 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Factorial Linear Dynamical Systems for Transient Signal Detection
Jan 09, 2025



Accurately detecting the transient signal of interest from the background signal is one of the fundamental tasks in signal processing. The most recent approaches assume the existence of a single background source and represent the background signal using a linear dynamical system (LDS). This assumption might fail to capture the complexities of modern electromagnetic environments with multiple sources. To address this limitation, this paper proposes a method for detecting the transient signal in a background composed of an unknown number of emitters. The proposed method consists of two main tasks. First, a Bayesian nonparametric model called the infinite factorial linear dynamical system (IFLDS) is developed. The developed model is based on the sticky Indian buffet process and enables the representation and parameter learning of the unbounded number of background sources. This study also designs a parameter learning method for the IFLDS using slice sampling and particle Gibbs with ancestor sampling. Second, the finite moving average (FMA) stopping time is introduced to minimize the worst-case probability of missed detection, and the statistical performance of the stopping time is investigated. To facilitate the computation of the FMA stopping time, this study derives the factorial Kalman forward filtering (FKFF) method and designs a dependence structure for the underlying model, allowing the stopping time to be defined by a recursive function. Numerical simulations demonstrate the effectiveness of the proposed method and the validity of the theoretical results. The experimental results of the pulse signal detection under the condition of communication interference confirm the effectiveness and superiority of the proposed method.
Representation and De-interleaving of Mixtures of Hidden Markov Processes
Jun 01, 2024



De-interleaving of the mixtures of Hidden Markov Processes (HMPs) generally depends on its representation model. Existing representation models consider Markov chain mixtures rather than hidden Markov, resulting in the lack of robustness to non-ideal situations such as observation noise or missing observations. Besides, de-interleaving methods utilize a search-based strategy, which is time-consuming. To address these issues, this paper proposes a novel representation model and corresponding de-interleaving methods for the mixtures of HMPs. At first, a generative model for representing the mixtures of HMPs is designed. Subsequently, the de-interleaving process is formulated as a posterior inference for the generative model. Secondly, an exact inference method is developed to maximize the likelihood of the complete data, and two approximate inference methods are developed to maximize the evidence lower bound by creating tractable structures. Then, a theoretical error probability lower bound is derived using the likelihood ratio test, and the algorithms are shown to get reasonably close to the bound. Finally, simulation results demonstrate that the proposed methods are highly effective and robust for non-ideal situations, outperforming baseline methods on simulated and real-life data.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Class Information Guided Reconstruction for Automatic Modulation Open-Set Recognition
Dec 20, 2023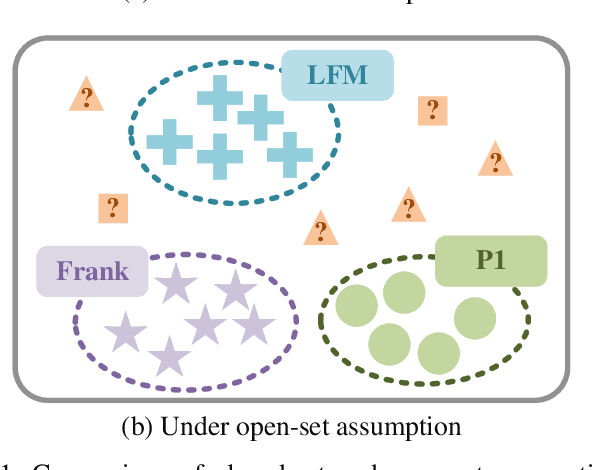



Automatic Modulation Recognition (AMR) is a crucial technology in the domains of radar and communications. Traditional AMR approaches assume a closed-set scenario, where unknown samples are forcibly misclassified into known classes, leading to serious consequences for situation awareness and threat assessment. To address this issue, Automatic Modulation Open-set Recognition (AMOSR) defines two tasks as Known Class Classification (KCC) and Unknown Class Identification (UCI). However, AMOSR faces core challenges in terms of inappropriate decision boundaries and sparse feature distributions. To overcome the aforementioned challenges, we propose a Class Information guided Reconstruction (CIR) framework, which leverages reconstruction losses to distinguish known and unknown classes. To enhance distinguishability, we design Class Conditional Vectors (CCVs) to match the latent representations extracted from input samples, achieving perfect reconstruction for known samples while yielding poor results for unknown ones. We also propose a Mutual Information (MI) loss function to ensure reliable matching, with upper and lower bounds of MI derived for tractable optimization and mathematical proofs provided. The mutually beneficial CCVs and MI facilitate the CIR attaining optimal UCI performance without compromising KCC accuracy, especially in scenarios with a higher proportion of unknown classes. Additionally, a denoising module is introduced before reconstruction, enabling the CIR to achieve a significant performance improvement at low SNRs. Experimental results on simulated and measured signals validate the effectiveness and the robustness of the proposed method.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Concealed Electronic Countermeasures of Radar Signal with Adversarial Examples
Oct 12, 2023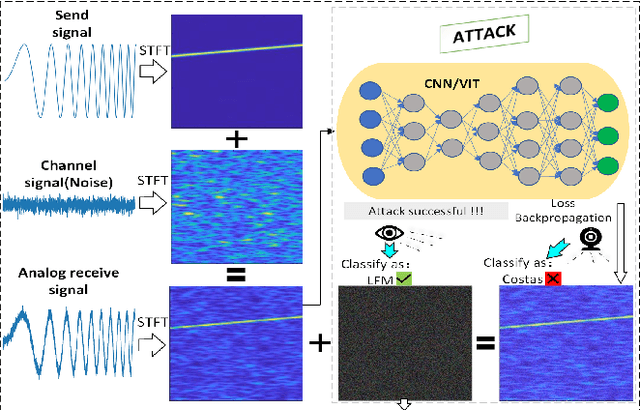
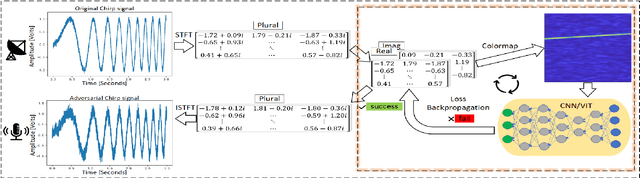


Electronic countermeasures involving radar signals are an important aspect of modern warfare. Traditional electronic countermeasures techniques typically add large-scale interference signals to ensure interference effects, which can lead to attacks being too obvious. In recent years, AI-based attack methods have emerged that can effectively solve this problem, but the attack scenarios are currently limited to time domain radar signal classification. In this paper, we focus on the time-frequency images classification scenario of radar signals. We first propose an attack pipeline under the time-frequency images scenario and DITIMI-FGSM attack algorithm with high transferability. Then, we propose STFT-based time domain signal attack(STDS) algorithm to solve the problem of non-invertibility in time-frequency analysis, thus obtaining the time-domain representation of the interference signal. A large number of experiments show that our attack pipeline is feasible and the proposed attack method has a high success rate.
Online Parameter Estimation and Change Point Detection for Multi-function Radar Pulse Sequence Based on the Bayesian Non-parametric HMM
Feb 09, 2023


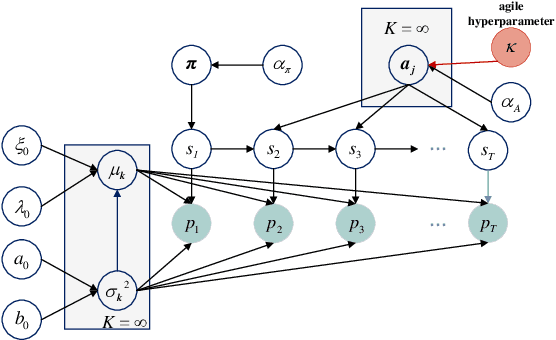
Multi-function radars (MFRs) are sophisticated types of sensors with the capabilities of complex agile inter-pulse modulation implementation and dynamic work mode scheduling. The developments in MFRs pose great challenges to modern electronic reconnaissance systems or radar warning receivers for recognition and inference of MFR work modes. To address this issue, this paper proposes an online processing framework for parameter estimation and change point detection of MFR work modes. At first this paper designed a fully-conjugate Bayesian non-parametric hidden Markov model with a designed prior (agile BNP-HMM) to represent the MFR pulse agility characteristics. The proposed model allows fully-variational Bayesian inference. Then, the proposed framework is constructed by two main parts. The first part is the agile BNP-HMM model for automatically inferring data on pulse parameter clusters and corresponding number of clusters from input pulse sequence. The second part utilizes the streaming Bayesian updating to facilitate computation, and designed a online work mode change detection framework based upon a family of one-ended sequential probability ratio test. We demonstrate that the proposed framework is consistently highly effective and robust to baseline methods on diverse simulated data-sets.