 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspectMMKG: A Multi-modal Knowledge Graph with Aspect-aware Entities
Aug 09, 2023Multi-modal knowledge graphs (MMKGs) combine different modal data (e.g., text and image) for a comprehensive understanding of entities. Despite the recent progress of large-scale MMKGs, existing MMKGs neglect the multi-aspect nature of entities, limiting the ability to comprehend entities from various perspectives. In this paper, we construct AspectMMKG, the first MMKG with aspect-related images by matching images to different entity aspects. Specifically, we collect aspect-related images from a knowledge base, and further extract aspect-related sentences from the knowledge base as queries to retrieve a large number of aspect-related images via an online image search engine. Finally, AspectMMKG contains 2,380 entities, 18,139 entity aspects, and 645,383 aspect-related images. We demonstrate the usability of AspectMMKG in entity aspect linking (EAL) downstream task and show that previous EAL models achieve a new state-of-the-art performance with the help of AspectMMKG. To facilitate the research on aspect-related MMKG, we further propose an aspect-related image retrieval (AIR) model, that aims to correct and expand aspect-related images in AspectMMKG. We train an AIR model to learn the relationship between entity image and entity aspect-related images by incorporating entity image, aspect, and aspect image information. Experimental results indicate that the AIR model could retrieve suitable images for a given entity w.r.t different aspects.
DuDoNet: Dual Domain Network for CT Metal Artifact Reduction
Jun 29, 2019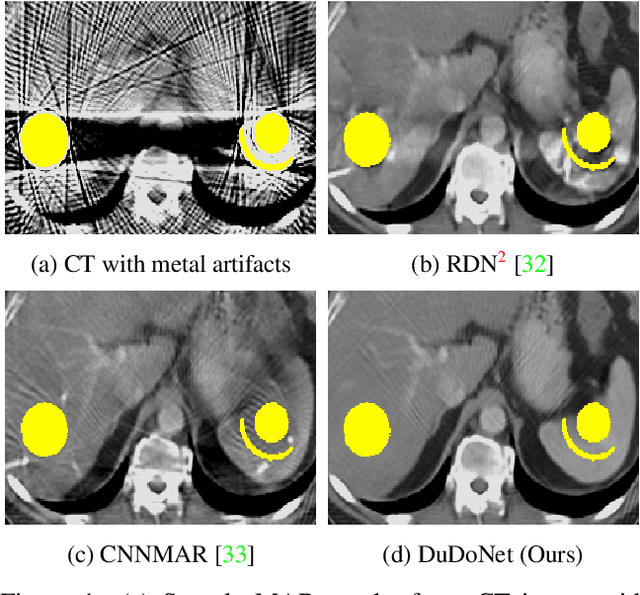


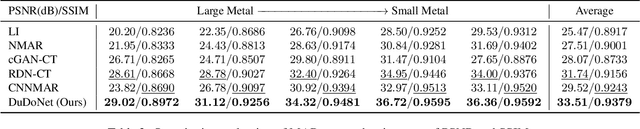
Computed tomography (CT) is an imaging modality widely used for medical diagnosis and treatment. CT images are often corrupted by undesirable artifacts when metallic implants are carried by patients, which creates the problem of metal artifact reduction (MAR). Existing methods for reducing the artifacts due to metallic implants are inadequate for two main reasons. First, metal artifacts are structured and non-local so that simple image domain enhancement approaches would not suffice. Second, the MAR approaches which attempt to reduce metal artifacts in the X-ray projection (sinogram) domain inevitably lead to severe secondary artifact due to sinogram inconsistency. To overcome these difficulties, we propose an end-to-end trainable Dual Domain Network (DuDoNet) to simultaneously restore sinogram consistency and enhance CT images. The linkage between the sigogram and image domains is a novel Radon inversion layer that allows the gradients to back-propagate from the image domain to the sinogram domain during training. Extensive experiments show that our method achieves significant improvements over other single domain MAR approaches. To the best of our knowledge, it is the first end-to-end dual-domain network for MAR.
Multiview 2D/3D Rigid Registration via a Point-Of-Interest Network for Tracking and Triangulation
Apr 08, 2019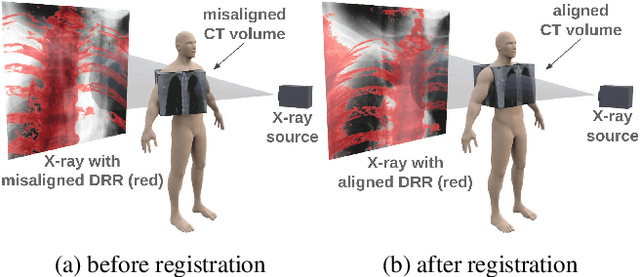

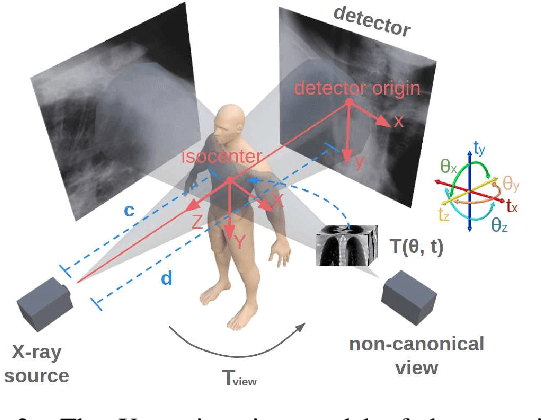
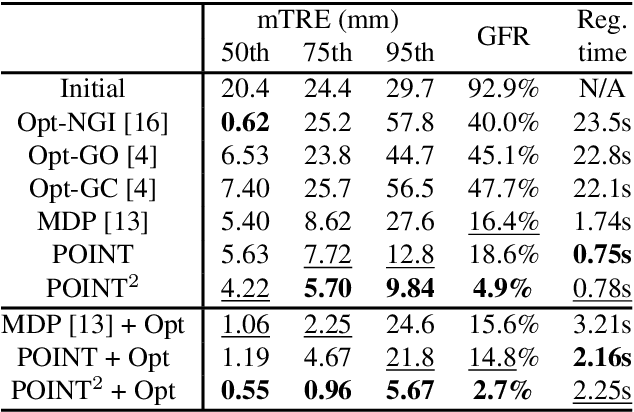
We propose to tackle the problem of multiview 2D/3D rigid registration for intervention via a Point-Of-Interest Network for Tracking and Triangulation (POINT^2). POINT^2 learns to establish 2D point-to-point correspondences between the pre- and intra-intervention images by tracking a set of random POIs. The 3D pose of the pre-intervention volume is then estimated through a triangulation layer. In POINT^2, the unified framework of the POI tracker and the triangulation layer enables learning informative 2D features and estimating 3D pose jointly. In contrast to existing approaches, POINT^2 only requires a single forward-pass to achieve a reliable 2D/3D registration. As the POI tracker is shift-invariant, POINT^2 is more robust to the initial pose of the 3D pre-intervention image. Extensive experiments on a large-scale clinical cone-beam CT (CBCT) dataset show that the proposed POINT^2 method outperforms the existing learning-based method in terms of accuracy, robustness and running time. Furthermore, when used as an initial pose estimator, our method also improves the robustness and speed of the state-of-the-art optimization-based approaches by ten folds.