 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified High-binding Watermark for Unconditional Image Generation Models
Paper and Code
Oct 14, 2023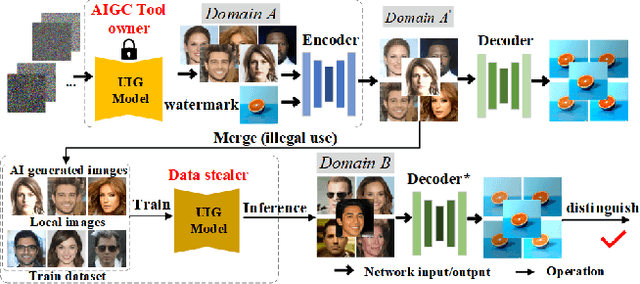
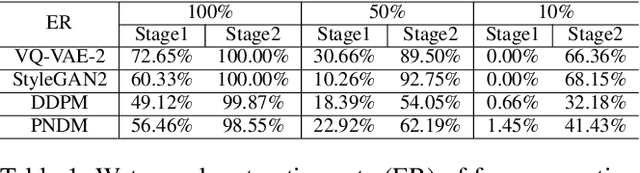
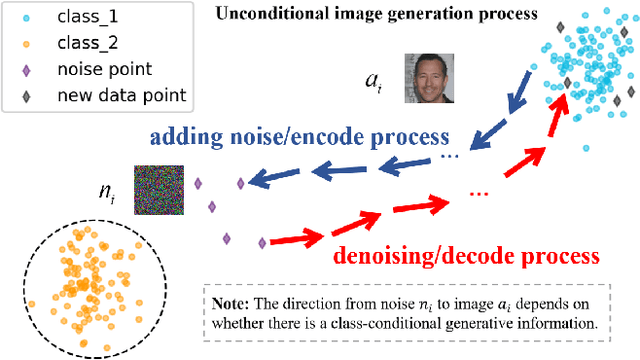
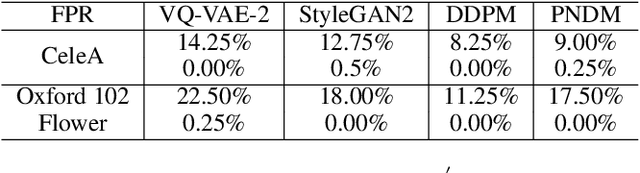
Deep learning techniques have implemented many unconditional image generation (UIG) models, such as GAN, Diffusion model, etc. The extremely realistic images (also known as AI-Generated Content, AIGC for short) produced by these models bring urgent needs for intellectual property protection such as data traceability and copyright certification. An attacker can steal the output images of the target model and use them as part of the training data to train a private surrogate UIG model. The implementation mechanisms of UIG models are diverse and complex, and there is no unified and effective protection and verification method at present. To address these issues, we propose a two-stage unified watermark verification mechanism with high-binding effects for such models. In the first stage, we use an encoder to invisibly write the watermark image into the output images of the original AIGC tool, and reversely extract the watermark image through the corresponding decoder. In the second stage, we design the decoder fine-tuning process, and the fine-tuned decoder can make correct judgments on whether the suspicious model steals the original AIGC tool data. Experiments demonstrate our method can complete the verification work with almost zero false positive rate under the condition of only using the model output images. Moreover, the proposed method can achieve data steal verification across different types of UIG models, which further increases the practicality of the method.