 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPERM: An Evidence Path Enhanced Reasoning Model for Knowledge Graph Question and Answering
Feb 22, 2025

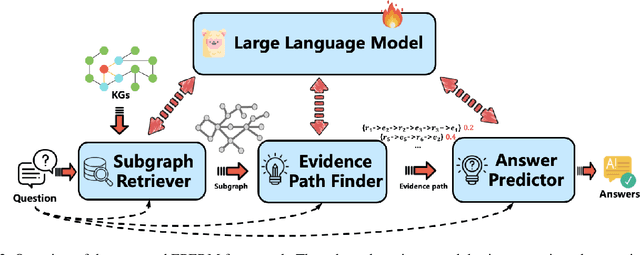

Due to the remarkable reasoning ability, Large language models (LLMs) have demonstrated impressive performance in knowledge graph question answering (KGQA) tasks, which find answers to natural language questions over knowledge graphs (KGs). To alleviate the hallucinations and lack of knowledge issues of LLMs, existing methods often retrieve the question-related information from KGs to enrich the input context. However, most methods focus on retrieving the relevant information while ignoring the importance of different types of knowledge in reasoning, which degrades their performance. To this end, this paper reformulates the KGQA problem as a graphical model and proposes a three-stage framework named the Evidence Path Enhanced Reasoning Model (EPERM) for KGQA. In the first stage, EPERM uses the fine-tuned LLM to retrieve a subgraph related to the question from the original knowledge graph. In the second stage, EPERM filters out the evidence paths that faithfully support the reasoning of the questions, and score their importance in reasoning. Finally, EPERM uses the weighted evidence paths to reason the final answer. Since considering the importance of different structural information in KGs for reasoning, EPERM can improve the reasoning ability of LLMs in KGQA tasks. Extensive experiments on benchmark datasets demonstrate that EPERM achieves superior performances in KGQA tasks.
Test-time Loss Landscape Adaptation for Zero-Shot Generalization in Vision-Language Models
Jan 31, 2025



Test-time adaptation of pre-trained vision-language models has emerged as a technique for tackling distribution shifts during the test time. Although existing methods, especially those based on Test-time Prompt Tuning (TPT), have shown promising results, their high computational cost associated with parameter optimization presents challenges for scalability and practical application. This paper unveils the unnecessary nature of backpropagation in existing methods from a loss landscape perspective. Building on this insight, this paper proposes a simple yet effective framework called Test-time Loss Landscape Adaptation (TLLA). TLLA leverages the relative position between the training minimum and test loss landscapes to guide the adaptation process, avoiding the update of model parameters at test time. Specifically, it mainly consists of two main stages: In the prompt tuning stage, a Sharpness-Aware Prompt Tuning (SAPT) method is introduced to identify the training flat minimum, setting the foundation for the subsequent test-time adaptation; In the test stage, a Sharpness-based Test Sample Selection (STSS) approach is utilized to ensure the alignment of flat minima within the training loss landscape and each augmented test sample's loss landscape. Extensive experiments on both domain generalization and cross-dataset benchmarks demonstrate that TLLA achieves state-of-the-art performances while significantly reducing computational overhead. Notably, TLLA surpasses TPT by an average of 5.32\% and 6.98\% on four ImageNet variant datasets when employing ResNet50 and ViT-B/16 image encoders, respectively. The code will be available soon.
Seeking Consistent Flat Minima for Better Domain Generalization via Refining Loss Landscapes
Dec 18, 2024



Domain generalization aims to learn a model from multiple training domains and generalize it to unseen test domains. Recent theory has shown that seeking the deep models, whose parameters lie in the flat minima of the loss landscape, can significantly reduce the out-of-domain generalization error. However, existing methods often neglect the consistency of loss landscapes in different domains, resulting in models that are not simultaneously in the optimal flat minima in all domains, which limits their generalization ability. To address this issue, this paper proposes an iterative Self-Feedback Training (SFT) framework to seek consistent flat minima that are shared across different domains by progressively refining loss landscapes during training. It alternatively generates a feedback signal by measuring the inconsistency of loss landscapes in different domains and refines these loss landscapes for greater consistency using this feedback signal. Benefiting from the consistency of the flat minima within these refined loss landscapes, our SFT helps achieve better out-of-domain generalization. Extensive experiments on DomainBed demonstrate superior performances of SFT when compared to state-of-the-art sharpness-aware methods and other prevalent DG baselines. On average across five DG benchmarks, SFT surpasses the sharpness-aware minimization by 2.6% with ResNet-50 and 1.5% with ViT-B/16, respectively. The code will be available soon.
One-shot Key Information Extraction from Document with Deep Partial Graph Matching
Sep 26, 2021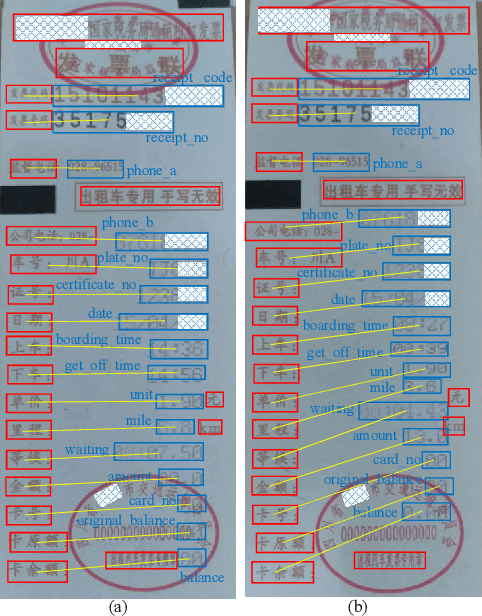
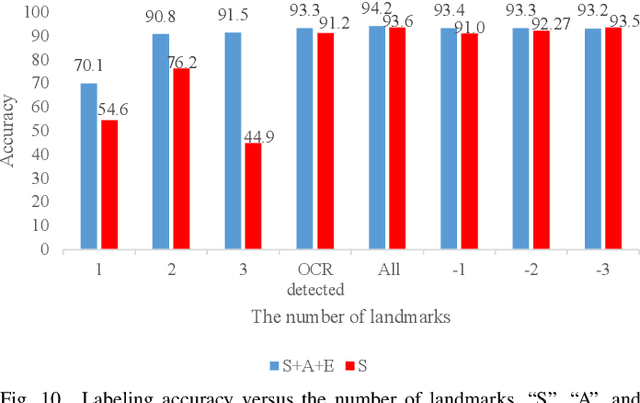
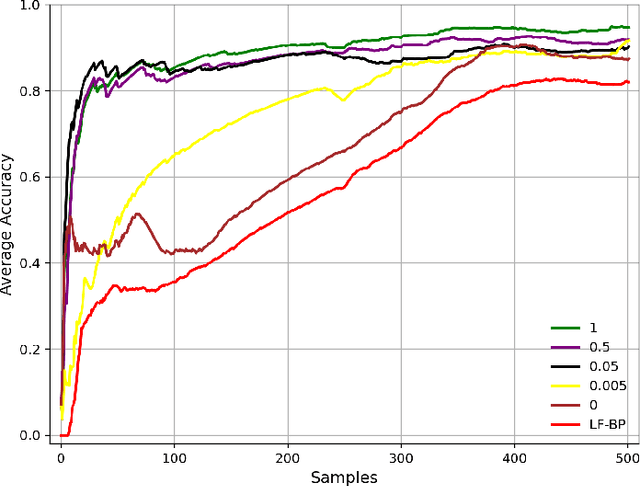
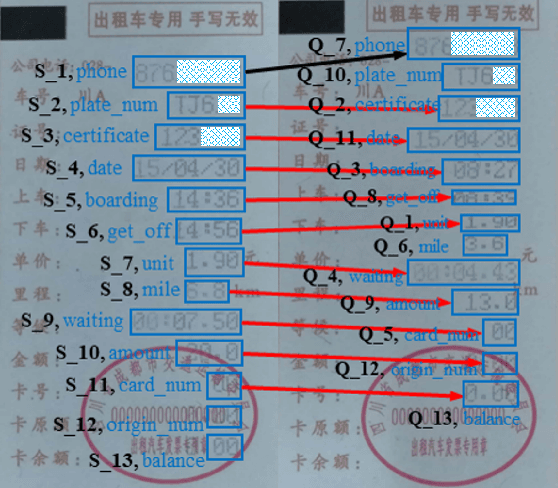
Automating the Key Information Extraction (KIE) from documents improves efficiency, productivity, and security in many industrial scenarios such as rapid indexing and archiving. Many existing supervised learning methods for the KIE task need to feed a large number of labeled samples and learn separate models for different types of documents. However, collecting and labeling a large dataset is time-consuming and is not a user-friendly requirement for many cloud platforms. To overcome these challenges, we propose a deep end-to-end trainable network for one-shot KIE using partial graph matching. Contrary to previous methods that the learning of similarity and solving are optimized separately, our method enables the learning of the two processes in an end-to-end framework. Existing one-shot KIE methods are either template or simple attention-based learning approach that struggle to handle texts that are shifted beyond their desired positions caused by printers, as illustrated in Fig.1. To solve this problem, we add one-to-(at most)-one constraint such that we will find the globally optimized solution even if some texts are drifted. Further, we design a multimodal context ensemble block to boost the performance through fusing features of spatial, textual, and aspect representations. To promote research of KIE, we collected and annotated a one-shot document KIE dataset named DKIE with diverse types of images. The DKIE dataset consists of 2.5K document images captured by mobile phones in natural scenes, and it is the largest available one-shot KIE dataset up to now. The results of experiments on DKIE show that our method achieved state-of-the-art performance compared with recent one-shot and supervised learning approaches. The dataset and proposed one-shot KIE model will be released soo