 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdeological Isolation in Online Social Networks: A Survey of Computational Definitions, Metrics, and Mitigation Strategies
Jan 12, 2026The proliferation of online social networks has significantly reshaped the way individuals access and engage with information. While these platforms offer unprecedented connectivity, they may foster environments where users are increasingly exposed to homogeneous content and like-minded interactions. Such dynamics are associated with selective exposure and the emergence of filter bubbles, echo chambers, tunnel vision, and polarization, which together can contribute to ideological isolation and raise concerns about information diversity and public discourse. This survey provides a comprehensive computational review of existing studies that define, analyze, quantify, and mitigate ideological isolation in online social networks. We examine the mechanisms underlying content personalization, user behavior patterns, and network structures that reinforce content-exposure concentration and narrowing dynamics. This paper also systematically reviews methodological approaches for detecting and measuring these isolation-related phenomena, covering network-, content-, and behavior-based metrics. We further organize computational mitigation strategies, including network-topological interventions and recommendation-level controls, and discuss their trade-offs and deployment considerations. By integrating definitions, metrics, and interventions across structural/topological, content-based, interactional, and cognitive isolation, this survey provides a unified computational framework. It serves as a reference for understanding and addressing the key challenges and opportunities in promoting information diversity and reducing ideological fragmentation in the digital age.
A Metric for MLLM Alignment in Large-scale Recommendation
Aug 07, 2025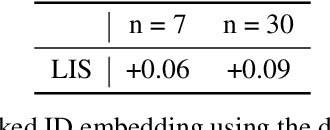
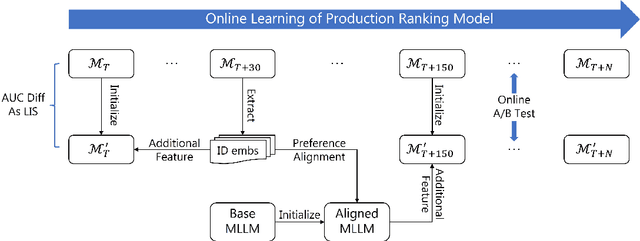


Multimodal recommendation has emerged as a critical technique in modern recommender systems, leveraging content representations from advanced multimodal large language models (MLLMs). To ensure these representations are well-adapted, alignment with the recommender system is essential. However, evaluating the alignment of MLLMs for recommendation presents significant challenges due to three key issues: (1) static benchmarks are inaccurate because of the dynamism in real-world applications, (2) evaluations with online system, while accurate, are prohibitively expensive at scale, and (3) conventional metrics fail to provide actionable insights when learned representations underperform. To address these challenges, we propose the Leakage Impact Score (LIS), a novel metric for multimodal recommendation. Rather than directly assessing MLLMs, LIS efficiently measures the upper bound of preference data. We also share practical insights on deploying MLLMs with LIS in real-world scenarios. Online A/B tests on both Content Feed and Display Ads of Xiaohongshu's Explore Feed production demonstrate the effectiveness of our proposed method, showing significant improvements in user spent time and advertiser value.
Efficient and Safe Planner for Automated Driving on Ramps Considering Unsatisfication
Apr 20, 2025Automated driving on ramps presents significant challenges due to the need to balance both safety and efficiency during lane changes. This paper proposes an integrated planner for automated vehicles (AVs) on ramps, utilizing an unsatisfactory level metric for efficiency and arrow-cluster-based sampling for safety. The planner identifies optimal times for the AV to change lanes, taking into account the vehicle's velocity as a key factor in efficiency. Additionally, the integrated planner employs arrow-cluster-based sampling to evaluate collision risks and select an optimal lane-changing curve. Extensive simulations were conducted in a ramp scenario to verify the planner's efficient and safe performance. The results demonstrate that the proposed planner can effectively select an appropriate lane-changing time point and a safe lane-changing curve for AVs, without incurring any collisions during the maneuver.
Towards Superior Quantization Accuracy: A Layer-sensitive Approach
Mar 09, 2025Large Vision and Language Models have exhibited remarkable human-like intelligence in tasks such as natural language comprehension, problem-solving, logical reasoning, and knowledge retrieval. However, training and serving these models require substantial computational resources, posing a significant barrier to their widespread application and further research. To mitigate this challenge, various model compression techniques have been developed to reduce computational requirements. Nevertheless, existing methods often employ uniform quantization configurations, failing to account for the varying difficulties across different layers in quantizing large neural network models. This paper tackles this issue by leveraging layer-sensitivity features, such as activation sensitivity and weight distribution Kurtosis, to identify layers that are challenging to quantize accurately and allocate additional memory budget. The proposed methods, named SensiBoost and KurtBoost, respectively, demonstrate notable improvement in quantization accuracy, achieving up to 9% lower perplexity with only a 2% increase in memory budget on LLama models compared to the baseline.
Harmonized Speculative Sampling
Aug 28, 2024

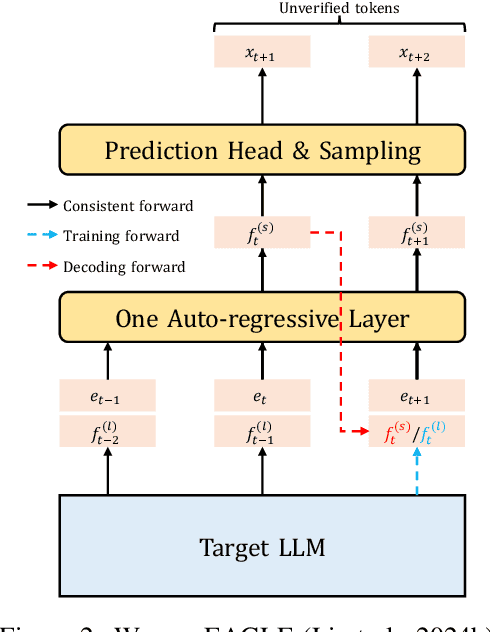

Speculative sampling has proven to be an effective solution to accelerate decoding from large language models, where the acceptance rate significantly determines the performance. Most previous works on improving the acceptance rate focus on aligned training and efficient decoding, implicitly paying less attention to the linkage of training and decoding. In this work, we first investigate the linkage of training and decoding for speculative sampling and then propose a solution named HArmonized Speculative Sampling (HASS). HASS improves the acceptance rate without extra inference overhead by harmonizing training and decoding on their objectives and contexts. Experiments on three LLaMA models demonstrate that HASS achieves 2.81x-3.65x wall-clock time speedup ratio averaging across three datasets, which is 8%-15% faster than EAGLE-2.
AspectMMKG: A Multi-modal Knowledge Graph with Aspect-aware Entities
Aug 09, 2023Multi-modal knowledge graphs (MMKGs) combine different modal data (e.g., text and image) for a comprehensive understanding of entities. Despite the recent progress of large-scale MMKGs, existing MMKGs neglect the multi-aspect nature of entities, limiting the ability to comprehend entities from various perspectives. In this paper, we construct AspectMMKG, the first MMKG with aspect-related images by matching images to different entity aspects. Specifically, we collect aspect-related images from a knowledge base, and further extract aspect-related sentences from the knowledge base as queries to retrieve a large number of aspect-related images via an online image search engine. Finally, AspectMMKG contains 2,380 entities, 18,139 entity aspects, and 645,383 aspect-related images. We demonstrate the usability of AspectMMKG in entity aspect linking (EAL) downstream task and show that previous EAL models achieve a new state-of-the-art performance with the help of AspectMMKG. To facilitate the research on aspect-related MMKG, we further propose an aspect-related image retrieval (AIR) model, that aims to correct and expand aspect-related images in AspectMMKG. We train an AIR model to learn the relationship between entity image and entity aspect-related images by incorporating entity image, aspect, and aspect image information. Experimental results indicate that the AIR model could retrieve suitable images for a given entity w.r.t different aspects.
ConaCLIP: Exploring Distillation of Fully-Connected Knowledge Interaction Graph for Lightweight Text-Image Retrieval
May 28, 2023Large-scale pre-trained text-image models with dual-encoder architectures (such as CLIP) are typically adopted for various vision-language applications, including text-image retrieval. However,these models are still less practical on edge devices or for real-time situations, due to the substantial indexing and inference time and the large consumption of computational resources. Although knowledge distillation techniques have been widely utilized for uni-modal model compression, how to expand them to the situation when the numbers of modalities and teachers/students are doubled has been rarely studied. In this paper, we conduct comprehensive experiments on this topic and propose the fully-Connected knowledge interaction graph (Cona) technique for cross-modal pre-training distillation. Based on our findings, the resulting ConaCLIP achieves SOTA performances on the widely-used Flickr30K and MSCOCO benchmarks under the lightweight setting. An industry application of our method on an e-commercial platform further demonstrates the significant effectiveness of ConaCLIP.
Multi-Modal Knowledge Graph Construction and Application: A Survey
Feb 11, 2022



Recent years have witnessed the resurgence of knowledge engineering which is featured by the fast growth of knowledge graphs. However, most of existing knowledge graphs are represented with pure symbols, which hurts the machine's capability to understand the real world. The multi-modalization of knowledge graphs is an inevitable key step towards the realization of human-level machine intelligence. The results of this endeavor are Multi-modal Knowledge Graphs (MMKGs). In this survey on MMKGs constructed by texts and images, we first give definitions of MMKGs, followed with the preliminaries on multi-modal tasks and techniques. We then systematically review the challenges, progresses and opportunities on the construction and application of MMKGs respectively, with detailed analyses of the strength and weakness of different solutions. We finalize this survey with open research problems relevant to MMKGs.