 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed3D-R1: Incentivizing Clinical Reasoning in 3D Medical Vision-Language Models for Abnormality Diagnosis
Feb 01, 2026Developing 3D vision-language models with robust clinical reasoning remains a challenge due to the inherent complexity of volumetric medical imaging, the tendency of models to overfit superficial report patterns, and the lack of interpretability-aware reward designs. In this paper, we propose Med3D-R1, a reinforcement learning framework with a two-stage training process: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). During SFT stage, we introduce a residual alignment mechanism to bridge the gap between high-dimensional 3D features and textual embeddings, and an abnormality re-weighting strategy to emphasize clinically informative tokens and reduce structural bias in reports. In RL stage, we redesign the consistency reward to explicitly promote coherent, step-by-step diagnostic reasoning. We evaluate our method on medical multiple-choice visual question answering using two 3D diagnostic benchmarks, CT-RATE and RAD-ChestCT, where our model attains state-of-the-art accuracies of 41.92\% on CT-RATE and 44.99\% on RAD-ChestCT. These results indicate improved abnormality diagnosis and clinical reasoning and outperform prior methods on both benchmarks. Overall, our approach holds promise for enhancing real-world diagnostic workflows by enabling more reliable and transparent 3D medical vision-language systems.
UCAD: Uncertainty-guided Contour-aware Displacement for semi-supervised medical image segmentation
Jan 24, 2026Existing displacement strategies in semi-supervised segmentation only operate on rectangular regions, ignoring anatomical structures and resulting in boundary distortions and semantic inconsistency. To address these issues, we propose UCAD, an Uncertainty-Guided Contour-Aware Displacement framework for semi-supervised medical image segmentation that preserves contour-aware semantics while enhancing consistency learning. Our UCAD leverages superpixels to generate anatomically coherent regions aligned with anatomy boundaries, and an uncertainty-guided selection mechanism to selectively displace challenging regions for better consistency learning. We further propose a dynamic uncertainty-weighted consistency loss, which adaptively stabilizes training and effectively regularizes the model on unlabeled regions. Extensive experiments demonstrate that UCAD consistently outperforms state-of-the-art semi-supervised segmentation methods, achieving superior segmentation accuracy under limited annotation. The code is available at:https://github.com/dcb937/UCAD.
Fusion of Heterogeneous Pathology Foundation Models for Whole Slide Image Analysis
Oct 31, 2025Whole slide image (WSI) analysis has emerged as an increasingly essential technique in computational pathology. Recent advances in the pathological foundation models (FMs) have demonstrated significant advantages in deriving meaningful patch-level or slide-level feature representations from WSIs. However, current pathological FMs have exhibited substantial heterogeneity caused by diverse private training datasets and different network architectures. This heterogeneity introduces performance variability when we utilize the extracted features from different FMs in the downstream tasks. To fully explore the advantage of multiple FMs effectively, in this work, we propose a novel framework for the fusion of heterogeneous pathological FMs, called FuseCPath, yielding a model with a superior ensemble performance. The main contributions of our framework can be summarized as follows: (i) To guarantee the representativeness of the training patches, we propose a multi-view clustering-based method to filter out the discriminative patches via multiple FMs' embeddings. (ii) To effectively fuse the heterogeneous patch-level FMs, we devise a cluster-level re-embedding strategy to online capture patch-level local features. (iii) To effectively fuse the heterogeneous slide-level FMs, we devise a collaborative distillation strategy to explore the connections between slide-level FMs. Extensive experiments conducted on lung cancer, bladder cancer, and colorectal cancer datasets from The Cancer Genome Atlas (TCGA) have demonstrated that the proposed FuseCPath achieves state-of-the-art performance across multiple tasks on these public datasets.
U-Bench: A Comprehensive Understanding of U-Net through 100-Variant Benchmarking
Oct 08, 2025


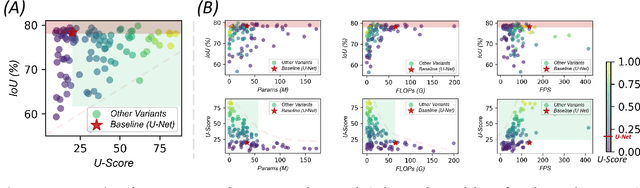
Over the past decade, U-Net has been the dominant architecture in medical image segmentation, leading to the development of thousands of U-shaped variants. Despite its widespread adoption, there is still no comprehensive benchmark to systematically evaluate their performance and utility, largely because of insufficient statistical validation and limited consideration of efficiency and generalization across diverse datasets. To bridge this gap, we present U-Bench, the first large-scale, statistically rigorous benchmark that evaluates 100 U-Net variants across 28 datasets and 10 imaging modalities. Our contributions are threefold: (1) Comprehensive Evaluation: U-Bench evaluates models along three key dimensions: statistical robustness, zero-shot generalization, and computational efficiency. We introduce a novel metric, U-Score, which jointly captures the performance-efficiency trade-off, offering a deployment-oriented perspective on model progress. (2) Systematic Analysis and Model Selection Guidance: We summarize key findings from the large-scale evaluation and systematically analyze the impact of dataset characteristics and architectural paradigms on model performance. Based on these insights, we propose a model advisor agent to guide researchers in selecting the most suitable models for specific datasets and tasks. (3) Public Availability: We provide all code, models, protocols, and weights, enabling the community to reproduce our results and extend the benchmark with future methods. In summary, U-Bench not only exposes gaps in previous evaluations but also establishes a foundation for fair, reproducible, and practically relevant benchmarking in the next decade of U-Net-based segmentation models. The project can be accessed at: https://fenghetan9.github.io/ubench. Code is available at: https://github.com/FengheTan9/U-Bench.
More performant and scalable: Rethinking contrastive vision-language pre-training of radiology in the LLM era
Sep 16, 2025The emergence of Large Language Models (LLMs) presents unprecedented opportunities to revolutionize medical contrastive vision-language pre-training. In this paper, we show how LLMs can facilitate large-scale supervised pre-training, thereby advancing vision-language alignment. We begin by demonstrate that modern LLMs can automatically extract diagnostic labels from radiology reports with remarkable precision (>96\% AUC in our experiments) without complex prompt engineering, enabling the creation of large-scale "silver-standard" datasets at a minimal cost (~\$3 for 50k CT image-report pairs). Further, we find that vision encoder trained on this "silver-standard" dataset achieves performance comparable to those trained on labels extracted by specialized BERT-based models, thereby democratizing the access to large-scale supervised pre-training. Building on this foundation, we proceed to reveal that supervised pre-training fundamentally improves contrastive vision-language alignment. Our approach achieves state-of-the-art performance using only a 3D ResNet-18 with vanilla CLIP training, including 83.8\% AUC for zero-shot diagnosis on CT-RATE, 77.3\% AUC on RAD-ChestCT, and substantial improvements in cross-modal retrieval (MAP@50=53.7\% for image-image, Recall@100=52.2\% for report-image). These results demonstrate the potential of utilizing LLMs to facilitate {\bf more performant and scalable} medical AI systems. Our code is avaiable at https://github.com/SadVoxel/More-performant-and-scalable.
SimCroP: Radiograph Representation Learning with Similarity-driven Cross-granularity Pre-training
Sep 10, 2025Medical vision-language pre-training shows great potential in learning representative features from massive paired radiographs and reports. However, in computed tomography (CT) scans, the distribution of lesions which contain intricate structures is characterized by spatial sparsity. Besides, the complex and implicit relationships between different pathological descriptions in each sentence of the report and their corresponding sub-regions in radiographs pose additional challenges. In this paper, we propose a Similarity-Driven Cross-Granularity Pre-training (SimCroP) framework on chest CTs, which combines similarity-driven alignment and cross-granularity fusion to improve radiograph interpretation. We first leverage multi-modal masked modeling to optimize the encoder for understanding precise low-level semantics from radiographs. Then, similarity-driven alignment is designed to pre-train the encoder to adaptively select and align the correct patches corresponding to each sentence in reports. The cross-granularity fusion module integrates multimodal information across instance level and word-patch level, which helps the model better capture key pathology structures in sparse radiographs, resulting in improved performance for multi-scale downstream tasks. SimCroP is pre-trained on a large-scale paired CT-reports dataset and validated on image classification and segmentation tasks across five public datasets. Experimental results demonstrate that SimCroP outperforms both cutting-edge medical self-supervised learning methods and medical vision-language pre-training methods. Codes and models are available at https://github.com/ToniChopp/SimCroP.
Knowledge Matters: Radiology Report Generation with General and Specific Knowledge
Dec 30, 2021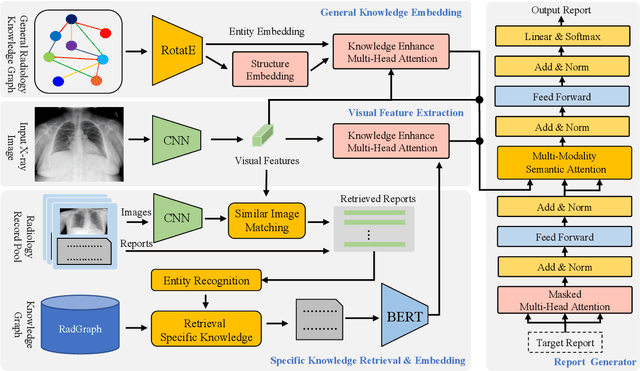
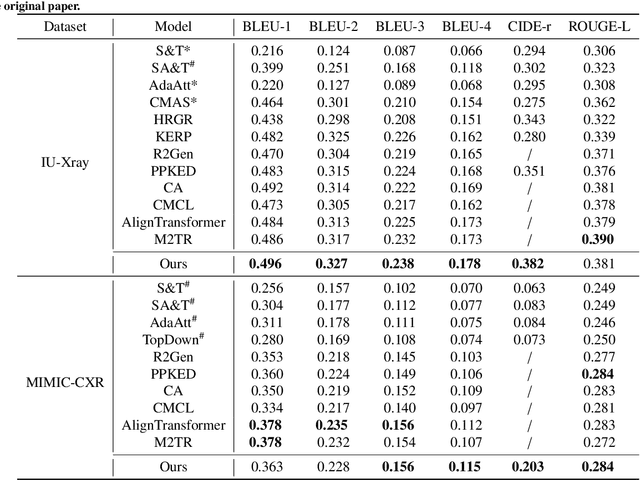
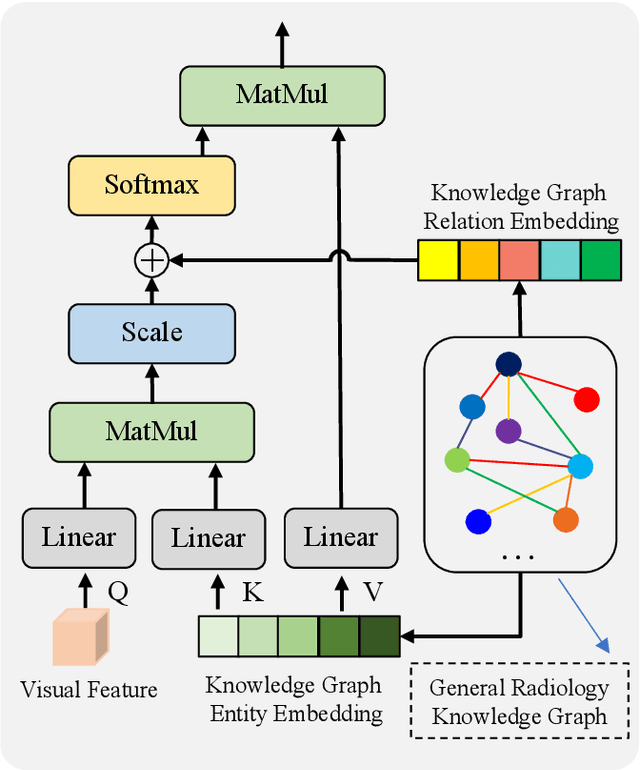
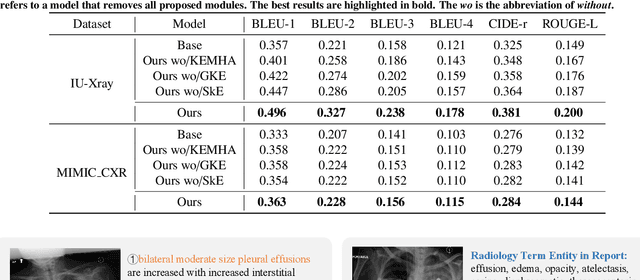
Automatic radiology report generation is critical in clinics which can relieve experienced radiologists from the heavy workload and remind inexperienced radiologists of misdiagnosis or missed diagnose. Existing approaches mainly formulate radiology report generation as an image captioning task and adopt the encoder-decoder framework. However, in the medical domain, such pure data-driven approaches suffer from the following problems: 1) visual and textual bias problem; 2) lack of expert knowledge. In this paper, we propose a knowledge-enhanced radiology report generation approach introduces two types of medical knowledge: 1) General knowledge, which is input independent and provides the broad knowledge for report generation; 2) Specific knowledge, which is input dependent and provides the fine-grained knowledge for report generation. To fully utilize both the general and specific knowledge, we also propose a knowledge-enhanced multi-head attention mechanism. By merging the visual features of the radiology image with general knowledge and specific knowledge, the proposed model can improve the quality of generated reports. Experimental results on two publicly available datasets IU-Xray and MIMIC-CXR show that the proposed knowledge enhanced approach outperforms state-of-the-art image captioning based methods. Ablation studies also demonstrate that both general and specific knowledge can help to improve the performance of radiology report generation.
XraySyn: Realistic View Synthesis From a Single Radiograph Through CT Priors
Dec 04, 2020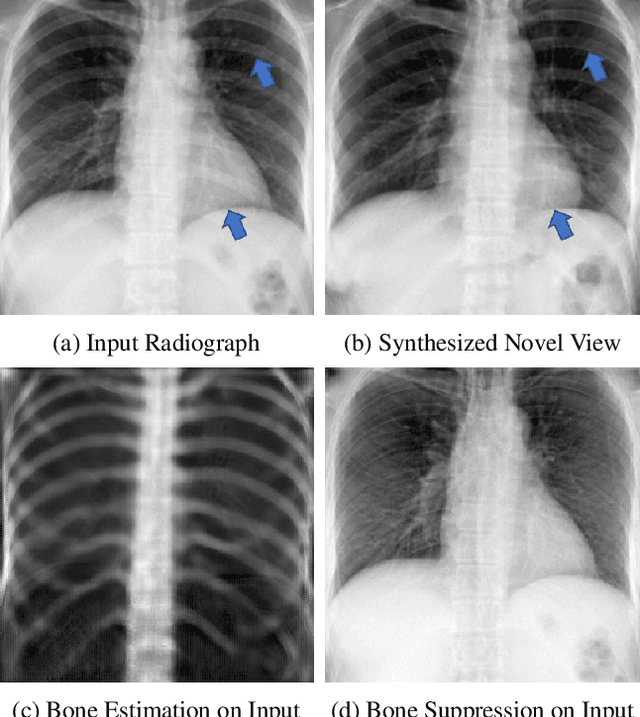



A radiograph visualizes the internal anatomy of a patient through the use of X-ray, which projects 3D information onto a 2D plane. Hence, radiograph analysis naturally requires physicians to relate the prior about 3D human anatomy to 2D radiographs. Synthesizing novel radiographic views in a small range can assist physicians in interpreting anatomy more reliably; however, radiograph view synthesis is heavily ill-posed, lacking in paired data, and lacking in differentiable operations to leverage learning-based approaches. To address these problems, we use Computed Tomography (CT) for radiograph simulation and design a differentiable projection algorithm, which enables us to achieve geometrically consistent transformations between the radiography and CT domains. Our method, XraySyn, can synthesize novel views on real radiographs through a combination of realistic simulation and finetuning on real radiographs. To the best of our knowledge, this is the first work on radiograph view synthesis. We show that by gaining an understanding of radiography in 3D space, our method can be applied to radiograph bone extraction and suppression without groundtruth bone labels.
DuDoNet: Dual Domain Network for CT Metal Artifact Reduction
Jun 29, 2019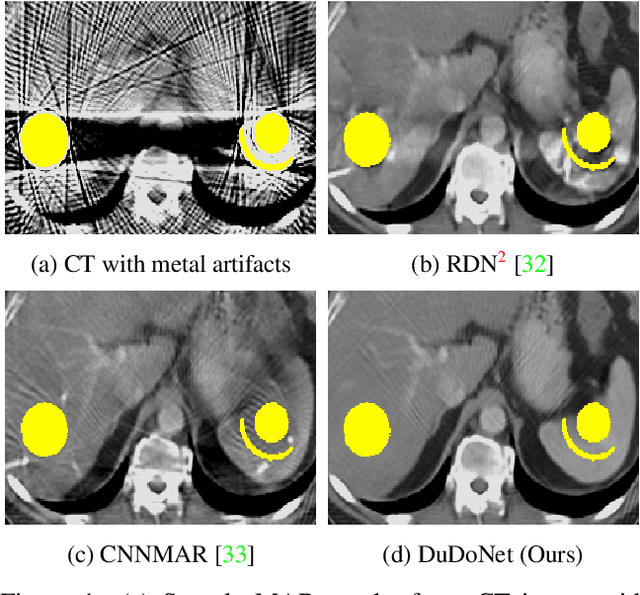


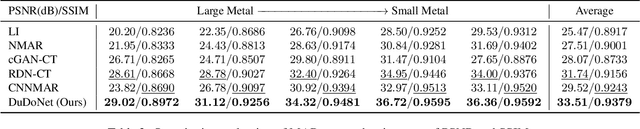
Computed tomography (CT) is an imaging modality widely used for medical diagnosis and treatment. CT images are often corrupted by undesirable artifacts when metallic implants are carried by patients, which creates the problem of metal artifact reduction (MAR). Existing methods for reducing the artifacts due to metallic implants are inadequate for two main reasons. First, metal artifacts are structured and non-local so that simple image domain enhancement approaches would not suffice. Second, the MAR approaches which attempt to reduce metal artifacts in the X-ray projection (sinogram) domain inevitably lead to severe secondary artifact due to sinogram inconsistency. To overcome these difficulties, we propose an end-to-end trainable Dual Domain Network (DuDoNet) to simultaneously restore sinogram consistency and enhance CT images. The linkage between the sigogram and image domains is a novel Radon inversion layer that allows the gradients to back-propagate from the image domain to the sinogram domain during training. Extensive experiments show that our method achieves significant improvements over other single domain MAR approaches. To the best of our knowledge, it is the first end-to-end dual-domain network for MAR.
More Knowledge is Better: Cross-Modality Volume Completion and 3D+2D Segmentation for Intracardiac Echocardiography Contouring
Dec 09, 2018



Using catheter ablation to treat atrial fibrillation increasingly relies on intracardiac echocardiography (ICE) for an anatomical delineation of the left atrium and the pulmonary veins that enter the atrium. However, it is a challenge to build an automatic contouring algorithm because ICE is noisy and provides only a limited 2D view of the 3D anatomy. This work provides the first automatic solution to segment the left atrium and the pulmonary veins from ICE. In this solution, we demonstrate the benefit of building a cross-modality framework that can leverage a database of diagnostic images to supplement the less available interventional images. To this end, we develop a novel deep neural network approach that uses the (i) 3D geometrical information provided by a position sensor embedded in the ICE catheter and the (ii) 3D image appearance information from a set of computed tomography cardiac volumes. We evaluate the proposed approach over 11,000 ICE images collected from 150 clinical patients. Experimental results show that our model is significantly better than a direct 2D image-to-image deep neural network segmentation, especially for less-observed structures.