 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-Beta: A Proactive Probabilistic Approach to Text Moderation
Sep 18, 2021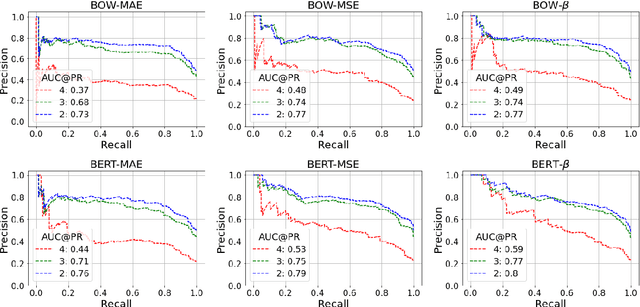
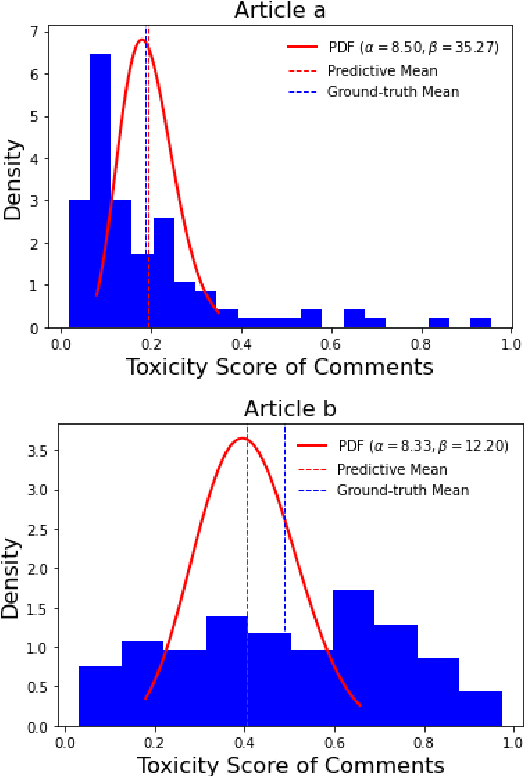
Text moderation for user generated content, which helps to promote healthy interaction among users, has been widely studied and many machine learning models have been proposed. In this work, we explore an alternative perspective by augmenting reactive reviews with proactive forecasting. Specifically, we propose a new concept {\it text toxicity propensity} to characterize the extent to which a text tends to attract toxic comments. Beta regression is then introduced to do the probabilistic modeling, which is demonstrated to function well in comprehensive experiments. We also propose an explanation method to communicate the model decision clearly. Both propensity scoring and interpretation benefit text moderation in a novel manner. Finally, the proposed scaling mechanism for the linear model offers useful insights beyond this work.
TSI: an Ad Text Strength Indicator using Text-to-CTR and Semantic-Ad-Similarity
Aug 18, 2021
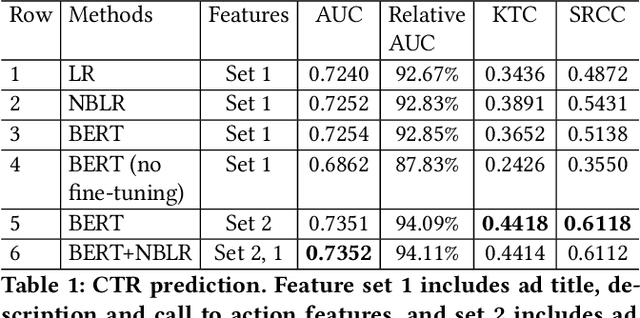
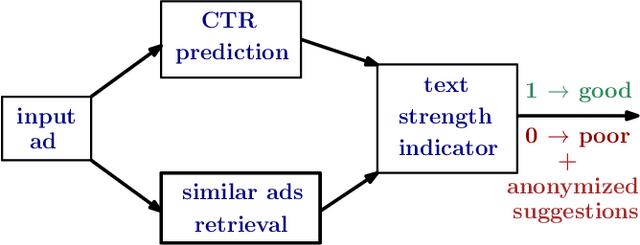

Coming up with effective ad text is a time consuming process, and particularly challenging for small businesses with limited advertising experience. When an inexperienced advertiser onboards with a poorly written ad text, the ad platform has the opportunity to detect low performing ad text, and provide improvement suggestions. To realize this opportunity, we propose an ad text strength indicator (TSI) which: (i) predicts the click-through-rate (CTR) for an input ad text, (ii) fetches similar existing ads to create a neighborhood around the input ad, (iii) and compares the predicted CTRs in the neighborhood to declare whether the input ad is strong or weak. In addition, as suggestions for ad text improvement, TSI shows anonymized versions of superior ads (higher predicted CTR) in the neighborhood. For (i), we propose a BERT based text-to-CTR model trained on impressions and clicks associated with an ad text. For (ii), we propose a sentence-BERT based semantic-ad-similarity model trained using weak labels from ad campaign setup data. Offline experiments demonstrate that our BERT based text-to-CTR model achieves a significant lift in CTR prediction AUC for cold start (new) advertisers compared to bag-of-words based baselines. In addition, our semantic-textual-similarity model for similar ads retrieval achieves a precision@1 of 0.93 (for retrieving ads from the same product category); this is significantly higher compared to unsupervised TF-IDF, word2vec, and sentence-BERT baselines. Finally, we share promising online results from advertisers in the Yahoo (Verizon Media) ad platform where a variant of TSI was implemented with sub-second end-to-end latency.
What's in a Name? -- Gender Classification of Names with Character Based Machine Learning Models
Feb 07, 2021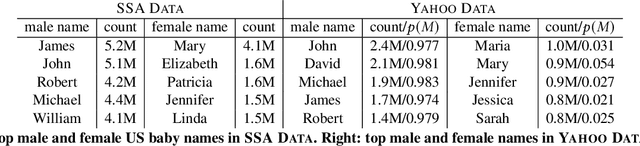
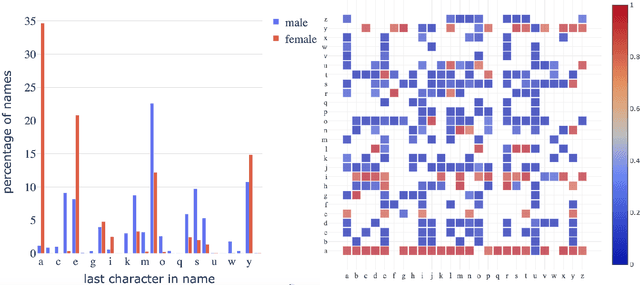
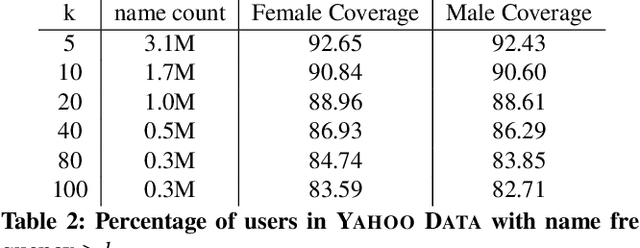
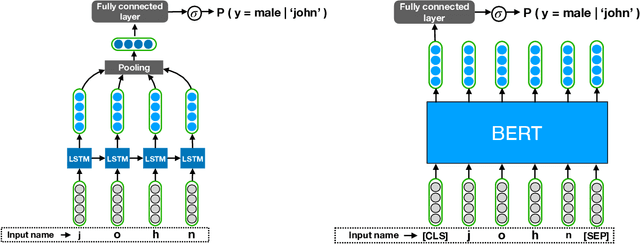
Gender information is no longer a mandatory input when registering for an account at many leading Internet companies. However, prediction of demographic information such as gender and age remains an important task, especially in intervention of unintentional gender/age bias in recommender systems. Therefore it is necessary to infer the gender of those users who did not to provide this information during registration. We consider the problem of predicting the gender of registered users based on their declared name. By analyzing the first names of 100M+ users, we found that genders can be very effectively classified using the composition of the name strings. We propose a number of character based machine learning models, and demonstrate that our models are able to infer the gender of users with much higher accuracy than baseline models. Moreover, we show that using the last names in addition to the first names improves classification performance further.
Political Posters Identification with Appearance-Text Fusion
Dec 19, 2020
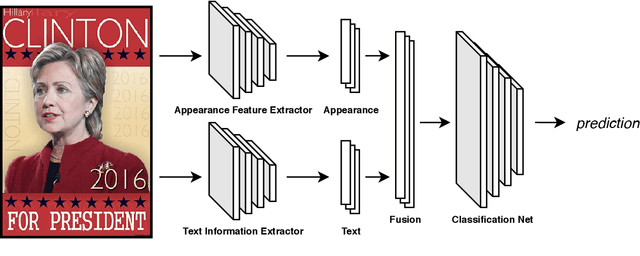

In this paper, we propose a method that efficiently utilizes appearance features and text vectors to accurately classify political posters from other similar political images. The majority of this work focuses on political posters that are designed to serve as a promotion of a certain political event, and the automated identification of which can lead to the generation of detailed statistics and meets the judgment needs in a variety of areas. Starting with a comprehensive keyword list for politicians and political events, we curate for the first time an effective and practical political poster dataset containing 13K human-labeled political images, including 3K political posters that explicitly support a movement or a campaign. Second, we make a thorough case study for this dataset and analyze common patterns and outliers of political posters. Finally, we propose a model that combines the power of both appearance and text information to classify political posters with significantly high accuracy.
HABERTOR: An Efficient and Effective Deep Hatespeech Detector
Oct 17, 2020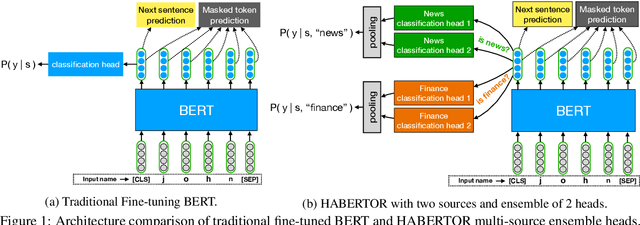
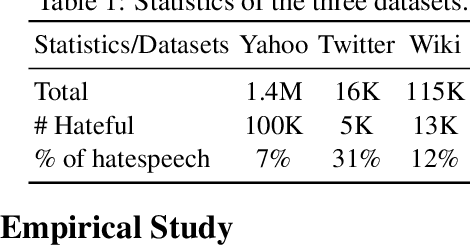

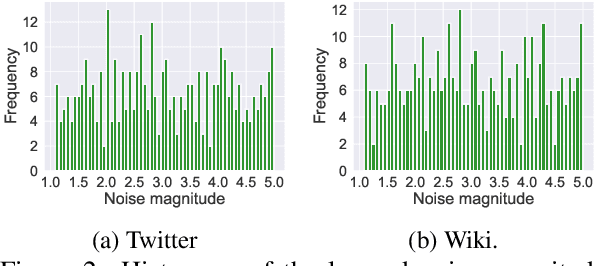
We present our HABERTOR model for detecting hatespeech in large scale user-generated content. Inspired by the recent success of the BERT model, we propose several modifications to BERT to enhance the performance on the downstream hatespeech classification task. HABERTOR inherits BERT's architecture, but is different in four aspects: (i) it generates its own vocabularies and is pre-trained from the scratch using the largest scale hatespeech dataset; (ii) it consists of Quaternion-based factorized components, resulting in a much smaller number of parameters, faster training and inferencing, as well as less memory usage; (iii) it uses our proposed multi-source ensemble heads with a pooling layer for separate input sources, to further enhance its effectiveness; and (iv) it uses a regularized adversarial training with our proposed fine-grained and adaptive noise magnitude to enhance its robustness. Through experiments on the large-scale real-world hatespeech dataset with 1.4M annotated comments, we show that HABERTOR works better than 15 state-of-the-art hatespeech detection methods, including fine-tuning Language Models. In particular, comparing with BERT, our HABERTOR is 4~5 times faster in the training/inferencing phase, uses less than 1/3 of the memory, and has better performance, even though we pre-train it by using less than 1% of the number of words. Our generalizability analysis shows that HABERTOR transfers well to other unseen hatespeech datasets and is a more efficient and effective alternative to BERT for the hatespeech classification.
Repulsive Attention: Rethinking Multi-head Attention as Bayesian Inference
Sep 20, 2020
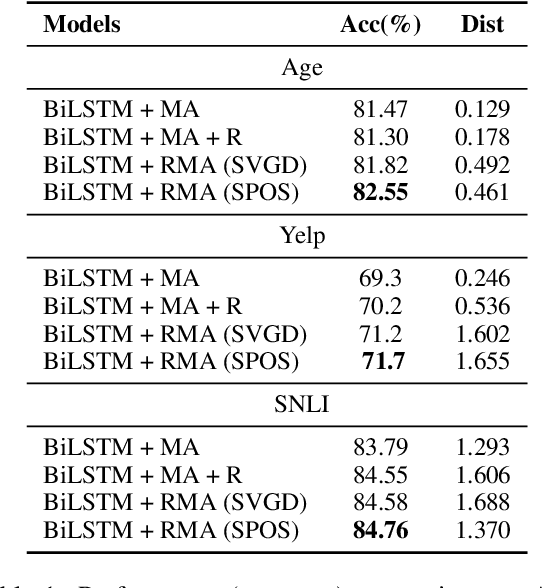

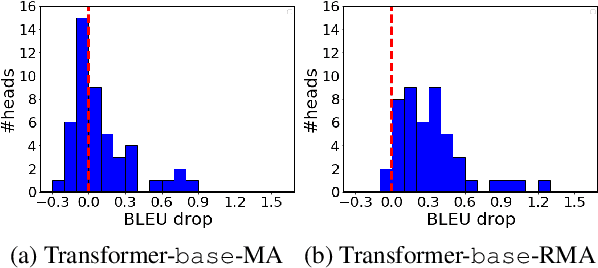
The neural attention mechanism plays an important role in many natural language processing applications. In particular, the use of multi-head attention extends single-head attention by allowing a model to jointly attend information from different perspectives. Without explicit constraining, however, multi-head attention may suffer from attention collapse, an issue that makes different heads extract similar attentive features, thus limiting the model's representation power. In this paper, for the first time, we provide a novel understanding of multi-head attention from a Bayesian perspective. Based on the recently developed particle-optimization sampling techniques, we propose a non-parametric approach that explicitly improves the repulsiveness in multi-head attention and consequently strengthens model's expressiveness. Remarkably, our Bayesian interpretation provides theoretical inspirations on the not-well-understood questions: why and how one uses multi-head attention. Extensive experiments on various attention models and applications demonstrate that the proposed repulsive attention can improve the learned feature diversity, leading to more informative representations with consistent performance improvement on various tasks.
Large-scale Gender/Age Prediction of Tumblr Users
Jan 02, 2020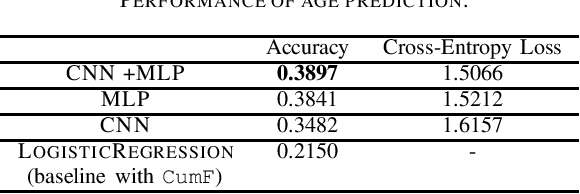



Tumblr, as a leading content provider and social media, attracts 371 million monthly visits, 280 million blogs and 53.3 million daily posts. The popularity of Tumblr provides great opportunities for advertisers to promote their products through sponsored posts. However, it is a challenging task to target specific demographic groups for ads, since Tumblr does not require user information like gender and ages during their registration. Hence, to promote ad targeting, it is essential to predict user's demography using rich content such as posts, images and social connections. In this paper, we propose graph based and deep learning models for age and gender predictions, which take into account user activities and content features. For graph based models, we come up with two approaches, network embedding and label propagation, to generate connection features as well as directly infer user's demography. For deep learning models, we leverage convolutional neural network (CNN) and multilayer perceptron (MLP) to prediction users' age and gender. Experimental results on real Tumblr daily dataset, with hundreds of millions of active users and billions of following relations, demonstrate that our approaches significantly outperform the baseline model, by improving the accuracy relatively by 81% for age, and the AUC and accuracy by 5\% for gender.
A Deep Structural Model for Analyzing Correlated Multivariate Time Series
Jan 02, 2020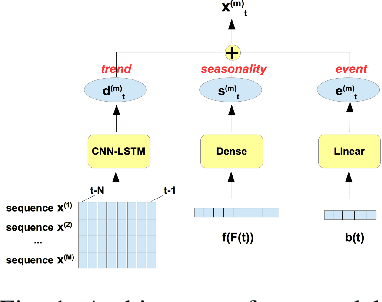
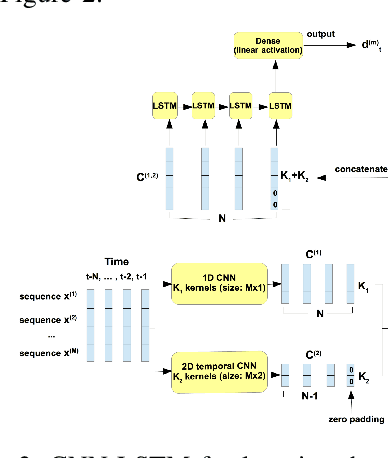
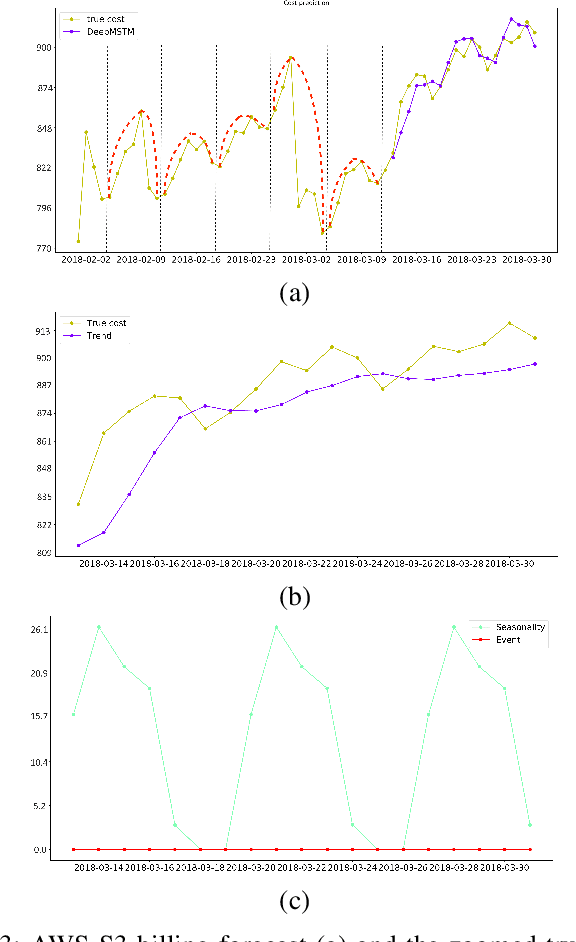
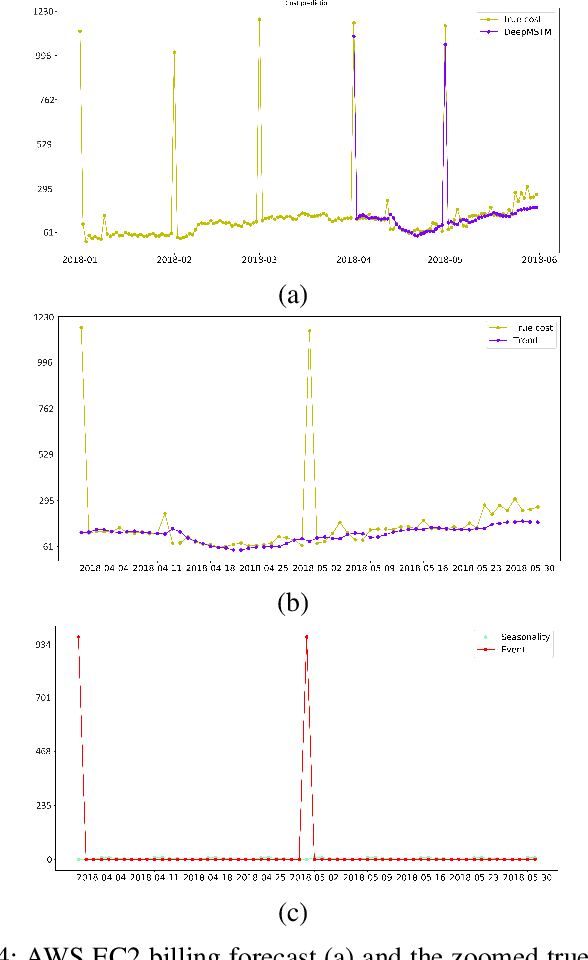
Multivariate time series are routinely encountered in real-world applications, and in many cases, these time series are strongly correlated. In this paper, we present a deep learning structural time series model which can (i) handle correlated multivariate time series input, and (ii) forecast the targeted temporal sequence by explicitly learning/extracting the trend, seasonality, and event components. The trend is learned via a 1D and 2D temporal CNN and LSTM hierarchical neural net. The CNN-LSTM architecture can (i) seamlessly leverage the dependency among multiple correlated time series in a natural way, (ii) extract the weighted differencing feature for better trend learning, and (iii) memorize the long-term sequential pattern. The seasonality component is approximated via a non-liner function of a set of Fourier terms, and the event components are learned by a simple linear function of regressor encoding the event dates. We compare our model with several state-of-the-art methods through a comprehensive set of experiments on a variety of time series data sets, such as forecasts of Amazon AWS Simple Storage Service (S3) and Elastic Compute Cloud (EC2) billings, and the closing prices for corporate stocks in the same category.
Deep Generative Models for Relational Data with Side Information
Jun 16, 2017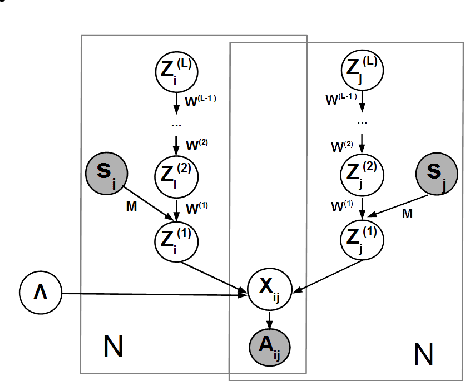
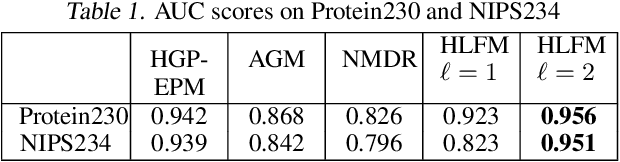
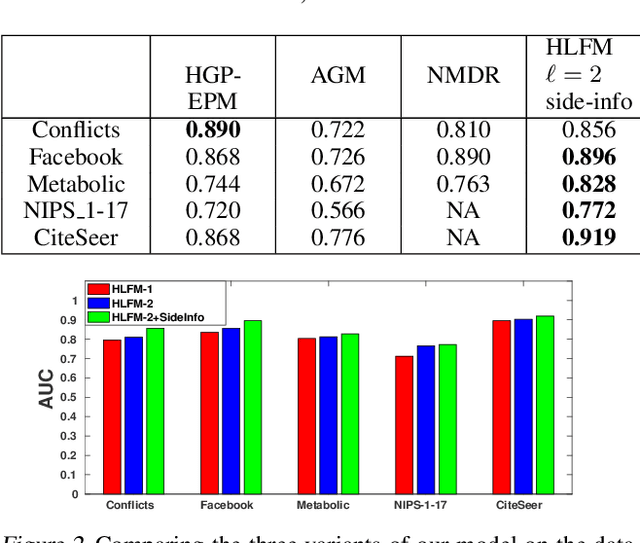
We present a probabilistic framework for overlapping community discovery and link prediction for relational data, given as a graph. The proposed framework has: (1) a deep architecture which enables us to infer multiple layers of latent features/communities for each node, providing superior link prediction performance on more complex networks and better interpretability of the latent features; and (2) a regression model which allows directly conditioning the node latent features on the side information available in form of node attributes. Our framework handles both (1) and (2) via a clean, unified model, which enjoys full local conjugacy via data augmentation, and facilitates efficient inference via closed form Gibbs sampling. Moreover, inference cost scales in the number of edges which is attractive for massive but sparse networks. Our framework is also easily extendable to model weighted networks with count-valued edges. We compare with various state-of-the-art methods and report results, both quantitative and qualitative, on several benchmark data sets.
Scalable Bayesian Non-Negative Tensor Factorization for Massive Count Data
Aug 18, 2015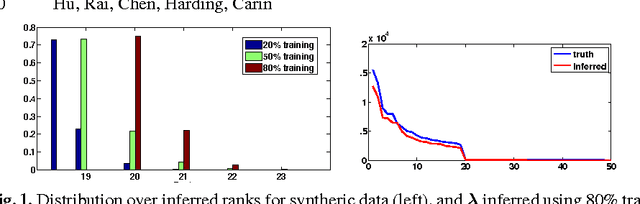
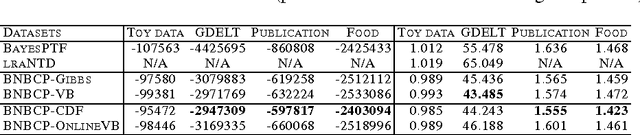
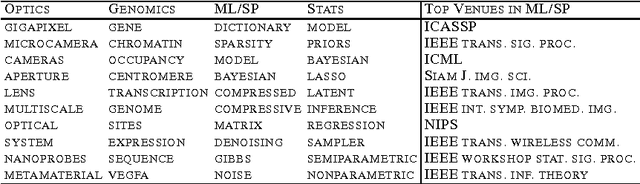
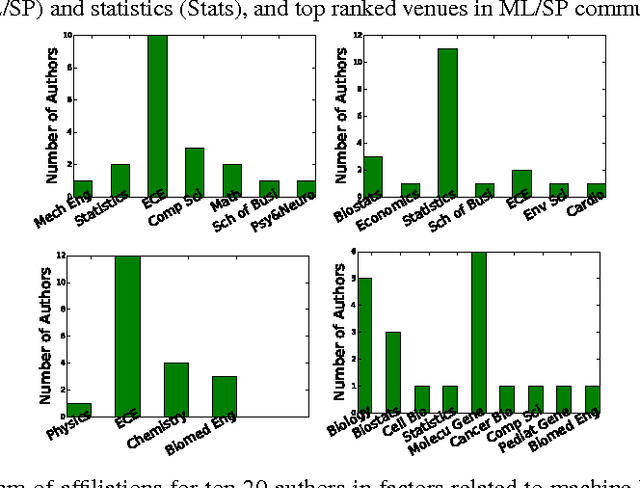
We present a Bayesian non-negative tensor factorization model for count-valued tensor data, and develop scalable inference algorithms (both batch and online) for dealing with massive tensors. Our generative model can handle overdispersed counts as well as infer the rank of the decomposition. Moreover, leveraging a reparameterization of the Poisson distribution as a multinomial facilitates conjugacy in the model and enables simple and efficient Gibbs sampling and variational Bayes (VB) inference updates, with a computational cost that only depends on the number of nonzeros in the tensor. The model also provides a nice interpretability for the factors; in our model, each factor corresponds to a "topic". We develop a set of online inference algorithms that allow further scaling up the model to massive tensors, for which batch inference methods may be infeasible. We apply our framework on diverse real-world applications, such as \emph{multiway} topic modeling on a scientific publications database, analyzing a political science data set, and analyzing a massive household transactions data set.