 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Clean Label Backdoor Attack with Two-phase Specific Triggers
Jun 10, 2022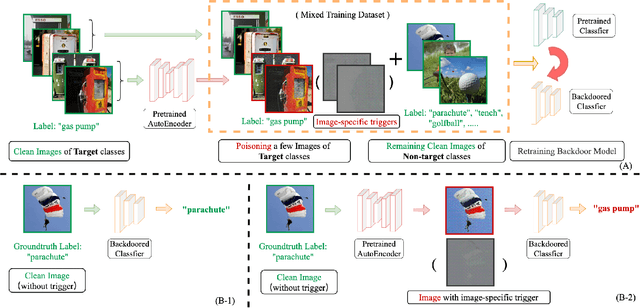
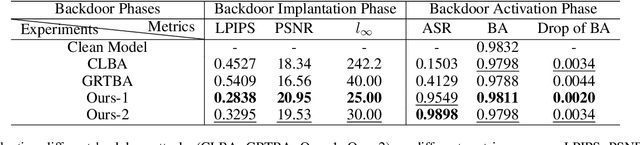

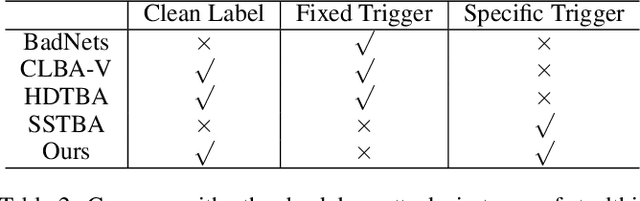
Backdoor attacks threaten Deep Neural Networks (DNNs). Towards stealthiness, researchers propose clean-label backdoor attacks, which require the adversaries not to alter the labels of the poisoned training datasets. Clean-label settings make the attack more stealthy due to the correct image-label pairs, but some problems still exist: first, traditional methods for poisoning training data are ineffective; second, traditional triggers are not stealthy which are still perceptible. To solve these problems, we propose a two-phase and image-specific triggers generation method to enhance clean-label backdoor attacks. Our methods are (1) powerful: our triggers can both promote the two phases (i.e., the backdoor implantation and activation phase) in backdoor attacks simultaneously; (2) stealthy: our triggers are generated from each image. They are image-specific instead of fixed triggers. Extensive experiments demonstrate that our approach can achieve a fantastic attack success rate~(98.98%) with low poisoning rate~(5%), high stealthiness under many evaluation metrics and is resistant to backdoor defense methods.
Boosting Adversarial Transferability of MLP-Mixer
Apr 26, 2022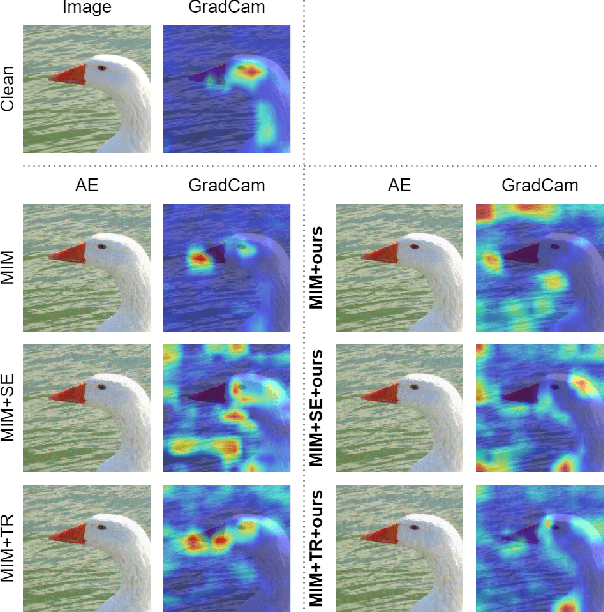

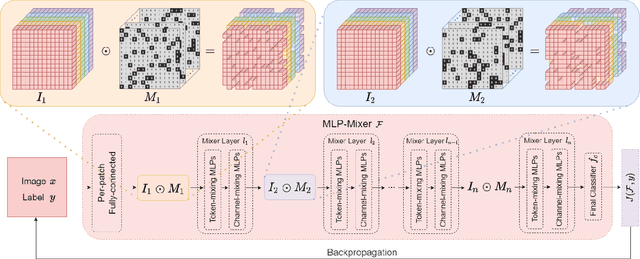
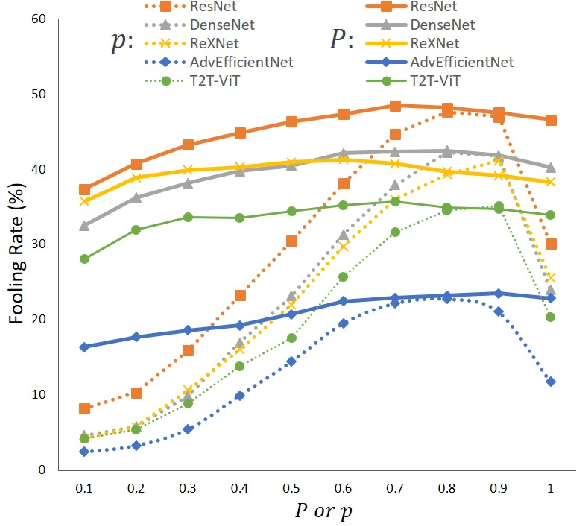
The security of models based on new architectures such as MLP-Mixer and ViTs needs to be studied urgently. However, most of the current researches are mainly aimed at the adversarial attack against ViTs, and there is still relatively little adversarial work on MLP-mixer. We propose an adversarial attack method against MLP-Mixer called Maxwell's demon Attack (MA). MA breaks the channel-mixing and token-mixing mechanism of MLP-Mixer by controlling the part input of MLP-Mixer's each Mixer layer, and disturbs MLP-Mixer to obtain the main information of images. Our method can mask the part input of the Mixer layer, avoid overfitting of the adversarial examples to the source model, and improve the transferability of cross-architecture. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed MA. Our method can be easily combined with existing methods and can improve the transferability by up to 38.0% on MLP-based ResMLP. Adversarial examples produced by our method on MLP-Mixer are able to exceed the transferability of adversarial examples produced using DenseNet against CNNs. To the best of our knowledge, we are the first work to study adversarial transferability of MLP-Mixer.
Demiguise Attack: Crafting Invisible Semantic Adversarial Perturbations with Perceptual Similarity
Jul 03, 2021



Deep neural networks (DNNs) have been found to be vulnerable to adversarial examples. Adversarial examples are malicious images with visually imperceptible perturbations. While these carefully crafted perturbations restricted with tight $\Lp$ norm bounds are small, they are still easily perceivable by humans. These perturbations also have limited success rates when attacking black-box models or models with defenses like noise reduction filters. To solve these problems, we propose Demiguise Attack, crafting ``unrestricted'' perturbations with Perceptual Similarity. Specifically, we can create powerful and photorealistic adversarial examples by manipulating semantic information based on Perceptual Similarity. Adversarial examples we generate are friendly to the human visual system (HVS), although the perturbations are of large magnitudes. We extend widely-used attacks with our approach, enhancing adversarial effectiveness impressively while contributing to imperceptibility. Extensive experiments show that the proposed method not only outperforms various state-of-the-art attacks in terms of fooling rate, transferability, and robustness against defenses but can also improve attacks effectively. In addition, we also notice that our implementation can simulate illumination and contrast changes that occur in real-world scenarios, which will contribute to exposing the blind spots of DNNs.