 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolitical Posters Identification with Appearance-Text Fusion
Dec 19, 2020
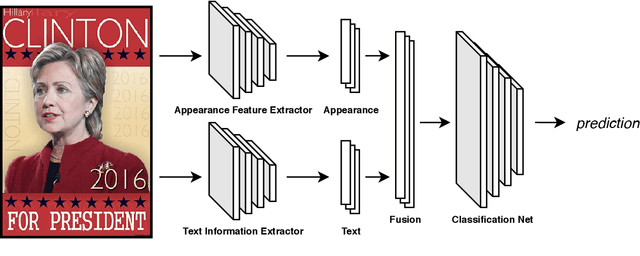
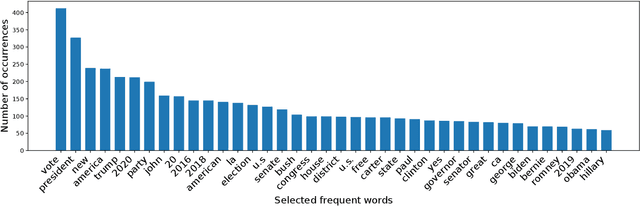

In this paper, we propose a method that efficiently utilizes appearance features and text vectors to accurately classify political posters from other similar political images. The majority of this work focuses on political posters that are designed to serve as a promotion of a certain political event, and the automated identification of which can lead to the generation of detailed statistics and meets the judgment needs in a variety of areas. Starting with a comprehensive keyword list for politicians and political events, we curate for the first time an effective and practical political poster dataset containing 13K human-labeled political images, including 3K political posters that explicitly support a movement or a campaign. Second, we make a thorough case study for this dataset and analyze common patterns and outliers of political posters. Finally, we propose a model that combines the power of both appearance and text information to classify political posters with significantly high accuracy.
Nationality Classification Using Name Embeddings
Aug 25, 2017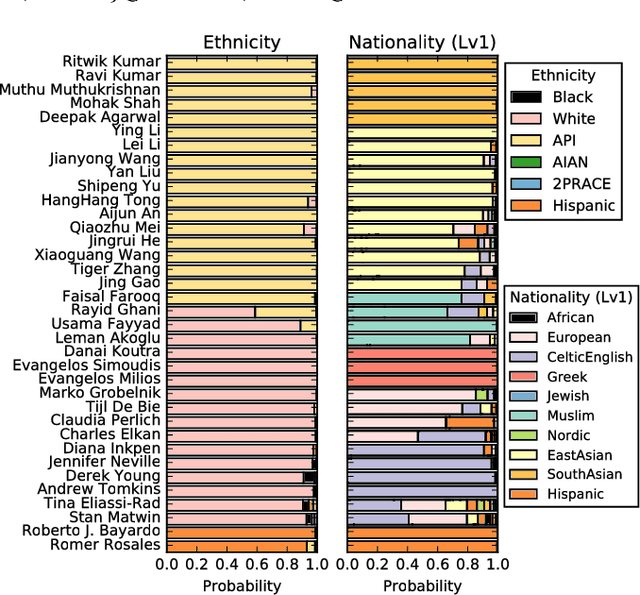


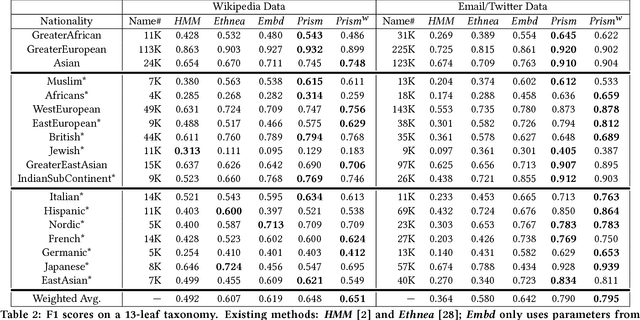
Nationality identification unlocks important demographic information, with many applications in biomedical and sociological research. Existing name-based nationality classifiers use name substrings as features and are trained on small, unrepresentative sets of labeled names, typically extracted from Wikipedia. As a result, these methods achieve limited performance and cannot support fine-grained classification. We exploit the phenomena of homophily in communication patterns to learn name embeddings, a new representation that encodes gender, ethnicity, and nationality which is readily applicable to building classifiers and other systems. Through our analysis of 57M contact lists from a major Internet company, we are able to design a fine-grained nationality classifier covering 39 groups representing over 90% of the world population. In an evaluation against other published systems over 13 common classes, our F1 score (0.795) is substantial better than our closest competitor Ethnea (0.580). To the best of our knowledge, this is the most accurate, fine-grained nationality classifier available. As a social media application, we apply our classifiers to the followers of major Twitter celebrities over six different domains. We demonstrate stark differences in the ethnicities of the followers of Trump and Obama, and in the sports and entertainments favored by different groups. Finally, we identify an anomalous political figure whose presumably inflated following appears largely incapable of reading the language he posts in.
Coarse-to-Fine Classification via Parametric and Nonparametric Models for Computer-Aided Diagnosis
May 16, 2014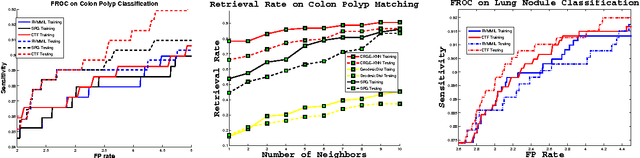
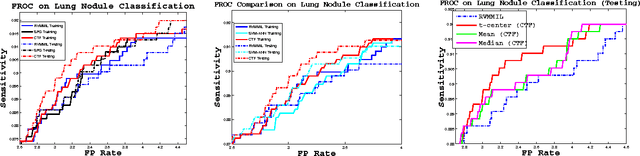
Classification is one of the core problems in Computer-Aided Diagnosis (CAD), targeting for early cancer detection using 3D medical imaging interpretation. High detection sensitivity with desirably low false positive (FP) rate is critical for a CAD system to be accepted as a valuable or even indispensable tool in radiologists' workflow. Given various spurious imagery noises which cause observation uncertainties, this remains a very challenging task. In this paper, we propose a novel, two-tiered coarse-to-fine (CTF) classification cascade framework to tackle this problem. We first obtain classification-critical data samples (e.g., samples on the decision boundary) extracted from the holistic data distributions using a robust parametric model (e.g., \cite{Raykar08}); then we build a graph-embedding based nonparametric classifier on sampled data, which can more accurately preserve or formulate the complex classification boundary. These two steps can also be considered as effective "sample pruning" and "feature pursuing + $k$NN/template matching", respectively. Our approach is validated comprehensively in colorectal polyp detection and lung nodule detection CAD systems, as the top two deadly cancers, using hospital scale, multi-site clinical datasets. The results show that our method achieves overall better classification/detection performance than existing state-of-the-art algorithms using single-layer classifiers, such as the support vector machine variants \cite{Wang08}, boosting \cite{Slabaugh10}, logistic regression \cite{Ravesteijn10}, relevance vector machine \cite{Raykar08}, $k$-nearest neighbor \cite{Murphy09} or spectral projections on graph \cite{Cai08}.
Semantic Context Forests for Learning-Based Knee Cartilage Segmentation in 3D MR Images
Apr 22, 2014
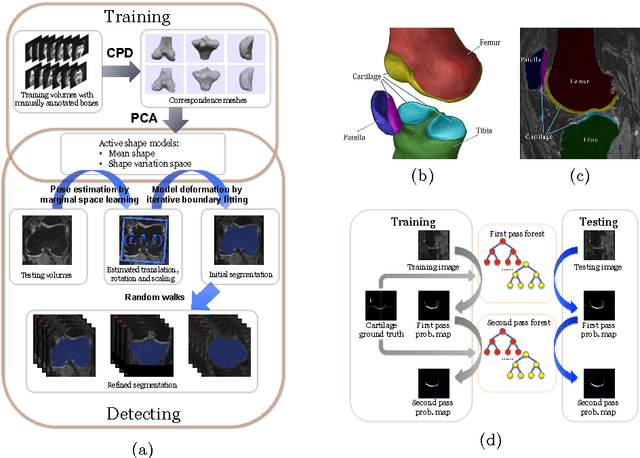
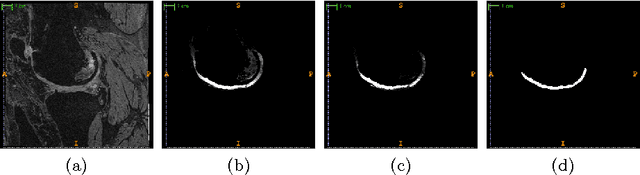
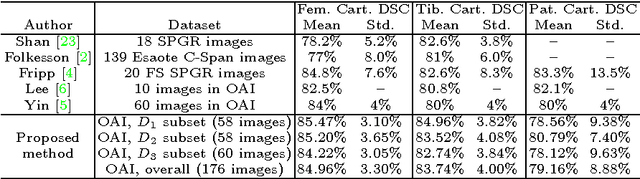
The automatic segmentation of human knee cartilage from 3D MR images is a useful yet challenging task due to the thin sheet structure of the cartilage with diffuse boundaries and inhomogeneous intensities. In this paper, we present an iterative multi-class learning method to segment the femoral, tibial and patellar cartilage simultaneously, which effectively exploits the spatial contextual constraints between bone and cartilage, and also between different cartilages. First, based on the fact that the cartilage grows in only certain area of the corresponding bone surface, we extract the distance features of not only to the surface of the bone, but more informatively, to the densely registered anatomical landmarks on the bone surface. Second, we introduce a set of iterative discriminative classifiers that at each iteration, probability comparison features are constructed from the class confidence maps derived by previously learned classifiers. These features automatically embed the semantic context information between different cartilages of interest. Validated on a total of 176 volumes from the Osteoarthritis Initiative (OAI) dataset, the proposed approach demonstrates high robustness and accuracy of segmentation in comparison with existing state-of-the-art MR cartilage segmentation methods.