 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence Security Competition (AISC)
Dec 07, 2022



The security of artificial intelligence (AI) is an important research area towards safe, reliable, and trustworthy AI systems. To accelerate the research on AI security, the Artificial Intelligence Security Competition (AISC) was organized by the Zhongguancun Laboratory, China Industrial Control Systems Cyber Emergency Response Team, Institute for Artificial Intelligence, Tsinghua University, and RealAI as part of the Zhongguancun International Frontier Technology Innovation Competition (https://www.zgc-aisc.com/en). The competition consists of three tracks, including Deepfake Security Competition, Autonomous Driving Security Competition, and Face Recognition Security Competition. This report will introduce the competition rules of these three tracks and the solutions of top-ranking teams in each track.
Improving the Transferability of Adversarial Examples with Restructure Embedded Patches
Apr 27, 2022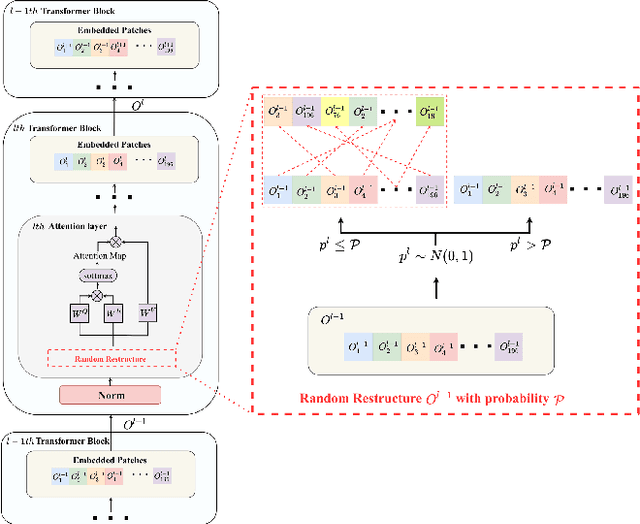
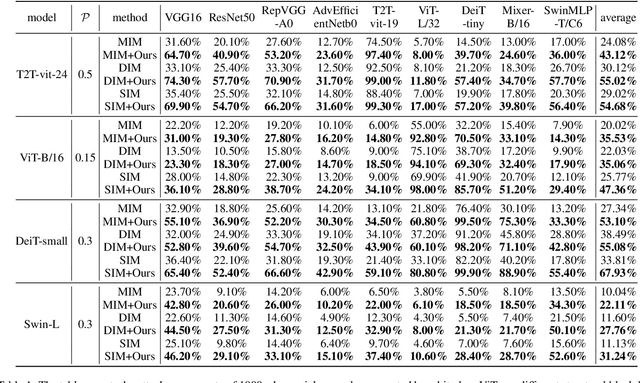

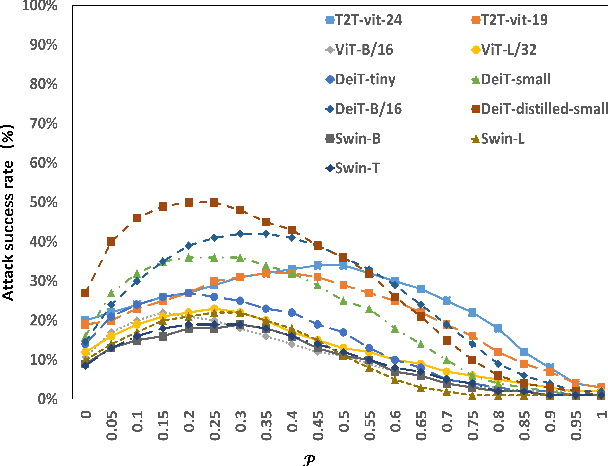
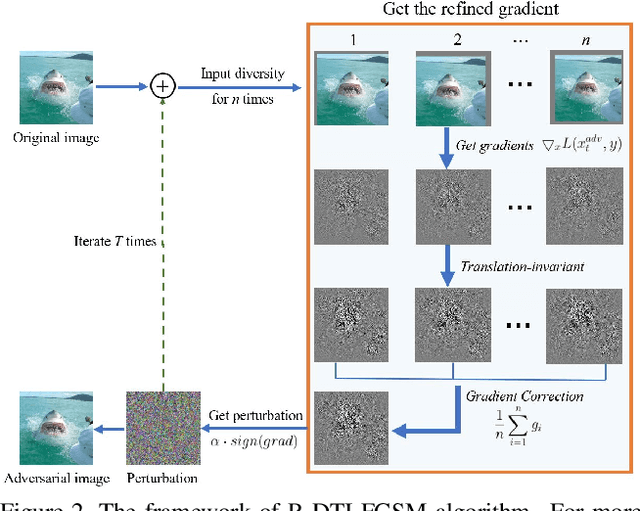
Vision transformers (ViTs) have demonstrated impressive performance in various computer vision tasks. However, the adversarial examples generated by ViTs are challenging to transfer to other networks with different structures. Recent attack methods do not consider the specificity of ViTs architecture and self-attention mechanism, which leads to poor transferability of the generated adversarial samples by ViTs. We attack the unique self-attention mechanism in ViTs by restructuring the embedded patches of the input. The restructured embedded patches enable the self-attention mechanism to obtain more diverse patches connections and help ViTs keep regions of interest on the object. Therefore, we propose an attack method against the unique self-attention mechanism in ViTs, called Self-Attention Patches Restructure (SAPR). Our method is simple to implement yet efficient and applicable to any self-attention based network and gradient transferability-based attack methods. We evaluate attack transferability on black-box models with different structures. The result show that our method generates adversarial examples on white-box ViTs with higher transferability and higher image quality. Our research advances the development of black-box transfer attacks on ViTs and demonstrates the feasibility of using white-box ViTs to attack other black-box models.
Boosting Adversarial Transferability of MLP-Mixer
Apr 26, 2022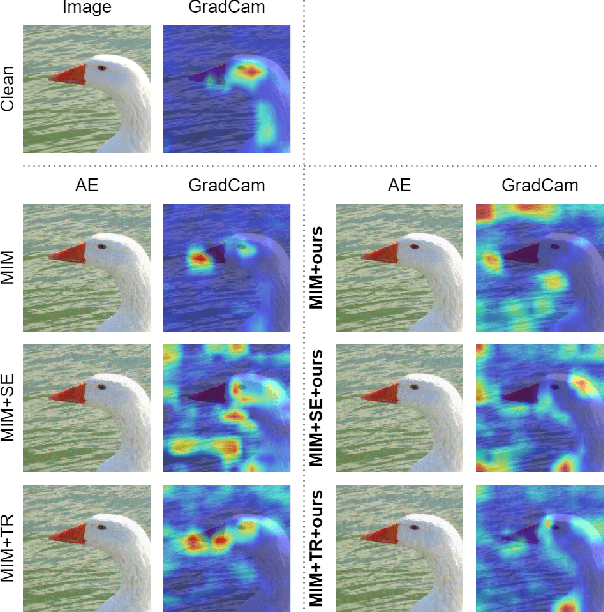

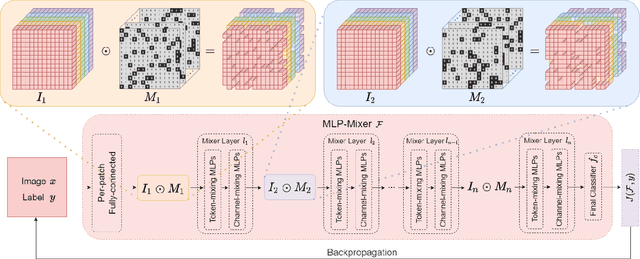
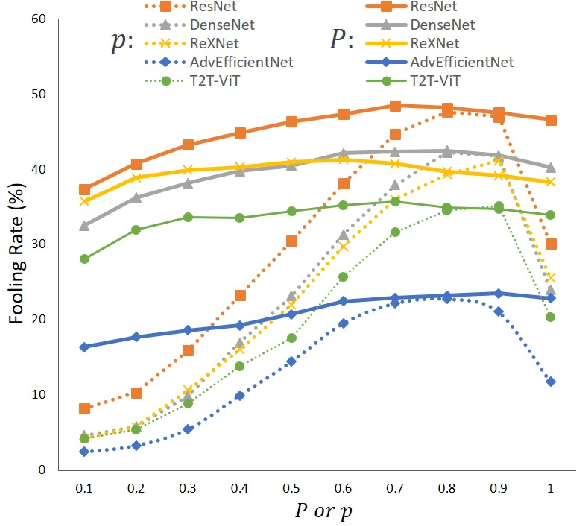
The security of models based on new architectures such as MLP-Mixer and ViTs needs to be studied urgently. However, most of the current researches are mainly aimed at the adversarial attack against ViTs, and there is still relatively little adversarial work on MLP-mixer. We propose an adversarial attack method against MLP-Mixer called Maxwell's demon Attack (MA). MA breaks the channel-mixing and token-mixing mechanism of MLP-Mixer by controlling the part input of MLP-Mixer's each Mixer layer, and disturbs MLP-Mixer to obtain the main information of images. Our method can mask the part input of the Mixer layer, avoid overfitting of the adversarial examples to the source model, and improve the transferability of cross-architecture. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed MA. Our method can be easily combined with existing methods and can improve the transferability by up to 38.0% on MLP-based ResMLP. Adversarial examples produced by our method on MLP-Mixer are able to exceed the transferability of adversarial examples produced using DenseNet against CNNs. To the best of our knowledge, we are the first work to study adversarial transferability of MLP-Mixer.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021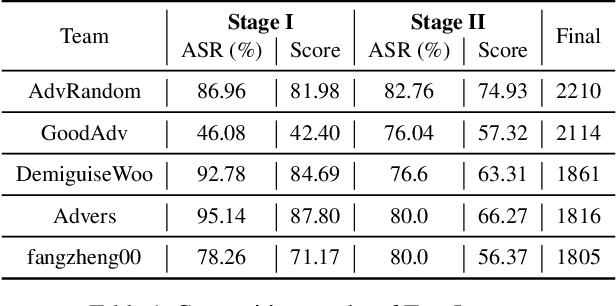
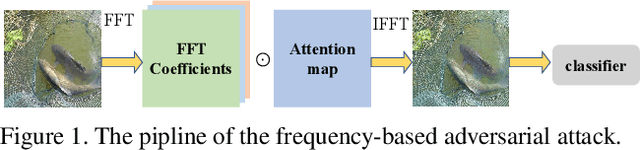
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.