 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Matters: A Novel Real-Time Long- and Short-term User Interest Model for Click-Through Rate Prediction
Nov 09, 2025Click-Through Rate (CTR) prediction is a core task in online personalization platform. A key step for CTR prediction is to learn accurate user representation to capture their interests. Generally, the interest expressed by a user is time-variant, i.e., a user activates different interests at different time. However, most previous CTR prediction methods overlook the correlation between the activated interest and the occurrence time, resulting in what they actually learn is the mixture of the interests expressed by the user at all time, rather than the real-time interest at the certain prediction time. To capture the correlation between the activated interest and the occurrence time, in this paper we investigate users' interest evolution from the perspective of the whole time line and develop two regular patterns: periodic pattern and time-point pattern. Based on the two patterns, we propose a novel time-aware long- and short-term user interest modeling method to model users' dynamic interests at different time. Extensive experiments on public datasets as well as an industrial dataset verify the effectiveness of exploiting the two patterns and demonstrate the superiority of our proposed method compared with other state-of-the-art ones.
Towards Understanding Deep Learning from Noisy Labels with Small-Loss Criterion
Jun 17, 2021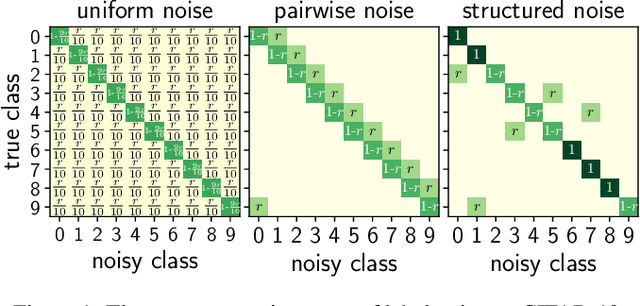

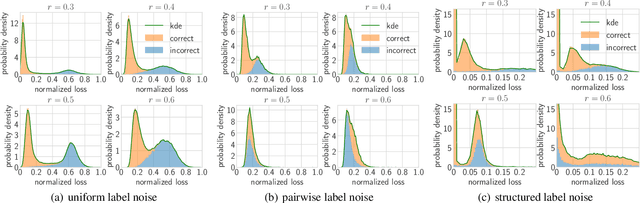
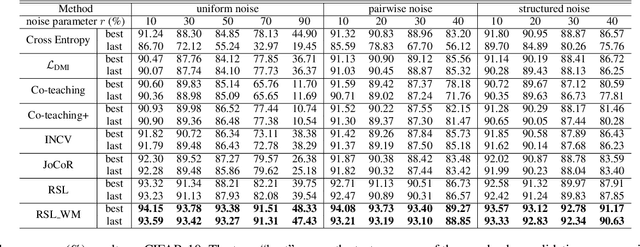
Deep neural networks need large amounts of labeled data to achieve good performance. In real-world applications, labels are usually collected from non-experts such as crowdsourcing to save cost and thus are noisy. In the past few years, deep learning methods for dealing with noisy labels have been developed, many of which are based on the small-loss criterion. However, there are few theoretical analyses to explain why these methods could learn well from noisy labels. In this paper, we theoretically explain why the widely-used small-loss criterion works. Based on the explanation, we reformalize the vanilla small-loss criterion to better tackle noisy labels. The experimental results verify our theoretical explanation and also demonstrate the effectiveness of the reformalization.
Towards Accurate and Robust Domain Adaptation under Noisy Environments
May 05, 2020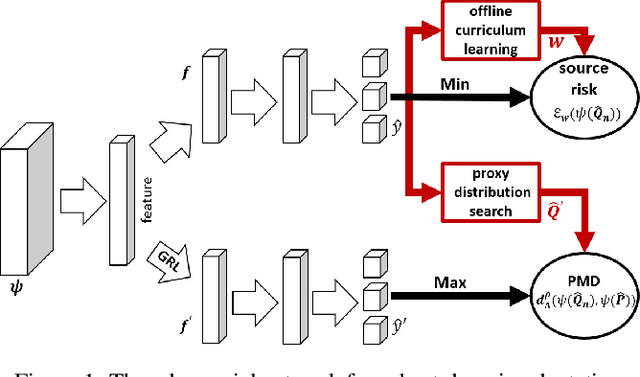

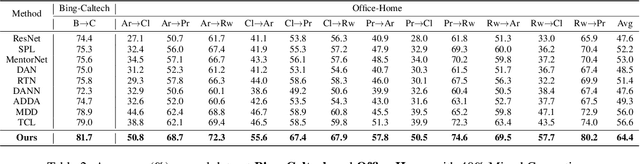
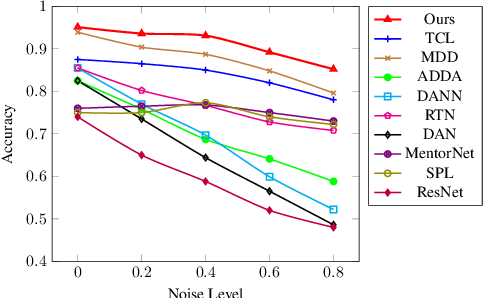
In non-stationary environments, learning machines usually confront the domain adaptation scenario where the data distribution does change over time. Previous domain adaptation works have achieved great success in theory and practice. However, they always lose robustness in noisy environments where the labels and features of examples from the source domain become corrupted. In this paper, we report our attempt towards achieving accurate noise-robust domain adaptation. We first give a theoretical analysis that reveals how harmful noises influence unsupervised domain adaptation. To eliminate the effect of label noise, we propose an offline curriculum learning for minimizing a newly-defined empirical source risk. To reduce the impact of feature noise, we propose a proxy distribution based margin discrepancy. We seamlessly transform our methods into an adversarial network that performs efficient joint optimization for them, successfully mitigating the negative influence from both data corruption and distribution shift. A series of empirical studies show that our algorithm remarkably outperforms state of the art, over 10% accuracy improvements in some domain adaptation tasks under noisy environments.