 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Transferable Adversarial Attacks with Centralized Perturbation
Dec 23, 2023
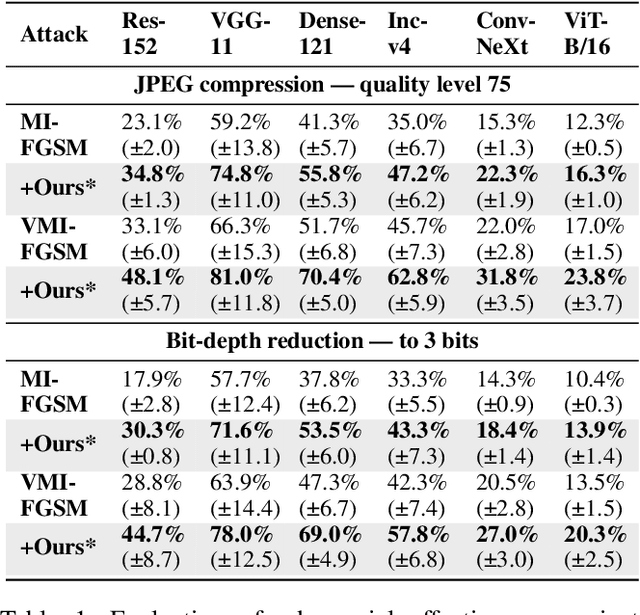
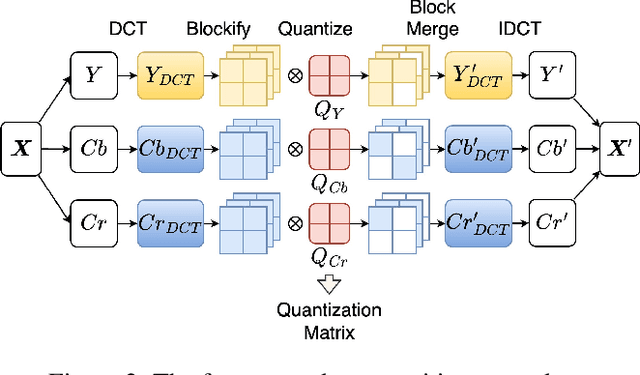
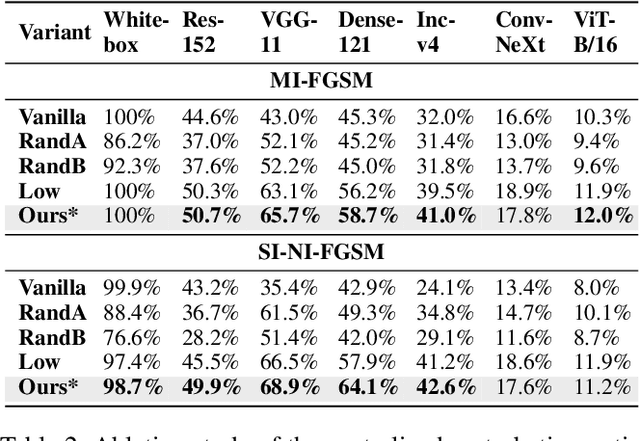
Adversarial transferability enables black-box attacks on unknown victim deep neural networks (DNNs), rendering attacks viable in real-world scenarios. Current transferable attacks create adversarial perturbation over the entire image, resulting in excessive noise that overfit the source model. Concentrating perturbation to dominant image regions that are model-agnostic is crucial to improving adversarial efficacy. However, limiting perturbation to local regions in the spatial domain proves inadequate in augmenting transferability. To this end, we propose a transferable adversarial attack with fine-grained perturbation optimization in the frequency domain, creating centralized perturbation. We devise a systematic pipeline to dynamically constrain perturbation optimization to dominant frequency coefficients. The constraint is optimized in parallel at each iteration, ensuring the directional alignment of perturbation optimization with model prediction. Our approach allows us to centralize perturbation towards sample-specific important frequency features, which are shared by DNNs, effectively mitigating source model overfitting. Experiments demonstrate that by dynamically centralizing perturbation on dominating frequency coefficients, crafted adversarial examples exhibit stronger transferability, and allowing them to bypass various defenses.
Unified High-binding Watermark for Unconditional Image Generation Models
Oct 14, 2023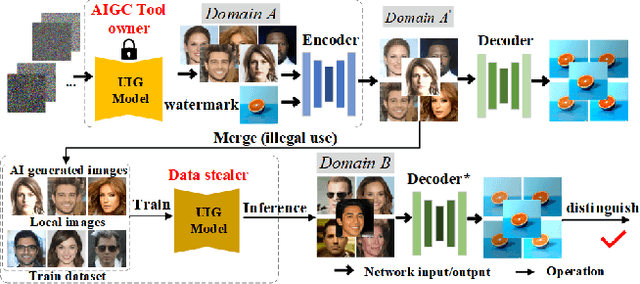
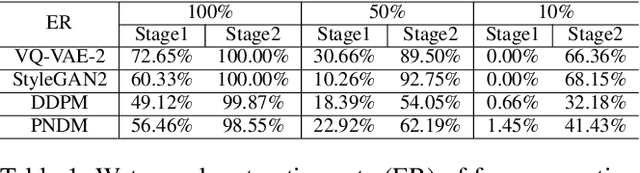
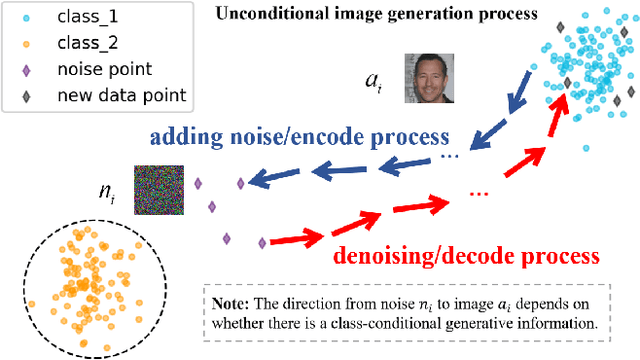
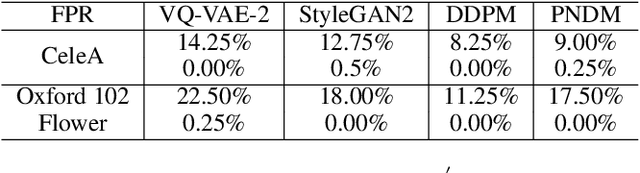
Deep learning techniques have implemented many unconditional image generation (UIG) models, such as GAN, Diffusion model, etc. The extremely realistic images (also known as AI-Generated Content, AIGC for short) produced by these models bring urgent needs for intellectual property protection such as data traceability and copyright certification. An attacker can steal the output images of the target model and use them as part of the training data to train a private surrogate UIG model. The implementation mechanisms of UIG models are diverse and complex, and there is no unified and effective protection and verification method at present. To address these issues, we propose a two-stage unified watermark verification mechanism with high-binding effects for such models. In the first stage, we use an encoder to invisibly write the watermark image into the output images of the original AIGC tool, and reversely extract the watermark image through the corresponding decoder. In the second stage, we design the decoder fine-tuning process, and the fine-tuned decoder can make correct judgments on whether the suspicious model steals the original AIGC tool data. Experiments demonstrate our method can complete the verification work with almost zero false positive rate under the condition of only using the model output images. Moreover, the proposed method can achieve data steal verification across different types of UIG models, which further increases the practicality of the method.
Concealed Electronic Countermeasures of Radar Signal with Adversarial Examples
Oct 12, 2023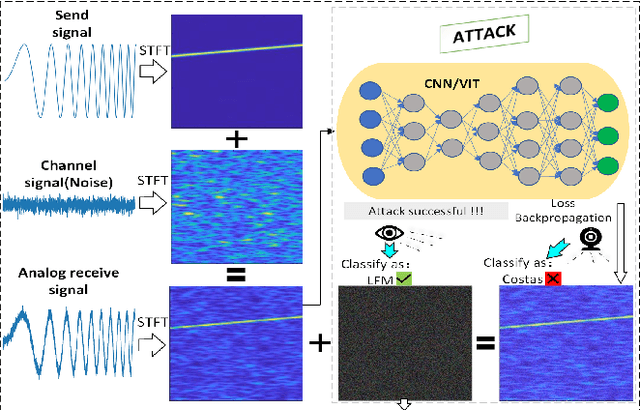
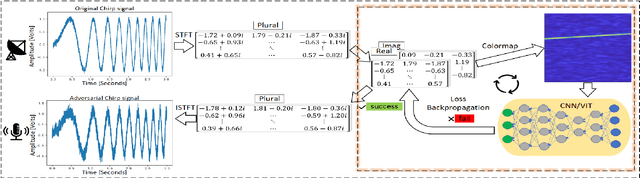


Electronic countermeasures involving radar signals are an important aspect of modern warfare. Traditional electronic countermeasures techniques typically add large-scale interference signals to ensure interference effects, which can lead to attacks being too obvious. In recent years, AI-based attack methods have emerged that can effectively solve this problem, but the attack scenarios are currently limited to time domain radar signal classification. In this paper, we focus on the time-frequency images classification scenario of radar signals. We first propose an attack pipeline under the time-frequency images scenario and DITIMI-FGSM attack algorithm with high transferability. Then, we propose STFT-based time domain signal attack(STDS) algorithm to solve the problem of non-invertibility in time-frequency analysis, thus obtaining the time-domain representation of the interference signal. A large number of experiments show that our attack pipeline is feasible and the proposed attack method has a high success rate.