 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonized Speculative Sampling
Paper and Code


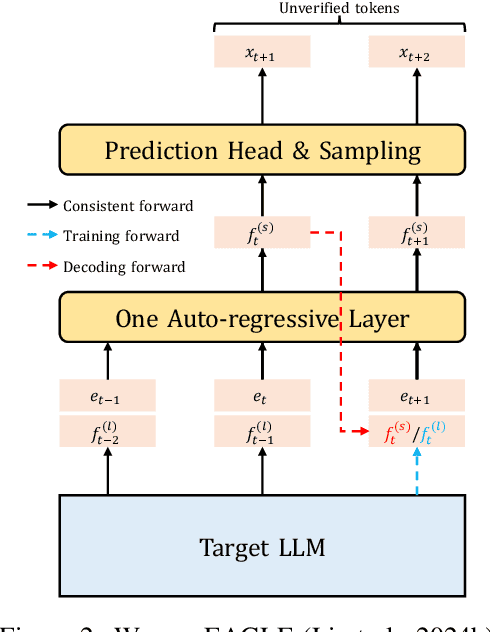

Speculative sampling has proven to be an effective solution to accelerate decoding from large language models, where the acceptance rate significantly determines the performance. Most previous works on improving the acceptance rate focus on aligned training and efficient decoding, implicitly paying less attention to the linkage of training and decoding. In this work, we first investigate the linkage of training and decoding for speculative sampling and then propose a solution named HArmonized Speculative Sampling (HASS). HASS improves the acceptance rate without extra inference overhead by harmonizing training and decoding on their objectives and contexts. Experiments on three LLaMA models demonstrate that HASS achieves 2.81x-3.65x wall-clock time speedup ratio averaging across three datasets, which is 8%-15% faster than EAGLE-2.