 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Research as Rubric for Reinforcement Learning
May 31, 2026Open-ended reasoning and long-form generation tasks lack reliable automatic verification signals for reward-based policy optimization. Rubrics offer a promising alternative, but existing approaches treat them as given artifacts -- either hand-crafted or prompt-generated -- and often miss the task-specific, knowledge-intensive dimensions that matter most, distorting the reward signal. Our key observation is that rubric construction is itself a research problem: identifying what makes a response correct or insightful requires discovering and synthesizing external knowledge. We propose Deep Research as Rubric (DR-rubric), a two-stage framework for constructing such rubrics. Stage I elicits domain facts, structural constraints, and failure modes through iterative multi-turn agentic search; Stage II distills this evidence into atomic, independently verifiable constraints for GRPO-based policy optimization. Because the model under training can serve as its own rubric generator, DR-rubric-8B supports bootstrap rubric generation without frontier-model assistance. We evaluate on 6 benchmarks spanning agentic research and expert reasoning. Experiments show that DR-Rubric achieves strong competitive performance with only 1K -- 3K training instances, where GPT-5-generated rubrics particularly benefit breadth coverage on agentic tasks, Gemini-generated rubrics yield the most balanced performance across agentic and expert reasoning tasks, and bootstrap rubrics exhibit a specialization-to-rebalancing evolution achieving the best overall performance at the third iteration. Results demonstrate that reframing rubric construction from static evaluation templates into an evidence-driven research process yields more scalable, fine-grained reward signals for open-ended tasks.
Harmonized Speculative Sampling
Aug 28, 2024

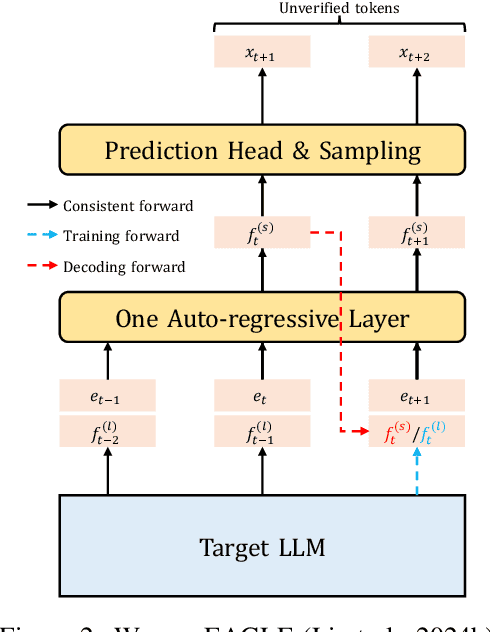

Speculative sampling has proven to be an effective solution to accelerate decoding from large language models, where the acceptance rate significantly determines the performance. Most previous works on improving the acceptance rate focus on aligned training and efficient decoding, implicitly paying less attention to the linkage of training and decoding. In this work, we first investigate the linkage of training and decoding for speculative sampling and then propose a solution named HArmonized Speculative Sampling (HASS). HASS improves the acceptance rate without extra inference overhead by harmonizing training and decoding on their objectives and contexts. Experiments on three LLaMA models demonstrate that HASS achieves 2.81x-3.65x wall-clock time speedup ratio averaging across three datasets, which is 8%-15% faster than EAGLE-2.
Learning from Long-Tailed Noisy Data with Sample Selection and Balanced Loss
Nov 20, 2022The success of deep learning depends on large-scale and well-curated training data, while data in real-world applications are commonly long-tailed and noisy. Many methods have been proposed to deal with long-tailed data or noisy data, while a few methods are developed to tackle long-tailed noisy data. To solve this, we propose a robust method for learning from long-tailed noisy data with sample selection and balanced loss. Specifically, we separate the noisy training data into clean labeled set and unlabeled set with sample selection, and train the deep neural network in a semi-supervised manner with a novel balanced loss based on model bias. Experiments on benchmarks demonstrate that our method outperforms existing state-of-the-art methods.