 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models with Reward-guided Tree Search for Knowledge Graph Question and Answering
May 18, 2025Recently, large language models (LLMs) have demonstrated impressive performance in Knowledge Graph Question Answering (KGQA) tasks, which aim to find answers based on knowledge graphs (KGs) for natural language questions. Existing LLMs-based KGQA methods typically follow the Graph Retrieval-Augmented Generation (GraphRAG) paradigm, which first retrieves reasoning paths from the large KGs, and then generates the answers based on them. However, these methods emphasize the exploration of new optimal reasoning paths in KGs while ignoring the exploitation of historical reasoning paths, which may lead to sub-optimal reasoning paths. Additionally, the complex semantics contained in questions may lead to the retrieval of inaccurate reasoning paths. To address these issues, this paper proposes a novel and training-free framework for KGQA tasks called Reward-guided Tree Search on Graph (RTSoG). RTSoG decomposes an original question into a series of simpler and well-defined sub-questions to handle the complex semantics. Then, a Self-Critic Monte Carlo Tree Search (SC-MCTS) guided by a reward model is introduced to iteratively retrieve weighted reasoning paths as contextual knowledge. Finally, it stacks the weighted reasoning paths according to their weights to generate the final answers. Extensive experiments on four datasets demonstrate the effectiveness of RTSoG. Notably, it achieves 8.7\% and 7.0\% performance improvement over the state-of-the-art method on the GrailQA and the WebQSP respectively.
EPERM: An Evidence Path Enhanced Reasoning Model for Knowledge Graph Question and Answering
Feb 22, 2025

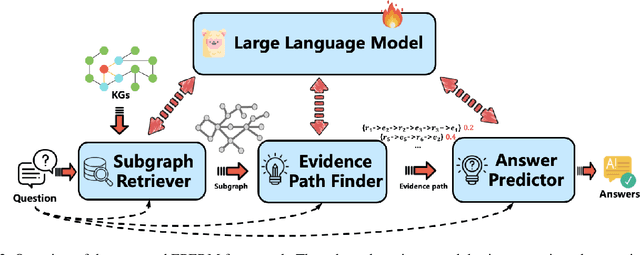

Due to the remarkable reasoning ability, Large language models (LLMs) have demonstrated impressive performance in knowledge graph question answering (KGQA) tasks, which find answers to natural language questions over knowledge graphs (KGs). To alleviate the hallucinations and lack of knowledge issues of LLMs, existing methods often retrieve the question-related information from KGs to enrich the input context. However, most methods focus on retrieving the relevant information while ignoring the importance of different types of knowledge in reasoning, which degrades their performance. To this end, this paper reformulates the KGQA problem as a graphical model and proposes a three-stage framework named the Evidence Path Enhanced Reasoning Model (EPERM) for KGQA. In the first stage, EPERM uses the fine-tuned LLM to retrieve a subgraph related to the question from the original knowledge graph. In the second stage, EPERM filters out the evidence paths that faithfully support the reasoning of the questions, and score their importance in reasoning. Finally, EPERM uses the weighted evidence paths to reason the final answer. Since considering the importance of different structural information in KGs for reasoning, EPERM can improve the reasoning ability of LLMs in KGQA tasks. Extensive experiments on benchmark datasets demonstrate that EPERM achieves superior performances in KGQA tasks.
Test-time Loss Landscape Adaptation for Zero-Shot Generalization in Vision-Language Models
Jan 31, 2025



Test-time adaptation of pre-trained vision-language models has emerged as a technique for tackling distribution shifts during the test time. Although existing methods, especially those based on Test-time Prompt Tuning (TPT), have shown promising results, their high computational cost associated with parameter optimization presents challenges for scalability and practical application. This paper unveils the unnecessary nature of backpropagation in existing methods from a loss landscape perspective. Building on this insight, this paper proposes a simple yet effective framework called Test-time Loss Landscape Adaptation (TLLA). TLLA leverages the relative position between the training minimum and test loss landscapes to guide the adaptation process, avoiding the update of model parameters at test time. Specifically, it mainly consists of two main stages: In the prompt tuning stage, a Sharpness-Aware Prompt Tuning (SAPT) method is introduced to identify the training flat minimum, setting the foundation for the subsequent test-time adaptation; In the test stage, a Sharpness-based Test Sample Selection (STSS) approach is utilized to ensure the alignment of flat minima within the training loss landscape and each augmented test sample's loss landscape. Extensive experiments on both domain generalization and cross-dataset benchmarks demonstrate that TLLA achieves state-of-the-art performances while significantly reducing computational overhead. Notably, TLLA surpasses TPT by an average of 5.32\% and 6.98\% on four ImageNet variant datasets when employing ResNet50 and ViT-B/16 image encoders, respectively. The code will be available soon.
Infinite Factorial Linear Dynamical Systems for Transient Signal Detection
Jan 09, 2025



Accurately detecting the transient signal of interest from the background signal is one of the fundamental tasks in signal processing. The most recent approaches assume the existence of a single background source and represent the background signal using a linear dynamical system (LDS). This assumption might fail to capture the complexities of modern electromagnetic environments with multiple sources. To address this limitation, this paper proposes a method for detecting the transient signal in a background composed of an unknown number of emitters. The proposed method consists of two main tasks. First, a Bayesian nonparametric model called the infinite factorial linear dynamical system (IFLDS) is developed. The developed model is based on the sticky Indian buffet process and enables the representation and parameter learning of the unbounded number of background sources. This study also designs a parameter learning method for the IFLDS using slice sampling and particle Gibbs with ancestor sampling. Second, the finite moving average (FMA) stopping time is introduced to minimize the worst-case probability of missed detection, and the statistical performance of the stopping time is investigated. To facilitate the computation of the FMA stopping time, this study derives the factorial Kalman forward filtering (FKFF) method and designs a dependence structure for the underlying model, allowing the stopping time to be defined by a recursive function. Numerical simulations demonstrate the effectiveness of the proposed method and the validity of the theoretical results. The experimental results of the pulse signal detection under the condition of communication interference confirm the effectiveness and superiority of the proposed method.
Seeking Consistent Flat Minima for Better Domain Generalization via Refining Loss Landscapes
Dec 18, 2024



Domain generalization aims to learn a model from multiple training domains and generalize it to unseen test domains. Recent theory has shown that seeking the deep models, whose parameters lie in the flat minima of the loss landscape, can significantly reduce the out-of-domain generalization error. However, existing methods often neglect the consistency of loss landscapes in different domains, resulting in models that are not simultaneously in the optimal flat minima in all domains, which limits their generalization ability. To address this issue, this paper proposes an iterative Self-Feedback Training (SFT) framework to seek consistent flat minima that are shared across different domains by progressively refining loss landscapes during training. It alternatively generates a feedback signal by measuring the inconsistency of loss landscapes in different domains and refines these loss landscapes for greater consistency using this feedback signal. Benefiting from the consistency of the flat minima within these refined loss landscapes, our SFT helps achieve better out-of-domain generalization. Extensive experiments on DomainBed demonstrate superior performances of SFT when compared to state-of-the-art sharpness-aware methods and other prevalent DG baselines. On average across five DG benchmarks, SFT surpasses the sharpness-aware minimization by 2.6% with ResNet-50 and 1.5% with ViT-B/16, respectively. The code will be available soon.
Cost-Effective RF Fingerprinting Based on Hybrid CVNN-RF Classifier with Automated Multi-Dimensional Early-Exit Strategy
Jun 21, 2024



While the Internet of Things (IoT) technology is booming and offers huge opportunities for information exchange, it also faces unprecedented security challenges. As an important complement to the physical layer security technologies for IoT, radio frequency fingerprinting (RFF) is of great interest due to its difficulty in counterfeiting. Recently, many machine learning (ML)-based RFF algorithms have emerged. In particular, deep learning (DL) has shown great benefits in automatically extracting complex and subtle features from raw data with high classification accuracy. However, DL algorithms face the computational cost problem as the difficulty of the RFF task and the size of the DNN have increased dramatically. To address the above challenge, this paper proposes a novel costeffective early-exit neural network consisting of a complex-valued neural network (CVNN) backbone with multiple random forest branches, called hybrid CVNN-RF. Unlike conventional studies that use a single fixed DL model to process all RF samples, our hybrid CVNN-RF considers differences in the recognition difficulty of RF samples and introduces an early-exit mechanism to dynamically process the samples. When processing "easy" samples that can be well classified with high confidence, the hybrid CVNN-RF can end early at the random forest branch to reduce computational cost. Conversely, subsequent network layers will be activated to ensure accuracy. To further improve the early-exit rate, an automated multi-dimensional early-exit strategy is proposed to achieve scheduling control from multiple dimensions within the network depth and classification category. Finally, our experiments on the public ADS-B dataset show that the proposed algorithm can reduce the computational cost by 83% while improving the accuracy by 1.6% under a classification task with 100 categories.
Representation and De-interleaving of Mixtures of Hidden Markov Processes
Jun 01, 2024



De-interleaving of the mixtures of Hidden Markov Processes (HMPs) generally depends on its representation model. Existing representation models consider Markov chain mixtures rather than hidden Markov, resulting in the lack of robustness to non-ideal situations such as observation noise or missing observations. Besides, de-interleaving methods utilize a search-based strategy, which is time-consuming. To address these issues, this paper proposes a novel representation model and corresponding de-interleaving methods for the mixtures of HMPs. At first, a generative model for representing the mixtures of HMPs is designed. Subsequently, the de-interleaving process is formulated as a posterior inference for the generative model. Secondly, an exact inference method is developed to maximize the likelihood of the complete data, and two approximate inference methods are developed to maximize the evidence lower bound by creating tractable structures. Then, a theoretical error probability lower bound is derived using the likelihood ratio test, and the algorithms are shown to get reasonably close to the bound. Finally, simulation results demonstrate that the proposed methods are highly effective and robust for non-ideal situations, outperforming baseline methods on simulated and real-life data.
Mitigating Receiver Impact on Radio Frequency Fingerprint Identification via Domain Adaptation
Apr 12, 2024Radio Frequency Fingerprint Identification (RFFI), which exploits non-ideal hardware-induced unique distortion resident in the transmit signals to identify an emitter, is emerging as a means to enhance the security of communication systems. Recently, machine learning has achieved great success in developing state-of-the-art RFFI models. However, few works consider cross-receiver RFFI problems, where the RFFI model is trained and deployed on different receivers. Due to altered receiver characteristics, direct deployment of RFFI model on a new receiver leads to significant performance degradation. To address this issue, we formulate the cross-receiver RFFI as a model adaptation problem, which adapts the trained model to unlabeled signals from a new receiver. We first develop a theoretical generalization error bound for the adaptation model. Motivated by the bound, we propose a novel method to solve the cross-receiver RFFI problem, which includes domain alignment and adaptive pseudo-labeling. The former aims at finding a feature space where both domains exhibit similar distributions, effectively reducing the domain discrepancy. Meanwhile, the latter employs a dynamic pseudo-labeling scheme to implicitly transfer the label information from the labeled receiver to the new receiver. Experimental results indicate that the proposed method can effectively mitigate the receiver impact and improve the cross-receiver RFFI performance.
Class Information Guided Reconstruction for Automatic Modulation Open-Set Recognition
Dec 20, 2023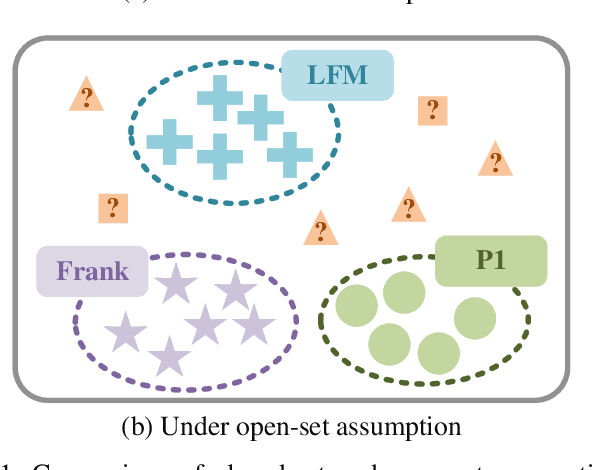



Automatic Modulation Recognition (AMR) is a crucial technology in the domains of radar and communications. Traditional AMR approaches assume a closed-set scenario, where unknown samples are forcibly misclassified into known classes, leading to serious consequences for situation awareness and threat assessment. To address this issue, Automatic Modulation Open-set Recognition (AMOSR) defines two tasks as Known Class Classification (KCC) and Unknown Class Identification (UCI). However, AMOSR faces core challenges in terms of inappropriate decision boundaries and sparse feature distributions. To overcome the aforementioned challenges, we propose a Class Information guided Reconstruction (CIR) framework, which leverages reconstruction losses to distinguish known and unknown classes. To enhance distinguishability, we design Class Conditional Vectors (CCVs) to match the latent representations extracted from input samples, achieving perfect reconstruction for known samples while yielding poor results for unknown ones. We also propose a Mutual Information (MI) loss function to ensure reliable matching, with upper and lower bounds of MI derived for tractable optimization and mathematical proofs provided. The mutually beneficial CCVs and MI facilitate the CIR attaining optimal UCI performance without compromising KCC accuracy, especially in scenarios with a higher proportion of unknown classes. Additionally, a denoising module is introduced before reconstruction, enabling the CIR to achieve a significant performance improvement at low SNRs. Experimental results on simulated and measured signals validate the effectiveness and the robustness of the proposed method.
Online Parameter Estimation and Change Point Detection for Multi-function Radar Pulse Sequence Based on the Bayesian Non-parametric HMM
Feb 09, 2023


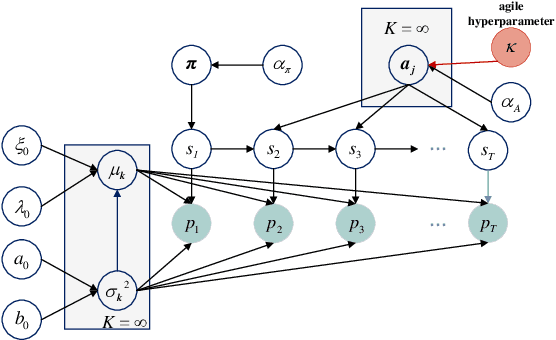
Multi-function radars (MFRs) are sophisticated types of sensors with the capabilities of complex agile inter-pulse modulation implementation and dynamic work mode scheduling. The developments in MFRs pose great challenges to modern electronic reconnaissance systems or radar warning receivers for recognition and inference of MFR work modes. To address this issue, this paper proposes an online processing framework for parameter estimation and change point detection of MFR work modes. At first this paper designed a fully-conjugate Bayesian non-parametric hidden Markov model with a designed prior (agile BNP-HMM) to represent the MFR pulse agility characteristics. The proposed model allows fully-variational Bayesian inference. Then, the proposed framework is constructed by two main parts. The first part is the agile BNP-HMM model for automatically inferring data on pulse parameter clusters and corresponding number of clusters from input pulse sequence. The second part utilizes the streaming Bayesian updating to facilitate computation, and designed a online work mode change detection framework based upon a family of one-ended sequential probability ratio test. We demonstrate that the proposed framework is consistently highly effective and robust to baseline methods on diverse simulated data-sets.