 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Deep Learning from Noisy Labels with Small-Loss Criterion
Paper and Code
Jun 17, 2021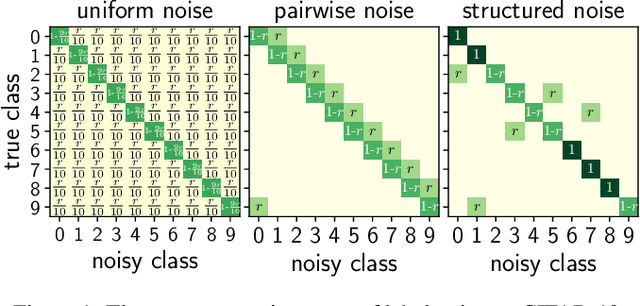

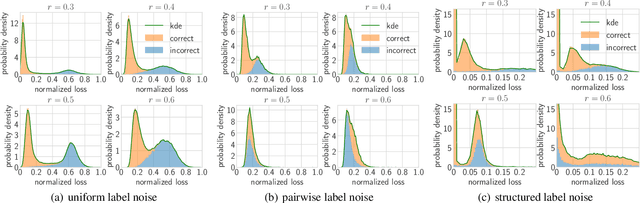
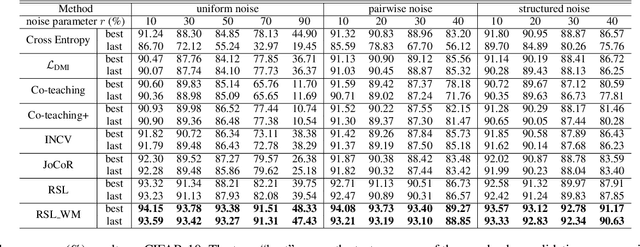
Deep neural networks need large amounts of labeled data to achieve good performance. In real-world applications, labels are usually collected from non-experts such as crowdsourcing to save cost and thus are noisy. In the past few years, deep learning methods for dealing with noisy labels have been developed, many of which are based on the small-loss criterion. However, there are few theoretical analyses to explain why these methods could learn well from noisy labels. In this paper, we theoretically explain why the widely-used small-loss criterion works. Based on the explanation, we reformalize the vanilla small-loss criterion to better tackle noisy labels. The experimental results verify our theoretical explanation and also demonstrate the effectiveness of the reformalization.