 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Transferability of Adversarial Examples with Restructure Embedded Patches
Paper and Code
Apr 27, 2022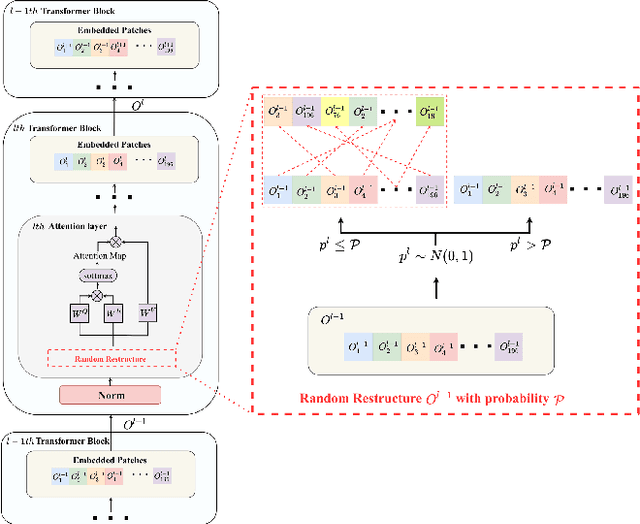
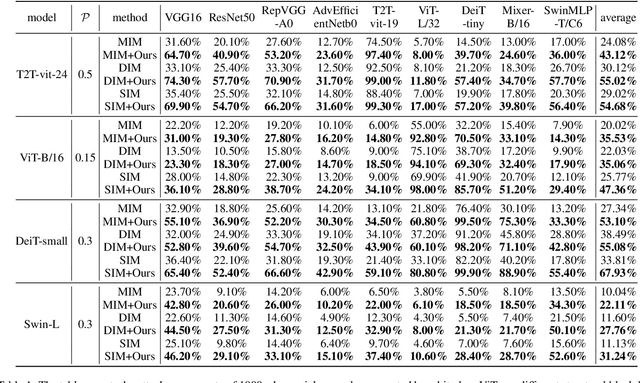

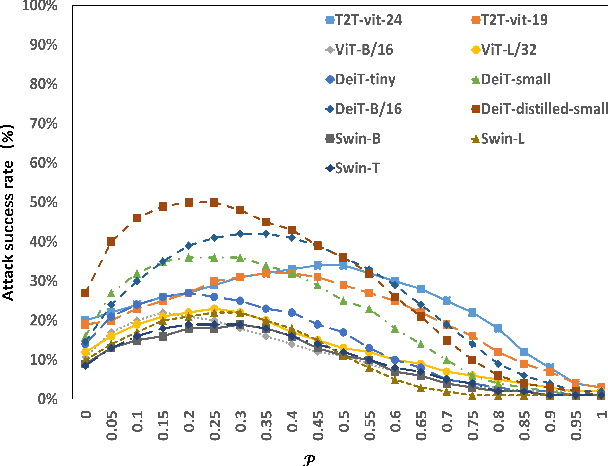
Vision transformers (ViTs) have demonstrated impressive performance in various computer vision tasks. However, the adversarial examples generated by ViTs are challenging to transfer to other networks with different structures. Recent attack methods do not consider the specificity of ViTs architecture and self-attention mechanism, which leads to poor transferability of the generated adversarial samples by ViTs. We attack the unique self-attention mechanism in ViTs by restructuring the embedded patches of the input. The restructured embedded patches enable the self-attention mechanism to obtain more diverse patches connections and help ViTs keep regions of interest on the object. Therefore, we propose an attack method against the unique self-attention mechanism in ViTs, called Self-Attention Patches Restructure (SAPR). Our method is simple to implement yet efficient and applicable to any self-attention based network and gradient transferability-based attack methods. We evaluate attack transferability on black-box models with different structures. The result show that our method generates adversarial examples on white-box ViTs with higher transferability and higher image quality. Our research advances the development of black-box transfer attacks on ViTs and demonstrates the feasibility of using white-box ViTs to attack other black-box models.