 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Long-Tailed Noisy Data with Sample Selection and Balanced Loss
Nov 20, 2022The success of deep learning depends on large-scale and well-curated training data, while data in real-world applications are commonly long-tailed and noisy. Many methods have been proposed to deal with long-tailed data or noisy data, while a few methods are developed to tackle long-tailed noisy data. To solve this, we propose a robust method for learning from long-tailed noisy data with sample selection and balanced loss. Specifically, we separate the noisy training data into clean labeled set and unlabeled set with sample selection, and train the deep neural network in a semi-supervised manner with a novel balanced loss based on model bias. Experiments on benchmarks demonstrate that our method outperforms existing state-of-the-art methods.
Towards Understanding Deep Learning from Noisy Labels with Small-Loss Criterion
Jun 17, 2021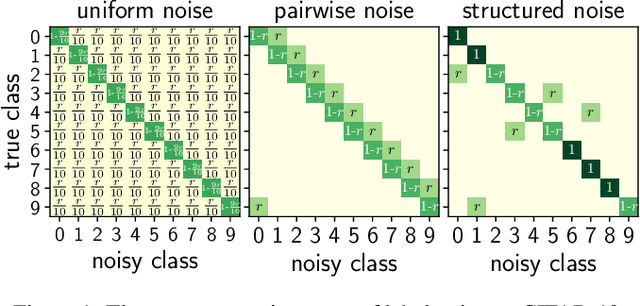

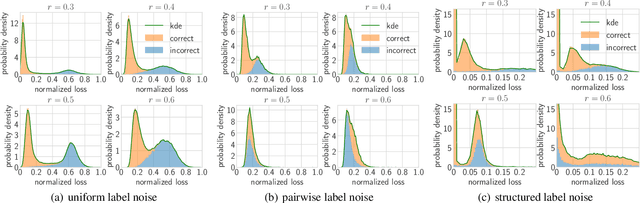
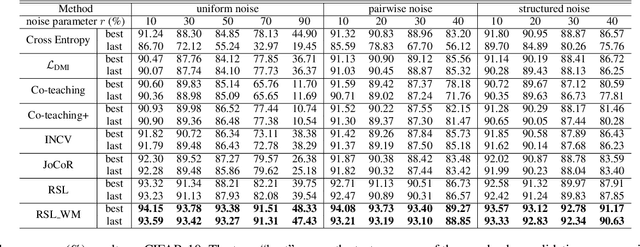
Deep neural networks need large amounts of labeled data to achieve good performance. In real-world applications, labels are usually collected from non-experts such as crowdsourcing to save cost and thus are noisy. In the past few years, deep learning methods for dealing with noisy labels have been developed, many of which are based on the small-loss criterion. However, there are few theoretical analyses to explain why these methods could learn well from noisy labels. In this paper, we theoretically explain why the widely-used small-loss criterion works. Based on the explanation, we reformalize the vanilla small-loss criterion to better tackle noisy labels. The experimental results verify our theoretical explanation and also demonstrate the effectiveness of the reformalization.