface reconstruction (SR) are essential tasks in 3D Gaussian Splatting (3D-GS). Despite recent progress, these tasks are often addressed independently, with GS-based rendering methods struggling under diverse light conditions and failing to produce accurate surfaces, while GS-based reconstruction methods frequently compromise rendering quality. This raises a central question: must rendering and reconstruction always involve a trade-off? To address this, we propose MGSR, a 2D/3D Mutual-boosted Gaussian splatting for Surface Reconstruction that enhances both rendering quality and 3D reconstruction accuracy. MGSR introduces two branches--one based on 2D-GS and the other on 3D-GS. The 2D-GS branch excels in surface reconstruction, providing precise geometry information to the 3D-GS branch. Leveraging this geometry, the 3D-GS branch employs a geometry-guided illumination decomposition module that captures reflected and transmitted components, enabling realistic rendering under varied light conditions. Using the transmitted component as supervision, the 2D-GS branch also achieves high-fidelity surface reconstruction. Throughout the optimization process, the 2D-GS and 3D-GS branches undergo alternating optimization, providing mutual supervision. Prior to this, each branch completes an independent warm-up phase, with an early stopping strategy implemented to reduce computational costs. We evaluate MGSR on a diverse set of synthetic and real-world datasets, at both object and scene levels, demonstrating strong performance in rendering and surface reconstruction.
AdaptiveLog: An Adaptive Log Analysis Framework with the Collaboration of Large and Small Language Model
Jan 19, 2025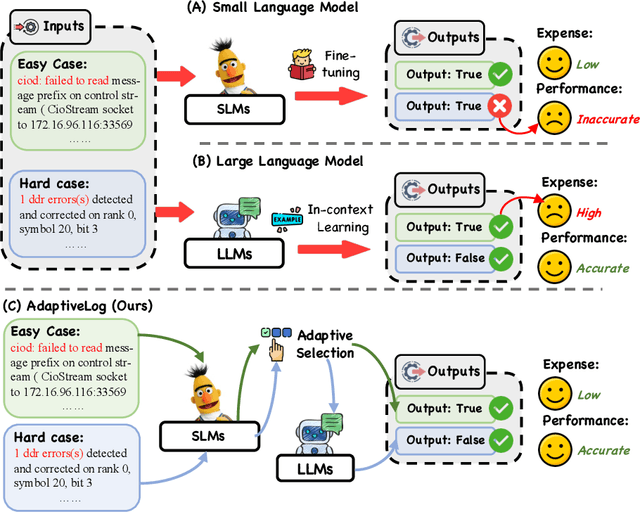

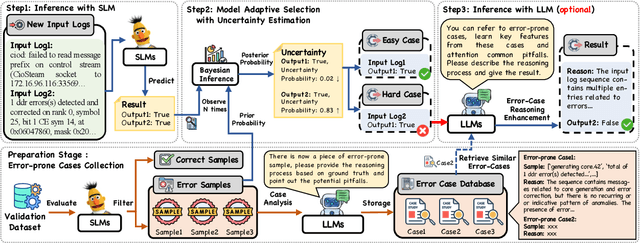

Automated log analysis is crucial to ensure high availability and reliability of complex systems. The advent of LLMs in NLP has ushered in a new era of language model-driven automated log analysis, garnering significant interest. Within this field, two primary paradigms based on language models for log analysis have become prominent. Small Language Models (SLMs) follow the pre-train and fine-tune paradigm, focusing on the specific log analysis task through fine-tuning on supervised datasets. On the other hand, LLMs following the in-context learning paradigm, analyze logs by providing a few examples in prompt contexts without updating parameters. Despite their respective strengths, we notice that SLMs are more cost-effective but less powerful, whereas LLMs with large parameters are highly powerful but expensive and inefficient. To trade-off between the performance and inference costs of both models in automated log analysis, this paper introduces an adaptive log analysis framework known as AdaptiveLog, which effectively reduces the costs associated with LLM while ensuring superior results. This framework collaborates an LLM and a small language model, strategically allocating the LLM to tackle complex logs while delegating simpler logs to the SLM. Specifically, to efficiently query the LLM, we propose an adaptive selection strategy based on the uncertainty estimation of the SLM, where the LLM is invoked only when the SLM is uncertain. In addition, to enhance the reasoning ability of the LLM in log analysis tasks, we propose a novel prompt strategy by retrieving similar error-prone cases as the reference, enabling the model to leverage past error experiences and learn solutions from these cases. Extensive experiments demonstrate that AdaptiveLog achieves state-of-the-art results across different tasks, elevating the overall accuracy of log analysis while maintaining cost efficiency.
IceDiff: High Resolution and High-Quality Sea Ice Forecasting with Generative Diffusion Prior
Oct 10, 2024Variation of Arctic sea ice has significant impacts on polar ecosystems, transporting routes, coastal communities, and global climate. Tracing the change of sea ice at a finer scale is paramount for both operational applications and scientific studies. Recent pan-Arctic sea ice forecasting methods that leverage advances in artificial intelligence has made promising progress over numerical models. However, forecasting sea ice at higher resolutions is still under-explored. To bridge the gap, we propose a two-staged deep learning framework, IceDiff, to forecast sea ice concentration at finer scales. IceDiff first leverages an independently trained vision transformer to generate coarse yet superior forecasting over previous methods at a regular 25km x 25km grid. This high-quality sea ice forecasting can be utilized as reliable guidance for the next stage. Subsequently, an unconditional diffusion model pre-trained on sea ice concentration maps is utilized for sampling down-scaled sea ice forecasting via a zero-shot guided sampling strategy and a patch-based method. For the first time, IceDiff demonstrates sea ice forecasting with the 6.25km x 6.25km resolution. IceDiff extends the boundary of existing sea ice forecasting models and more importantly, its capability to generate high-resolution sea ice concentration data is vital for pragmatic usages and research.
LUK: Empowering Log Understanding with Expert Knowledge from Large Language Models
Sep 03, 2024
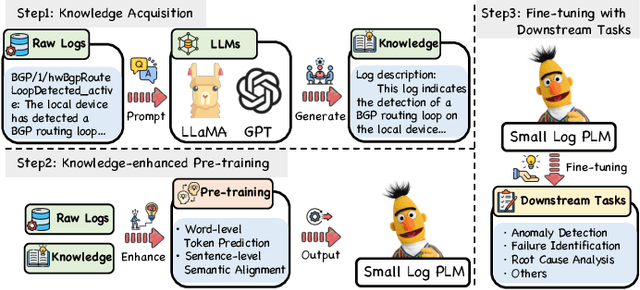
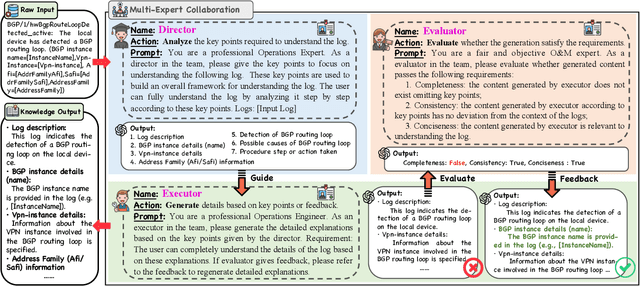
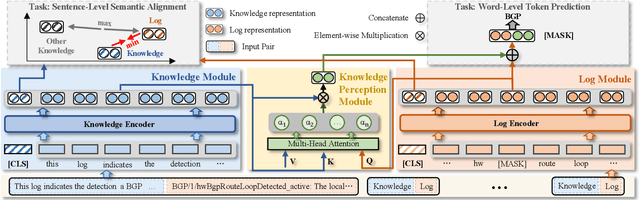
Logs play a critical role in providing essential information for system monitoring and troubleshooting. Recently, with the success of pre-trained language models (PLMs) and large language models (LLMs) in natural language processing (NLP), smaller PLMs (such as BERT) and LLMs (like ChatGPT) have become the current mainstream approaches for log analysis. While LLMs possess rich knowledge, their high computational costs and unstable performance make LLMs impractical for analyzing logs directly. In contrast, smaller PLMs can be fine-tuned for specific tasks even with limited computational resources, making them more practical. However, these smaller PLMs face challenges in understanding logs comprehensively due to their limited expert knowledge. To better utilize the knowledge embedded within LLMs for log understanding, this paper introduces a novel knowledge enhancement framework, called LUK, which acquires expert knowledge from LLMs to empower log understanding on a smaller PLM. Specifically, we design a multi-expert collaboration framework based on LLMs consisting of different roles to acquire expert knowledge. In addition, we propose two novel pre-training tasks to enhance the log pre-training with expert knowledge. LUK achieves state-of-the-art results on different log analysis tasks and extensive experiments demonstrate expert knowledge from LLMs can be utilized more effectively to understand logs.
Unifying Lane-Level Traffic Prediction from a Graph Structural Perspective: Benchmark and Baseline
Mar 22, 2024



Traffic prediction has long been a focal and pivotal area in research, witnessing both significant strides from city-level to road-level predictions in recent years. With the advancement of Vehicle-to-Everything (V2X) technologies, autonomous driving, and large-scale models in the traffic domain, lane-level traffic prediction has emerged as an indispensable direction. However, further progress in this field is hindered by the absence of comprehensive and unified evaluation standards, coupled with limited public availability of data and code. This paper extensively analyzes and categorizes existing research in lane-level traffic prediction, establishes a unified spatial topology structure and prediction tasks, and introduces a simple baseline model, GraphMLP, based on graph structure and MLP networks. We have replicated codes not publicly available in existing studies and, based on this, thoroughly and fairly assessed various models in terms of effectiveness, efficiency, and applicability, providing insights for practical applications. Additionally, we have released three new datasets and corresponding codes to accelerate progress in this field, all of which can be found on https://github.com/ShuhaoLii/TITS24LaneLevel-Traffic-Benchmark.
Dynamically configured physics-informed neural network in topology optimization applications
Dec 12, 2023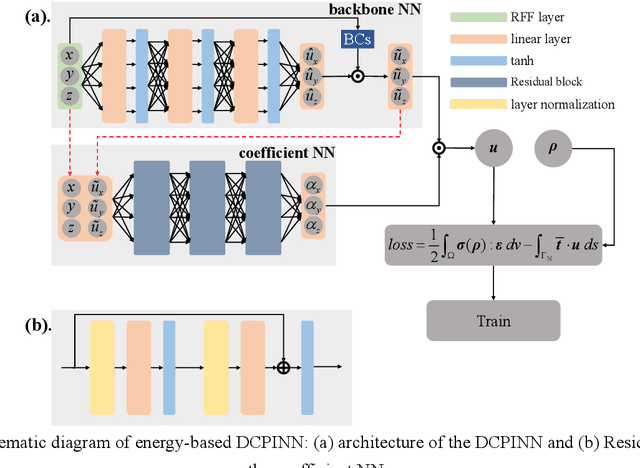
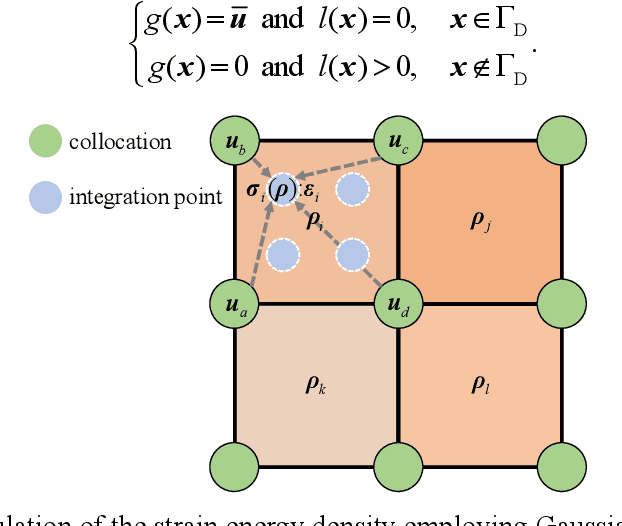
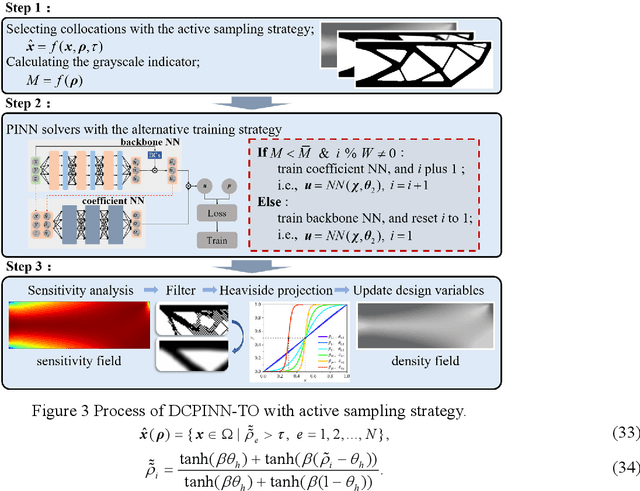
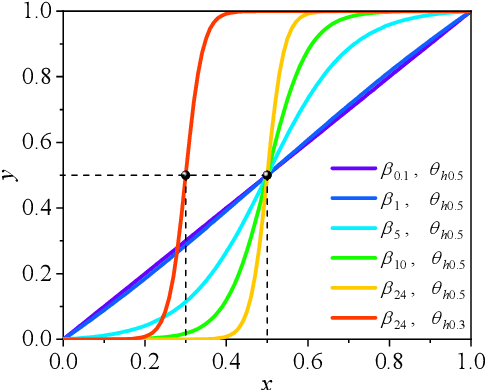
Integration of machine learning (ML) into the topology optimization (TO) framework is attracting increasing attention, but data acquisition in data-driven models is prohibitive. Compared with popular ML methods, the physics-informed neural network (PINN) can avoid generating enormous amounts of data when solving forward problems and additionally provide better inference. To this end, a dynamically configured PINN-based topology optimization (DCPINN-TO) method is proposed. The DCPINN is composed of two subnetworks, namely the backbone neural network (NN) and the coefficient NN, where the coefficient NN has fewer trainable parameters. The designed architecture aims to dynamically configure trainable parameters; that is, an inexpensive NN is used to replace an expensive one at certain optimization cycles. Furthermore, an active sampling strategy is proposed to selectively sample collocations depending on the pseudo-densities at each optimization cycle. In this manner, the number of collocations will decrease with the optimization process but will hardly affect it. The Gaussian integral is used to calculate the strain energy of elements, which yields a byproduct of decoupling the mapping of the material at the collocations. Several examples with different resolutions validate the feasibility of the DCPINN-TO method, and multiload and multiconstraint problems are employed to illustrate its generalization. In addition, compared to finite element analysis-based TO (FEA-TO), the accuracy of the displacement prediction and optimization results indicate that the DCPINN-TO method is effective and efficient.