 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Adversarial Transferability of MLP-Mixer
Paper and Code
Apr 26, 2022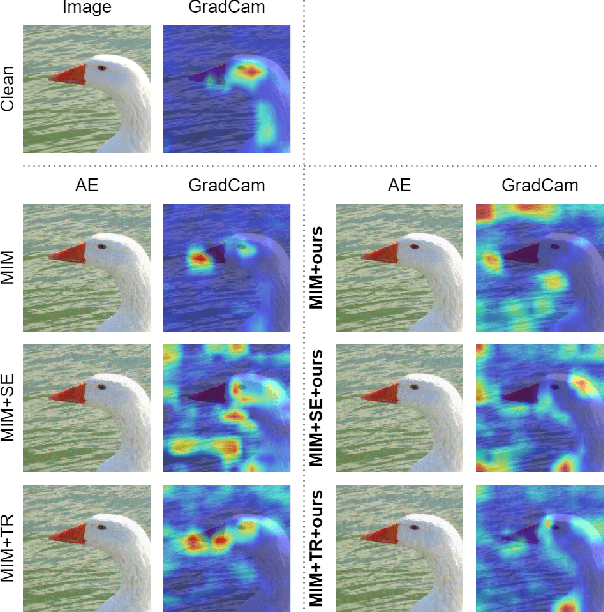

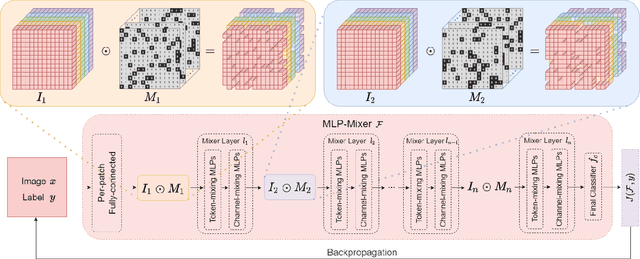
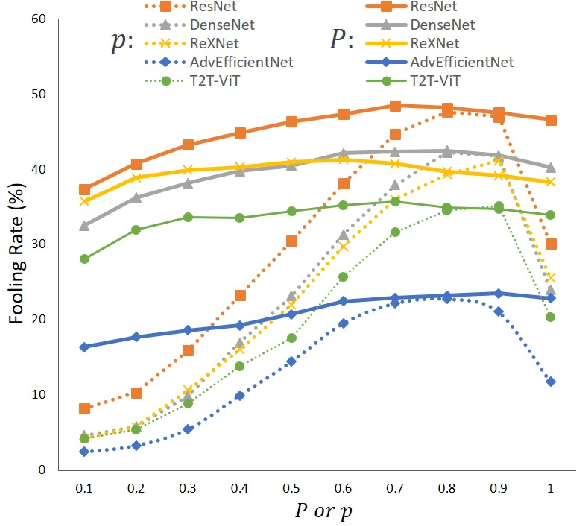
The security of models based on new architectures such as MLP-Mixer and ViTs needs to be studied urgently. However, most of the current researches are mainly aimed at the adversarial attack against ViTs, and there is still relatively little adversarial work on MLP-mixer. We propose an adversarial attack method against MLP-Mixer called Maxwell's demon Attack (MA). MA breaks the channel-mixing and token-mixing mechanism of MLP-Mixer by controlling the part input of MLP-Mixer's each Mixer layer, and disturbs MLP-Mixer to obtain the main information of images. Our method can mask the part input of the Mixer layer, avoid overfitting of the adversarial examples to the source model, and improve the transferability of cross-architecture. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed MA. Our method can be easily combined with existing methods and can improve the transferability by up to 38.0% on MLP-based ResMLP. Adversarial examples produced by our method on MLP-Mixer are able to exceed the transferability of adversarial examples produced using DenseNet against CNNs. To the best of our knowledge, we are the first work to study adversarial transferability of MLP-Mixer.