 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Transferable Adversarial Attacks with Centralized Perturbation
Dec 23, 2023
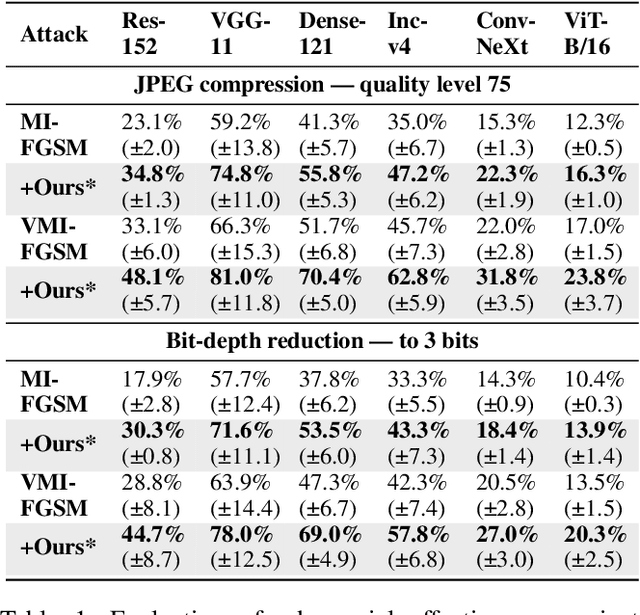
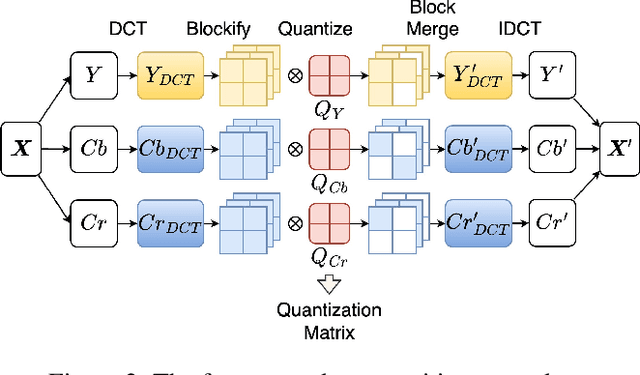
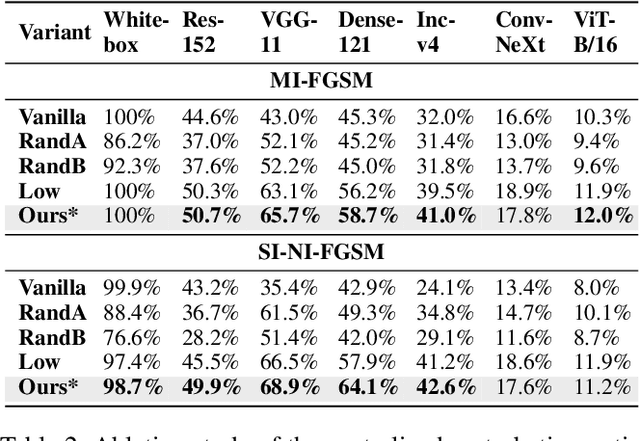
Adversarial transferability enables black-box attacks on unknown victim deep neural networks (DNNs), rendering attacks viable in real-world scenarios. Current transferable attacks create adversarial perturbation over the entire image, resulting in excessive noise that overfit the source model. Concentrating perturbation to dominant image regions that are model-agnostic is crucial to improving adversarial efficacy. However, limiting perturbation to local regions in the spatial domain proves inadequate in augmenting transferability. To this end, we propose a transferable adversarial attack with fine-grained perturbation optimization in the frequency domain, creating centralized perturbation. We devise a systematic pipeline to dynamically constrain perturbation optimization to dominant frequency coefficients. The constraint is optimized in parallel at each iteration, ensuring the directional alignment of perturbation optimization with model prediction. Our approach allows us to centralize perturbation towards sample-specific important frequency features, which are shared by DNNs, effectively mitigating source model overfitting. Experiments demonstrate that by dynamically centralizing perturbation on dominating frequency coefficients, crafted adversarial examples exhibit stronger transferability, and allowing them to bypass various defenses.
Unified High-binding Watermark for Unconditional Image Generation Models
Oct 14, 2023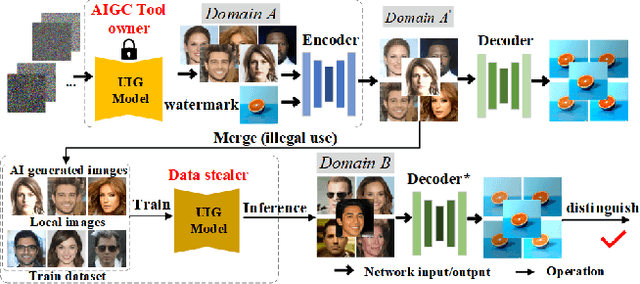
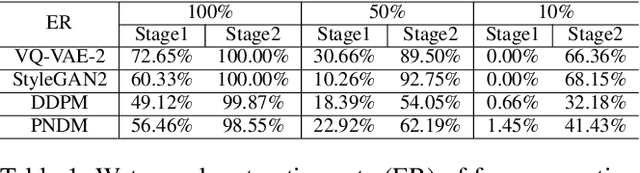
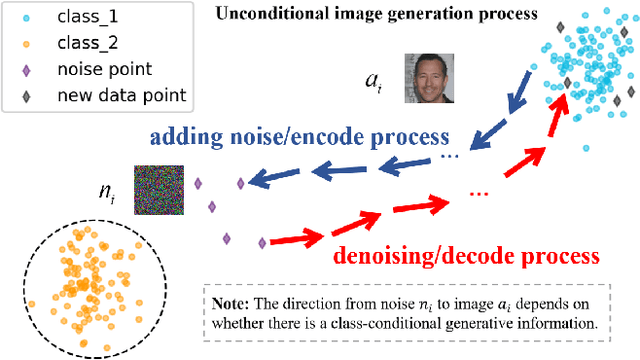
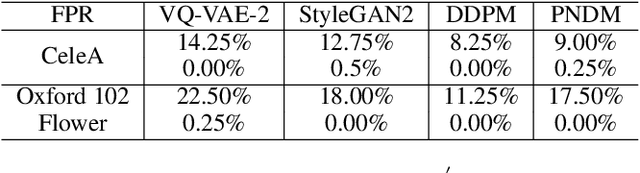
Deep learning techniques have implemented many unconditional image generation (UIG) models, such as GAN, Diffusion model, etc. The extremely realistic images (also known as AI-Generated Content, AIGC for short) produced by these models bring urgent needs for intellectual property protection such as data traceability and copyright certification. An attacker can steal the output images of the target model and use them as part of the training data to train a private surrogate UIG model. The implementation mechanisms of UIG models are diverse and complex, and there is no unified and effective protection and verification method at present. To address these issues, we propose a two-stage unified watermark verification mechanism with high-binding effects for such models. In the first stage, we use an encoder to invisibly write the watermark image into the output images of the original AIGC tool, and reversely extract the watermark image through the corresponding decoder. In the second stage, we design the decoder fine-tuning process, and the fine-tuned decoder can make correct judgments on whether the suspicious model steals the original AIGC tool data. Experiments demonstrate our method can complete the verification work with almost zero false positive rate under the condition of only using the model output images. Moreover, the proposed method can achieve data steal verification across different types of UIG models, which further increases the practicality of the method.
Concealed Electronic Countermeasures of Radar Signal with Adversarial Examples
Oct 12, 2023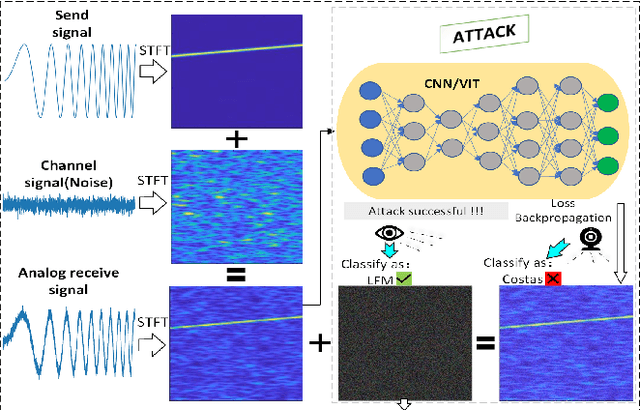
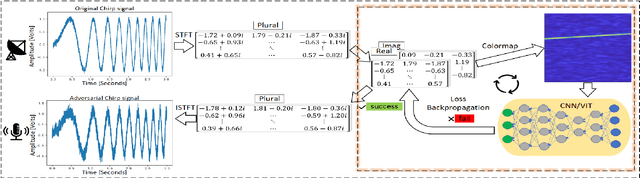


Electronic countermeasures involving radar signals are an important aspect of modern warfare. Traditional electronic countermeasures techniques typically add large-scale interference signals to ensure interference effects, which can lead to attacks being too obvious. In recent years, AI-based attack methods have emerged that can effectively solve this problem, but the attack scenarios are currently limited to time domain radar signal classification. In this paper, we focus on the time-frequency images classification scenario of radar signals. We first propose an attack pipeline under the time-frequency images scenario and DITIMI-FGSM attack algorithm with high transferability. Then, we propose STFT-based time domain signal attack(STDS) algorithm to solve the problem of non-invertibility in time-frequency analysis, thus obtaining the time-domain representation of the interference signal. A large number of experiments show that our attack pipeline is feasible and the proposed attack method has a high success rate.
Enhancing Clean Label Backdoor Attack with Two-phase Specific Triggers
Jun 10, 2022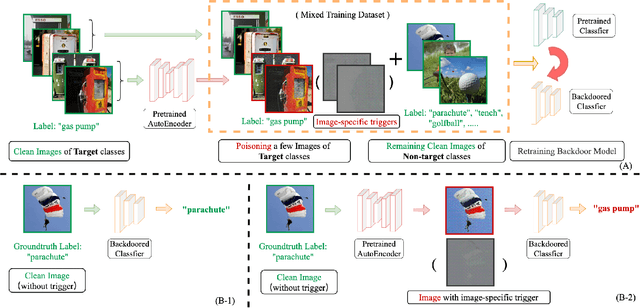
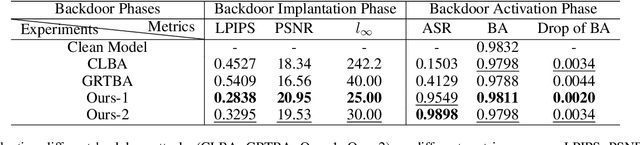

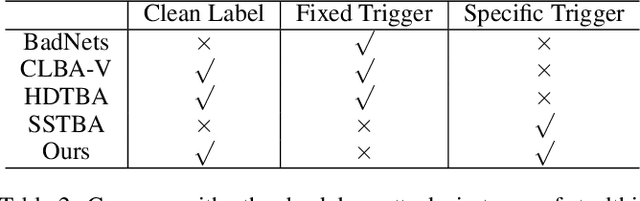
Backdoor attacks threaten Deep Neural Networks (DNNs). Towards stealthiness, researchers propose clean-label backdoor attacks, which require the adversaries not to alter the labels of the poisoned training datasets. Clean-label settings make the attack more stealthy due to the correct image-label pairs, but some problems still exist: first, traditional methods for poisoning training data are ineffective; second, traditional triggers are not stealthy which are still perceptible. To solve these problems, we propose a two-phase and image-specific triggers generation method to enhance clean-label backdoor attacks. Our methods are (1) powerful: our triggers can both promote the two phases (i.e., the backdoor implantation and activation phase) in backdoor attacks simultaneously; (2) stealthy: our triggers are generated from each image. They are image-specific instead of fixed triggers. Extensive experiments demonstrate that our approach can achieve a fantastic attack success rate~(98.98%) with low poisoning rate~(5%), high stealthiness under many evaluation metrics and is resistant to backdoor defense methods.
l-Leaks: Membership Inference Attacks with Logits
May 13, 2022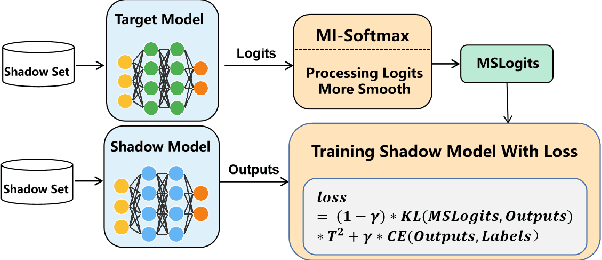

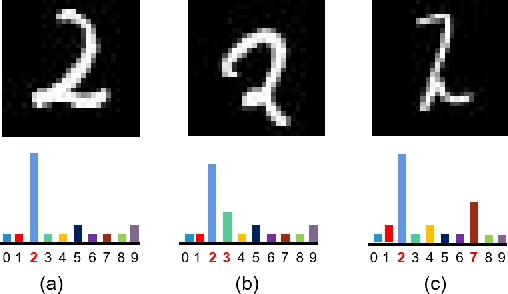

Machine Learning (ML) has made unprecedented progress in the past several decades. However, due to the memorability of the training data, ML is susceptible to various attacks, especially Membership Inference Attacks (MIAs), the objective of which is to infer the model's training data. So far, most of the membership inference attacks against ML classifiers leverage the shadow model with the same structure as the target model. However, empirical results show that these attacks can be easily mitigated if the shadow model is not clear about the network structure of the target model. In this paper, We present attacks based on black-box access to the target model. We name our attack \textbf{l-Leaks}. The l-Leaks follows the intuition that if an established shadow model is similar enough to the target model, then the adversary can leverage the shadow model's information to predict a target sample's membership.The logits of the trained target model contain valuable sample knowledge. We build the shadow model by learning the logits of the target model and making the shadow model more similar to the target model. Then shadow model will have sufficient confidence in the member samples of the target model. We also discuss the effect of the shadow model's different network structures to attack results. Experiments over different networks and datasets demonstrate that both of our attacks achieve strong performance.
Improving the Transferability of Adversarial Examples with Restructure Embedded Patches
Apr 27, 2022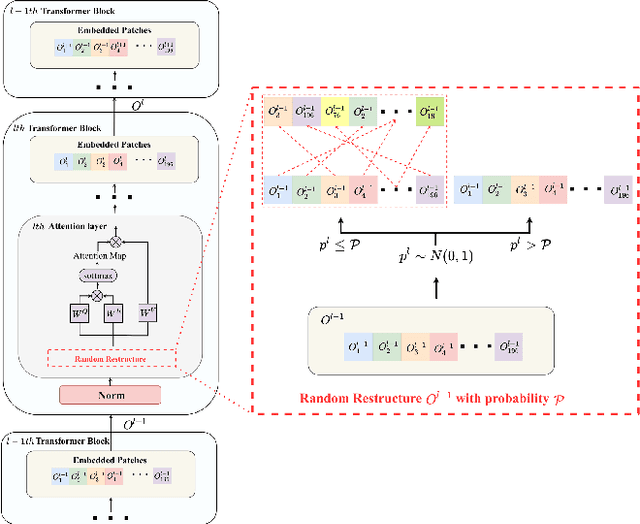
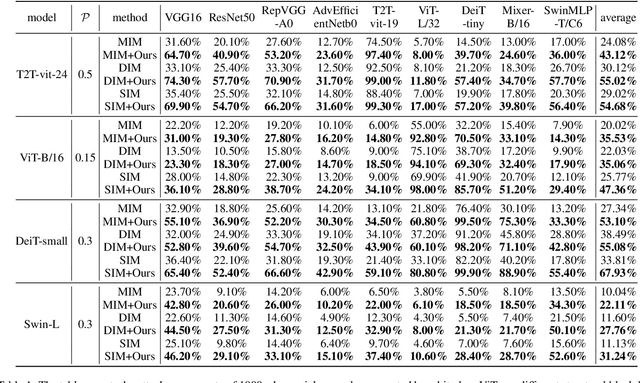

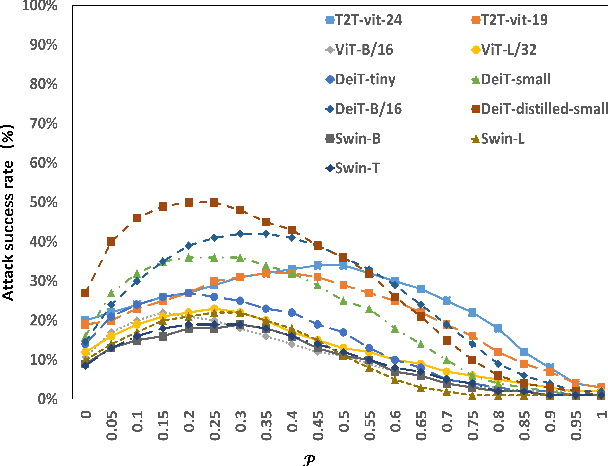
Vision transformers (ViTs) have demonstrated impressive performance in various computer vision tasks. However, the adversarial examples generated by ViTs are challenging to transfer to other networks with different structures. Recent attack methods do not consider the specificity of ViTs architecture and self-attention mechanism, which leads to poor transferability of the generated adversarial samples by ViTs. We attack the unique self-attention mechanism in ViTs by restructuring the embedded patches of the input. The restructured embedded patches enable the self-attention mechanism to obtain more diverse patches connections and help ViTs keep regions of interest on the object. Therefore, we propose an attack method against the unique self-attention mechanism in ViTs, called Self-Attention Patches Restructure (SAPR). Our method is simple to implement yet efficient and applicable to any self-attention based network and gradient transferability-based attack methods. We evaluate attack transferability on black-box models with different structures. The result show that our method generates adversarial examples on white-box ViTs with higher transferability and higher image quality. Our research advances the development of black-box transfer attacks on ViTs and demonstrates the feasibility of using white-box ViTs to attack other black-box models.
Boosting Adversarial Transferability of MLP-Mixer
Apr 26, 2022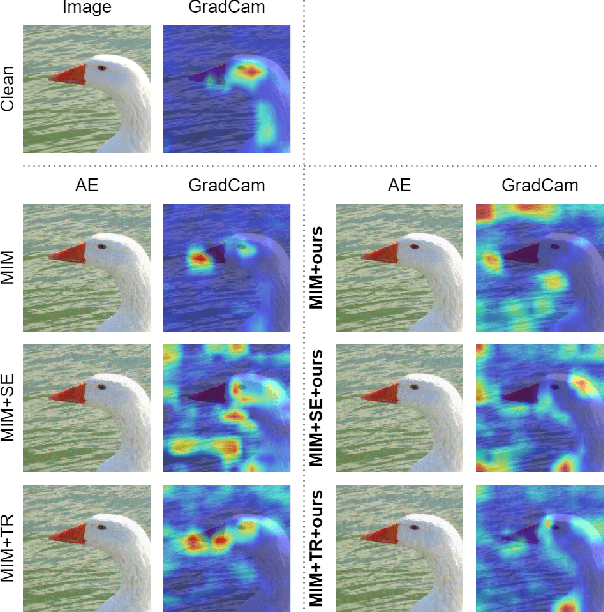

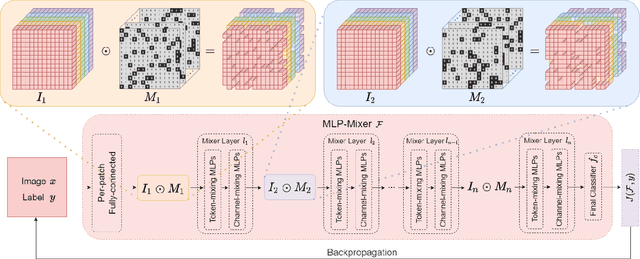
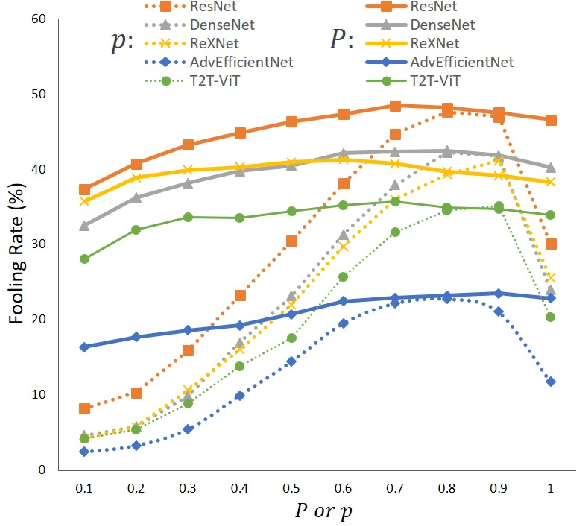
The security of models based on new architectures such as MLP-Mixer and ViTs needs to be studied urgently. However, most of the current researches are mainly aimed at the adversarial attack against ViTs, and there is still relatively little adversarial work on MLP-mixer. We propose an adversarial attack method against MLP-Mixer called Maxwell's demon Attack (MA). MA breaks the channel-mixing and token-mixing mechanism of MLP-Mixer by controlling the part input of MLP-Mixer's each Mixer layer, and disturbs MLP-Mixer to obtain the main information of images. Our method can mask the part input of the Mixer layer, avoid overfitting of the adversarial examples to the source model, and improve the transferability of cross-architecture. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed MA. Our method can be easily combined with existing methods and can improve the transferability by up to 38.0% on MLP-based ResMLP. Adversarial examples produced by our method on MLP-Mixer are able to exceed the transferability of adversarial examples produced using DenseNet against CNNs. To the best of our knowledge, we are the first work to study adversarial transferability of MLP-Mixer.
Demiguise Attack: Crafting Invisible Semantic Adversarial Perturbations with Perceptual Similarity
Jul 03, 2021



Deep neural networks (DNNs) have been found to be vulnerable to adversarial examples. Adversarial examples are malicious images with visually imperceptible perturbations. While these carefully crafted perturbations restricted with tight $\Lp$ norm bounds are small, they are still easily perceivable by humans. These perturbations also have limited success rates when attacking black-box models or models with defenses like noise reduction filters. To solve these problems, we propose Demiguise Attack, crafting ``unrestricted'' perturbations with Perceptual Similarity. Specifically, we can create powerful and photorealistic adversarial examples by manipulating semantic information based on Perceptual Similarity. Adversarial examples we generate are friendly to the human visual system (HVS), although the perturbations are of large magnitudes. We extend widely-used attacks with our approach, enhancing adversarial effectiveness impressively while contributing to imperceptibility. Extensive experiments show that the proposed method not only outperforms various state-of-the-art attacks in terms of fooling rate, transferability, and robustness against defenses but can also improve attacks effectively. In addition, we also notice that our implementation can simulate illumination and contrast changes that occur in real-world scenarios, which will contribute to exposing the blind spots of DNNs.