 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeY-BotFrame: An Extensible Embodied Agent Framework for Quadruped Robot Assistants
Jun 11, 2026Quadruped robots are capable of traversing a wide range of complex terrains with high flexibility. As highly mobile ground-based intelligent platforms, they can be equipped with modules for navigation control, environmental perception, and intelligent interaction, thereby serving as real-world mobile deployment platforms for various algorithms. In this paper, we introduce Y-BotFrame, an extensible embodied platform that turns a robot into an intelligent ground assistant. Y-BotFrame integrates multimodal perception capabilities, including speech, vision, and LiDAR, and employs a large language model as the cognitive core for environmental understanding, contextual reasoning, and task planning. The system maps user natural-language instructions into executable embodied task units that can be carried out by the robot. Y-BotFrame supports natural interaction through voice commands and visual feedback, removing the need for a remote controller and enabling efficient human-robot collaboration. With a highly extensible framework, Y-BotFrame supports plug-and-play integration of new functional modules as well as modular upgrades and iterative development, offering a reference implementation for the real-world deployment of general-purpose, instruction-driven embodied agents.The supplementary video is available at https://xdei-group.github.io/Y-BotFrame/.
AerialClaw: An Open-Source Framework for LLM-Driven Autonomous Aerial Agents
Jun 10, 2026Unmanned aerial vehicles (UAVs) are increasingly used in inspection, search and rescue, environmental monitoring, and emergency response. However, most UAV applications still rely on pre-defined command sequences or task-specific pipelines, where developers manually connect perception, planning, flight control, simulation, logging, and safety modules. This limits the flexibility, reproducibility, and extensibility of autonomous aerial systems. This paper presents AerialClaw, an open-source software framework that enables UAVs to operate as decision-making aerial agents rather than merely command-following platforms. Given a natural-language mission, AerialClaw allows an LLM-based agent to understand the task, maintain context, invoke executable aerial skills, observe perception and runtime feedback, and iteratively update its decisions in a closed loop. The framework adopts a modular brain-skill-runtime architecture, combining hard skills for atomic UAV operations, Markdown-based soft skills for reusable task strategies, document-driven agent state and capability boundaries, memory-driven reflection, safety-oriented runtime validation, and platform-agnostic execution adapters. AerialClaw supports lightweight mock execution, PX4 SITL with Gazebo, and AirSim-based simulation, together with a web console, pluggable model backends, example missions, simulation assets, and staged deployment scripts. By combining standardized aerial skills, document-driven agent state, memory, and closed-loop LLM decision-making, AerialClaw provides a reproducible and extensible open-source framework for building UAV systems that can interpret missions, make decisions, execute skills, and adapt their behavior from feedback.
Improving Few-Shot Change Detection Visual Question Answering via Decision-Ambiguity-guided Reinforcement Fine-Tuning
Dec 31, 2025Change detection visual question answering (CDVQA) requires answering text queries by reasoning about semantic changes in bi-temporal remote sensing images. A straightforward approach is to boost CDVQA performance with generic vision-language models via supervised fine-tuning (SFT). Despite recent progress, we observe that a significant portion of failures do not stem from clearly incorrect predictions, but from decision ambiguity, where the model assigns similar confidence to the correct answer and strong distractors. To formalize this challenge, we define Decision-Ambiguous Samples (DAS) as instances with a small probability margin between the ground-truth answer and the most competitive alternative. We argue that explicitly optimizing DAS is crucial for improving the discriminability and robustness of CDVQA models. To this end, we propose DARFT, a Decision-Ambiguity-guided Reinforcement Fine-Tuning framework that first mines DAS using an SFT-trained reference policy and then applies group-relative policy optimization on the mined subset. By leveraging multi-sample decoding and intra-group relative advantages, DARFT suppresses strong distractors and sharpens decision boundaries without additional supervision. Extensive experiments demonstrate consistent gains over SFT baselines, particularly under few-shot settings.
Enhancing Clean Label Backdoor Attack with Two-phase Specific Triggers
Jun 10, 2022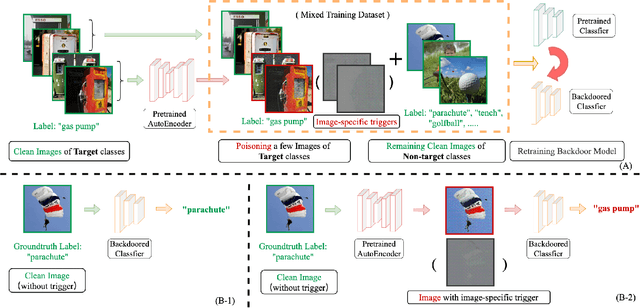
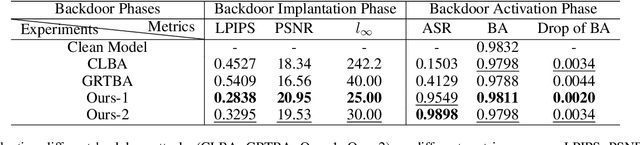

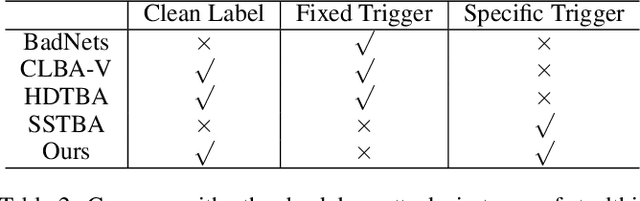
Backdoor attacks threaten Deep Neural Networks (DNNs). Towards stealthiness, researchers propose clean-label backdoor attacks, which require the adversaries not to alter the labels of the poisoned training datasets. Clean-label settings make the attack more stealthy due to the correct image-label pairs, but some problems still exist: first, traditional methods for poisoning training data are ineffective; second, traditional triggers are not stealthy which are still perceptible. To solve these problems, we propose a two-phase and image-specific triggers generation method to enhance clean-label backdoor attacks. Our methods are (1) powerful: our triggers can both promote the two phases (i.e., the backdoor implantation and activation phase) in backdoor attacks simultaneously; (2) stealthy: our triggers are generated from each image. They are image-specific instead of fixed triggers. Extensive experiments demonstrate that our approach can achieve a fantastic attack success rate~(98.98%) with low poisoning rate~(5%), high stealthiness under many evaluation metrics and is resistant to backdoor defense methods.
Enhanced CNN for image denoising
Nov 05, 2018
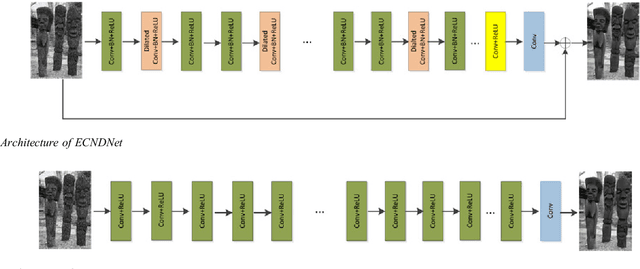
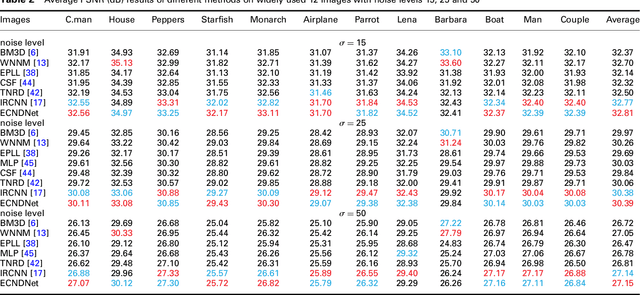
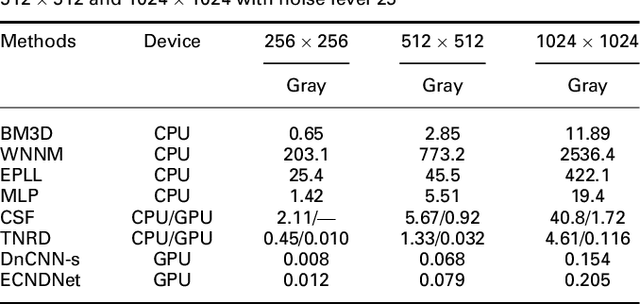
Due to the flexible architectures of deep convolutional neural networks (CNNs), which are successfully used for image denoising. However, they suffer from the following drawbacks: (1) deep network architecture is very difficult to be train. (2) Very deep networks face the challenge of performance saturation. In this paper, we propose a novel method called enhanced convolutional neural denoising network (ECNDNet). Specifically, we use residual learning and batch normalization (BN) techniques to address the problem of training difficulties and accelerate the convergence of the network. In addition, dilated convolutions are used in our network to enlarge the context information and reduce the computational cost. Extensive experiments demonstrate that our ECNDNet outperforms the state-of-the-art methods such as IRCNN for image denoising.